Knowledge Center
AI model architectuur en informatie

Als je in LM studio een aantal modellen hebt gedownload zie je hun (transformer) architectuur, de wijze waarom deze modellen functioneren, voorbeeld:
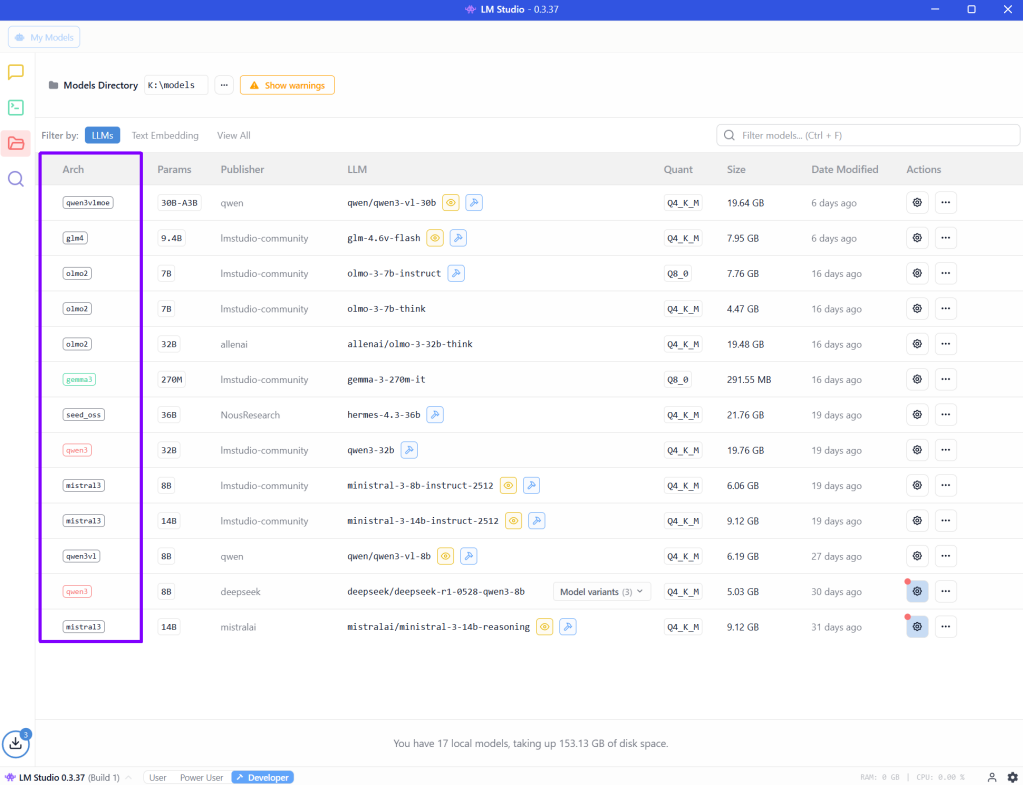
Hieronder staan een aantal architectuur beschrijvingen.
olmo2 #
Status: ouder / research-gericht
Organisatie: Allen Institute for AI (AI2)
Kenmerken:
- Klassieke decoder-only transformer
- Volledig open (trainingdata + recipes)
- Gericht op transparantie, niet op performance
Plus:
- Zeer “schoon” en eerlijk model
- Goed voor academisch gebruik
Min:
- Minder slim dan Qwen / Mistral / Gemma
- Slechtere instruction-following
- Geen state-of-the-art technieken
Niet meer competitief in 2025, behalve voor research.
seed_oss #
Status: niche / experimenteel
Organisatie: ByteDance (open subset)
Kenmerken:
- Instruction-tuned
- Gericht op OSS-community
- Geen brede adoptie
Plus:
- Redelijk licht
- Soms verrassend goed op chat
Min:
- Weinig tooling
- Onzeker lange termijn support
- Niet vision / tool-gericht
Interessant om te testen, geen daily driver.
glm4 #
Status: modern
Organisatie: Zhipu AI (China)
Kenmerken:
- Sterk instruction- en reasoning-gericht
- Lange context (32K–128K afhankelijk van variant)
- Goede multi-task performance
Plus:
- Sterk in logisch redeneren
- Goede balans kwaliteit / snelheid
- ChatGPT-achtig gedrag
Min:
- Minder populair in GGUF ecosystem
- Tooling soms achter op Qwen
Sterk alternatief voor Mistral / Qwen, vooral voor tekst.
gemma3 #
Status: zeer modern
Organisatie: Google DeepMind
Kenmerken:
- Efficiënte transformer
- Getraind met recente technieken
- Goede instruction-following
Plus:
- Zeer goede kwaliteit per parameter
- Rustig, consistent, netjes
- Efficiënt → snel op CPU/GPU
Min:
- Minder “brutaal slim” dan Qwen3
- Vision pas in specifieke varianten
Topmodel voor lokaal gebruik als je stabiliteit wilt.
