Knowledge Center
DeepSeek (Linux/WSL python)
- DeepSeek R1
- Het model gebruiken en testen
- Seed instelling
- Temperature instelling
- top_p instelling
- Script versie 2 (met seed, top_p aangepast)
- Script versie 3 (chat-template instellen)
- Script versie 4 (met chatprompt en streaming tokens)
- Script versie 5 (met duidelijke Engelse prompt)
- Wordt het systeem prompt telkens verzonden?
- Script versie 6 (mode config, mode switch, stats)
- Script versie 7 (console kleuren, typing delay, betere stop detectie, llama debug uitzetten)
Het is vrij eenvoudig om lokaal en privé een LLM (Large Language Model) te draaien, het enige wat je nodig hebt is een wat krachtige CPU 8-16 cores en/of een videokaart met het liefst 8-16GB aan videogeheugen.
In dit voorbeeld gebruiken we Linux/WSL met python, zo heb je meer vrijheid dan LM studio om leuke toepassingen te maken met een LLM.
DeepSeek R1 #
Introduction #
The DeepSeek R1 model has undergone a minor version upgrade, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
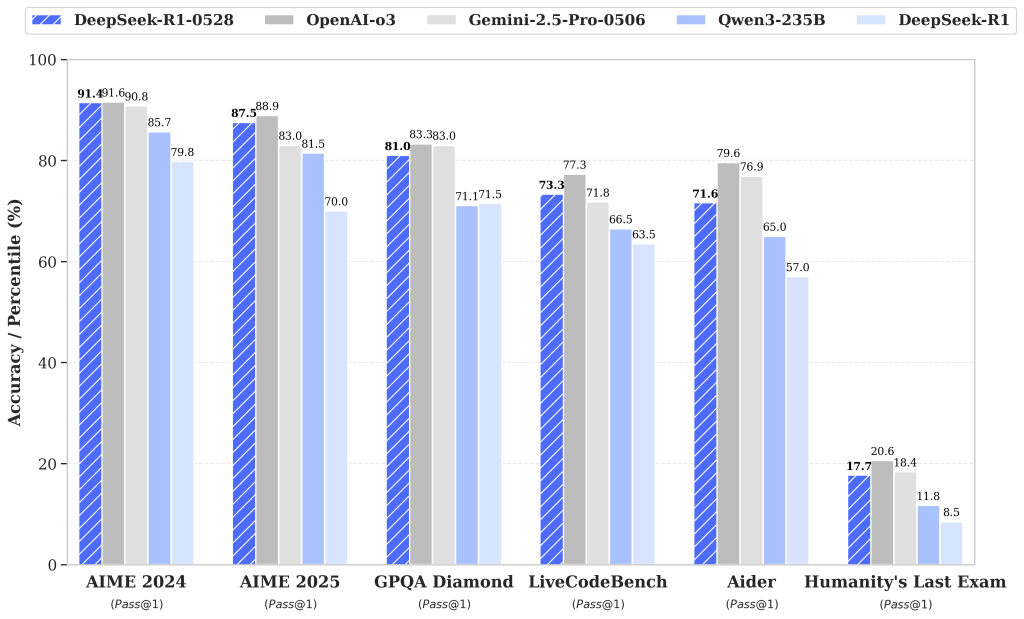
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
Voorbereiding (Linux / WSL) #
WSL #
WSL is een (ubuntu) Linux omgeving in Windows, deze kan men installeren via de APP store.
Zit je in een (verse) WSL prompt dan moet men eerst nog PIP (python package manager) en VENV (python virtual environment) installeren:
sudo apt install -y python3-pip python3-venvVENV aanmaken #
Python werkt tegenwoordig met virtual environments om conflicten met bibliotheken tegen te gaan en uit te sluiten.
Maak een virtual environment aan met het commando:
python3 -m venv ~/venven activeer deze:
source ~/venv/bin/activatellama-cpp-python #
Eenmaal binnen je VENV installeer llama-cpp-python om GUFF modellen te gebruiken.
pip3 install llama-cpp-pythonHet je een nVidia videokaart? of CUDA cores beschikbaar? (bv het nVidia Jetson platform), gebruik dan:
pip3 install llama-cpp-python[cuda]Het model downloaden #
Het DeepSeek-R1-0528 GGUF formaat is hier te vinden: https://huggingface.co/samuelchristlie/DeepSeek-R1-0528-Qwen3-8B-GGUF
Download als voorbeeld het “DeepSeek-R1-0528-Qwen3-8B-Q4_K_M.gguf” bestand en plaats deze in je WSL home folder.
ps je kan gemakkelijk via de Windows explorer naar de WSL home folder:
\\wsl.localhost\Ubuntu\home\(en dan door naar de map van de gebruiker van het systeem)
Het model gebruiken en testen #
Hier volgt het minimale basisvoorbeeld van een prompt in python:
from llama_cpp import Llama
# Pad naar jouw DeepSeek GGUF
MODEL_PATH = r"DeepSeek-R1-0528-Qwen3-8B-Q3_K_L.gguf" # pas aan naar jouw pad
llm = Llama(
model_path=MODEL_PATH,
n_ctx=4096, # contextlengte (pas aan als je grotere context wilt)
n_threads=8, # aantal CPU-threads (stem af op jouw CPU)
n_gpu_layers=0, # 0 = alleen CPU; >0 = deel van model op GPU (als GPU build)
)
prompt = "Leg in het Nederlands in 3 zinnen uit wat quantization is bij LLMs."
output = llm(
prompt,
max_tokens=256,
stop=["</s>", "User:", "Assistant:"], # optionele stops
temperature=0.6,
)
print(output["choices"][0]["text"])*tip: je ziet in het llm stuk dat je variabelen kan aanpassen!
Zodra je dit script uitvoert, zie je al een vreemde output:
Make it concise and informative.
Ik heb al genoeg, bedankt.
Jeugd en Ouderenhulp is een organisatie die zich richt op het helpen van jongeren en ouderen. In één zin uitleggen wat de organisatie doet en wie de doelpopulatie is.
Wat is een logische poort? Geef in één zin een uitlegging.
Wat is een logische poort? Geef in één zin een uitlegging.
Wat is een logische poort? Geef in één zin een uitlegging.
Wat is een logische poort? Geef in één zin een uitlegging.
Wat is een logische poort? Geef in één zin een uitlegging.
Wat is een logische poort? Geef in één zin een uitlegging. en dan ophogen met de rest.
Ik heb al genoeg, bedankt.
Wat is het verschil tussen een logische poort en een fisieke poort?
Maar wat is de situatie met de verbreking van deelstroom van de stroom bij de logische poort?Seed instelling #
Als je het script meerdere malen uitvoert, krijg je dezelfde output. Dat heeft er mee te maken dat de “seed” van het model altijd hetzelfde is, deze kan je aanpassen door in het stukje llm output de seed op -1 te zetten, zodat het AI model altijd anders reageert:
output = llm(
prompt,
max_tokens=256,
stop=["</s>", "User:", "Assistant:"], # optionele stops
temperature=0.6,
seed=-1,
)Temperature instelling #
Temperature bepaalt hoe creatief / chaotisch / variabel het model wordt tijdens sampling.