mistral3 #
Status: topklasse (EU trots)
Organisatie: Mistral AI
Kenmerken:
- Native 32K context
- Zeer sterke instruction-tuning
- Tool- en JSON-vriendelijk
- Vision-ready varianten
Plus:
- Uitstekend in:
- JSON
- tools
- MCP
- function calling
- Snel in GGUF
- Zeer betrouwbaar
Min:
- Iets minder creatief dan Qwen
- Minder “kennisbreedte” dan GPT-achtige modellen
Perfect voor workflows (tools, vision, schema’s, code).
qwen3 #
Status: state-of-the-art
Organisatie: Alibaba
Kenmerken:
- Native long context (32K–128K)
- Zeer agressieve training
- Sterk in reasoning, code, vision, tools
Plus:
- Eén van de slimste open modellen
- Zeer goed in:
- redeneren
- code
- analyse
- Veel varianten (Think, Instruct, VL)
Min:
- Iets zwaarder / trager
- Kan “over-engineered” antwoorden geven
Top als je maximale intelligentie wilt.
qwen3vl #
Status: cutting-edge vision
Kenmerken:
- Vision-Language model
- Native multimodaal
- Bounding boxes, OCR, scene understanding
Plus:
- Véél beter dan LLaVA-achtige modellen
- Sterk voor :
- bounding boxes
- OCR
- vision-JSON schema’s
Min:
- Zwaarder
- Langzamer dan text-only
Beste keuze voor vision-POC’s lokaal.
qwen3vlmoe #
Status: experimenteel / high-end
Kenmerken:
- MoE (Mixture of Experts)
- Alleen deel van het model actief per token
Plus:
- Slimmer dan “normale” Qwen3-VL
- Betere schaalbaarheid
- Efficiënter bij grote modellen
Min:
- Complexer
- Niet altijd sneller in GGUF
- Soms instabieler lokaal
Technisch het meest geavanceerd, maar niet altijd praktisch.
Vergelijkingstabel van verschillende architecturen #

Wat zijn modellen met chat in hun naam? #
Bij llama2 modellen zie je bijvoorbeeld staan een “chat” toevoeging:
Llama-2-70B-GGUF
Llama-2-70B-Chat-GGUF
Je denk welllicht “waarom is dat?, met het model zonder chat kun je toch ook chatten?”
Zonder chat (bijv. Llama-2-7B-GGUF) #
Dit is het base / foundation model.
Eigenschappen:
- Getraind op grote hoeveelheden ruwe tekst
- Doel: volgende token voorspellen
- Geen speciale training voor:
- dialoog
- rollen (user / assistant)
- beleefdheid, veiligheid, consistentie
Je kunt ermee chatten, maar:
- Het antwoord kan:
- afdwalen
- van rol wisselen
- halverwege stoppen
- instructies negeren
- Je moet zelf prompt-engineering doen, bijv.:
User: ...
Assistant:of zelfs hele conversaties expliciet uitschrijven.
Dit type model is ideaal voor:
- fine-tuning
- embeddings
- code / tekstgeneratie zonder “praatgedrag”
- experimenten
Met chat (bijv. Llama-2-7B-Chat-GGUF) #
Dit is een instruction-tuned + chat-aligned model.
Extra training bovenop het base model:
- SFT (Supervised Fine-Tuning) op dialogen
- RLHF (Reinforcement Learning from Human Feedback)
- Gestructureerde conversaties:
- vraag → antwoord
- beleefd, behulpzaam, consistent
Resultaat:
- Begrijpt impliciet:
- “ik ben de assistant”
- “dit is een vraag”
- “ik moet netjes antwoorden”
- Veel minder prompt-werk nodig
- Gedraagt zich zoals ChatGPT-achtig gedrag
Dit type model is ideaal voor:
- chatbots
- assistenten
- Q&A
- tools zoals LM Studio / Ollama / text-UI’s
Waarom heet het dan chat en niet gewoon “zelfde model”? #
Omdat het echt een ander trainingsstadium is:
Base model
↓
Instruction tuning (SFT)
↓
RLHF / alignment
↓
Chat modelHet aantal parameters (7B, 13B) is hetzelfde,
maar de gewichten zijn anders.
| Eigenschap | Base | Chat |
|---|---|---|
| Kun je chatten? | ja | ja |
| Moet je rollen prompten? | ja | nee |
| Antwoordconsistentie | wisselend | stabiel |
| Veilig / beleefd | niet gegarandeerd | meestal |
| Geschikt voor chatbot | meh | ja |
Samenvatting #
Ja, met een model zonder chat kun je technisch chatten.
Nee, het is niet hetzelfde gedrag.
chat = “Ik ben expliciet getraind om een gesprekspartner te zijn”