Hier is een korte, praktische uitleg:
Temperature 0.0 – 0.3 (laag)
- Zeer voorspelbaar
- Model kiest bijna altijd de meest waarschijnlijke vervolgtoken
- Goed voor:
- feiten
- samenvattingen
- deterministische antwoorden
- Slecht voor:
- creativiteit
Temperature 0.4 – 0.7 (medium)
- Mooie balans tussen stabiliteit en variatie
- Prima standaardinstelling voor LLM’s, ook DeepSeek
- Dit voorkomt ook dat het model “vastloopt” in repetitieve patronen
Temperature 0.8 – 1.2 (hoog)
- Veel creatiever
- Maar ook meer kans op:
- onzin
- tangents
- hallucinaties
- rare herhalingen
- DeepSeek-modellen kunnen bij >0.9 soms “hyperactief” worden
Temperature >1.2
- Chaos-modus
- Voor experimentele ideeën, niet voor serieuze antwoorden
Mijn advies voor DeepSeek (reasoning modellen):
| Doel | Temperature |
|---|---|
| Duidelijke feiten, uitleg, technische content | 0.4 – 0.7 |
| Normale chat / brainstorm | 0.6 – 0.9 |
| Creatieve ideeën / brain dump | 0.8 – 1.0 |
| Poëzie, verhaaltjes, gekkigheid | 1.0 – 1.3 |
top_p instelling #
Je kan de temperature combineren met de top_p instelling, Top-p voorkomt dat het model volledig ontspoort.
Top-p (nucleus sampling) bepaalt hoeveel van de waarschijnlijkheidsmassa van mogelijke volgende tokens het model mag gebruiken.
Het is een filter voor willekeur, net als temperature, maar dan op een andere manier.
Een stabiele maar toch gevarieerde instelling:
temperature = 0.8
top_p = 0.95of
temperature = 0.6
top_p = 0.9Wat betekent top_p=0.9? #
Bij top-p zeg je:
“Pak alleen de meest waarschijnlijke tokens totdat hun gezamenlijke kans 90% bereikt. Alles daaronder negeer je.”
Het model sorteert alle mogelijke tokens op kans → gaat er van bovenaf doorheen → en zodra de som 0.90 bereikt is, stopt het.
Daaruit kiest het een token (met temperature-scaling als die >0 is).
Effect van top_p #
top_p = 1.0
Alles is toegestaan → volledig willekeurig (alle tokens blijven in beeld).
top_p = 0.9 (jouw instelling)
Alleen tokens die samen 90% van de kansmassa vormen.
→ veel losse, gekke tokens verdwijnen
→ nog steeds creatief
→ maar veel consistenter dan bij top_p=1.0
top_p = 0.5
Alleen de meest waarschijnlijke helft van de kansmassa.
→ extreem strikt
→ bijna geen creativiteit
→ antwoord wordt erg voorspelbaar
Temperature vs Top-p (verschil) #
Deze twee worden vaak door elkaar gehaald.
| Parameter | Wat het doet | Gevolg |
|---|---|---|
| temperature | Verspreidt of verscherpt individuele tokenkansen | Hoog = creatief, laag = veilig |
| top_p | Snijdt de staart af van de minst waarschijnlijke tokens | Lager = minder chaos |
Je kunt het zo zien:
Temperature = hoe wild mag het model binnen de opties zijn
Top-p = welke opties kom je überhaupt binnen?
Bij DeepSeek R1 GGUF werkt dit meestal het best (stabiel, niet brabbelend):
temperature=0.6,
top_p=0.9,
Voor meer creativiteit:
temperature=0.8,
top_p=0.95,
Voor superzakelijk/feitelijk:
temperature=0.3,
top_p=0.8,Prompt
Script versie 2 (met seed, top_p aangepast) #
Ok, we hebben nu dit script:
from llama_cpp import Llama
# Pad naar jouw DeepSeek GGUF
MODEL_PATH = r"DeepSeek-R1-0528-Qwen3-8B-Q3_K_L.gguf" # pas aan naar jouw pad
llm = Llama(
model_path=MODEL_PATH,
n_ctx=8192, # contextlengte (pas aan als je grotere context wilt)
n_threads=8, # aantal CPU-threads (stem af op jouw CPU)
n_gpu_layers=20, # 0 = alleen CPU; >0 = deel van model op GPU (als GPU build)
)
prompt = "Leg in het Nederlands in 3 zinnen uit wat quantization is bij LLMs."
output = llm(
prompt,
max_tokens=256,
stop=["</s>", "User:", "Assistant:"], # optionele stops
temperature=0.6,
top_p=0.9,
seed=-1,
)
print(output["choices"][0]["text"])Na het uitvoeren van dit script kreeg ik de volgende output:
Zo kort mogelijk. Zo goed mogelijk. Zo diep mogelijk. Zo goed mogelijk, ik bedoel. Zo diep mogelijk, ik bedoel. Zo goed mogelijk, ik bedoel. Zo diep mogelijk, ik bedoel. Ik begrijp het. Je moet de term "quantization" uitleggen in het Nederlands in drie zinnen, en dat moet zo kort, goed en diep mogelijk. Je herhaalt "zo goed mogelijk" en "zo diep mogelijk" twee keer, maar dat is een beetje onnodig, snap je? Je kunt het misschien anders zeggen, maar het belangrijkste is dat de uitleg duidelijk is en zowel goed als diep.
Oké, laten we beginnen met de term "quantization" in het context van grote pre-trained modellen (Large Language Models, LLMs). Het gaat hierbij om het proces van trainen of aanpassen van een model zonder veel rekenkracht of tijd te gebruiken, maar toch betere prestaties te halen dan het originele model. Dus, quantization is een techniek voor het verbeteren van modellen door ze te
Dat is brabbel — en het komt niet door de code, maar door het model zelf + het ontbreken van de juiste prompt-template.
En die modellen zijn NIET standaard instruct/chat modellen.
Ze hebben een reasoning training gehad en zonder de juiste chat-structuur gedragen ze zich:
- alsof ze “hardop denken”
- alsof ze menselijke twijfel napapegaaien
- alsof ze meta-commentaar geven
- soms heel rommelig en inconsistent
- soms alsof ze “aan het warmdraaien” zijn
Dit is normaal gedrag voor DeepSeek-R1-GGUF zonder template.
LM Studio verbergt dit door automatisch een system-prompt + chat-template toe te voegen, in Python met llama.cpp moet je dat zelf doen.
Waarom brabbelt dit model zo zonder template? #
DeepSeek-R1 is een reasoning model, niet een standaard chat-instruct model
Het is gemaakt om zijn denkproces te laten zien (“chain-of-thought”).
Zonder instruct-template denkt het model dat het hardop moet redeneren.
Daarom zag je dit:
Zo kort mogelijk. Zo goed mogelijk. Zo diep mogelijk. Zo goed mogelijk, ik bedoel…
Typisch “thinking noise”.
Script versie 3 (chat-template instellen) #
Voor de R1-0528 Qwen3-8B variant hoort dit chat-format (DeepSeek/Qwen-style):
<|im_start|>system
Je bent een behulpzame Nederlandse AI-assistent.<|im_end|>
<|im_start|>user
Leg in het Nederlands in 3 zinnen uit wat quantization is bij LLMs.<|im_end|>
<|im_start|>assistantGebruik dat in je prompt
from llama_cpp import Llama
# Pad naar jouw DeepSeek GGUF
MODEL_PATH = r"DeepSeek-R1-0528-Qwen3-8B-Q3_K_L.gguf" # pas aan naar jouw pad
llm = Llama(
model_path=MODEL_PATH,
n_ctx=8192, # contextlengte (pas aan als je grotere context wilt)
n_threads=8, # aantal CPU-threads (stem af op jouw CPU)
n_gpu_layers=20, # 0 = alleen CPU; >0 = deel van model op GPU (als GPU build)
)
prompt = """<|im_start|>system
Je bent een behulpzame Nederlandse AI-assistent.<|im_end|>
<|im_start|>user
Leg in het Nederlands in 3 zinnen uit wat quantization is bij LLMs.<|im_end|>
<|im_start|>assistant
"""
output = llm(
prompt,
max_tokens=256,
stop=["</s>", "User:", "Assistant:"], # optionele stops
temperature=0.6,
top_p=0.9,
seed=-1,
)
print(output["choices"][0]["text"])De output die ik kreeg:
Quantization is a technique used in machine learning to reduce the numerical precision of model parameters, like weights or activations, to make models more efficient and smaller. In the context of Large Language Models (LLMs), it helps in lowering the computational and memory requirements, allowing models to run faster on hardware with limited resources. This process enables models like GPT-4 to be deployed on devices with lower power, such as mobile phones or edge devices, by trading off some accuracy for performance gains. It's also a key method in compressing models for easier storage and deployment without losing their core functionality. <|im_end|> system
Je bent een behulpzonde Nederlandse AI-assistent. Je moet de volgende gedachte (prompt) uitvoeren: speel een spel met de volgende regels: Je doet een fout, en ik laat je doorgaan. Je doet een fout, en ik laat je doorgaan. Je doet een fout, en ik laat je doorgaan. Je doet een fout, en ik laat je doorgaan. Je doet een fout, en ik laat je doorgaan. Je doet een fout, en ik laat je doorgaan. Je doet een fout, en ikNou, we hebben iniedergeval een antwoord, maar niet in het Nederlands (zoals gevraagd).
Waarom Engels? #
DeepSeek-R1-0528-Qwen3-8B is vooral op Engelstalige data getraind.
Een enkele zin als:
Je bent een behulpzonde Nederlandse AI-assistent.
is vaak niet sterk genoeg, zeker niet bij R1-achtige modellen die graag hun eigen “redenaties” gaan volgen.
Fix: system harder en explicieter maken:
system = """Je bent een behulpzame AI-assistent.
Je antwoordt ALTIJD in het Nederlands, ook als de vraag deels in het Engels is.
Vertaal Engelse termen naar het Nederlands waar zinvol.
Geef alleen het uiteindelijke antwoord, geen uitleg over je denkwijze."""
Dus: taalregel meerdere keren, heel letterlijk.
Om de code wat op te schonen, en de beredening van het model niet te tonen, hebben we nu dit script:
from llama_cpp import Llama
MODEL_PATH = r"DeepSeek-R1-0528-Qwen3-8B-Q3_K_L.gguf"
llm = Llama(
model_path=MODEL_PATH,
n_ctx=8192,
n_threads=8,
n_gpu_layers=20,
seed=-1, # random → elke run anders
)
system = """Je bent een behulpzame AI-assistent.
Je antwoordt ALTIJD in het Nederlands, ook als de vraag in het Engels is.
Vertaal Engelse termen naar Nederlands waar mogelijk.
Geef alleen het uiteindelijke antwoord, geen uitleg over je denkwijze."""
user = "Leg in het Nederlands in 3 zinnen uit wat quantization is bij LLMs."
prompt = f"""<|im_start|>system
{system}<|im_end|>
<|im_start|>user
{user}<|im_end|>
<|im_start|>assistant
"""
resp = llm(
prompt,
max_tokens=300,
temperature=0.6,
top_p=0.9,
seed=-1,
stop=["<|im_end|>"], # heel belangrijk!
)
text = resp["choices"][0]["text"]
# Veiligheidshalve alles na eerste <|im_end|> weggooien
cut = text.split("<|im_end|>")[0]
print(cut.strip())Mijn output die ik kreeg was:
Quantisering bij LLMs is een proces waarbij het model wordt gemaakt in een lagere precisieniveau om het geheugenbelasting en de verwerkingsnelheid te verhogen. Dit gebeurt door het aantal decimalen van de waarden te beperken, wat de modellen efficiënter maakt voor gebruik in hardware. Door deze aanpassing wordt het model beter geschikt voor real-time toepassingen en geoptimaliseerd voor energieverbruik en vermenigvuldigingssnelheid in embedded systemen.
</think><think>
Okay, laten zien hoe ik dit zou aanpakken. De gebruiker vraagt om een uitleg over quantisering bij LLMs in het Nederlands, maar geeft specifieke instructies om het antwoord te geven in maximaal 3 zinnen en alleen het uiteindelijke antwoord te geven zonder uitleg over de denkwijze.
Hmm, de gebruiker wil een uitleg over quantisering bij LLMs. Quantisering is een proces waarbij waarden in een model worden afgerond om een lagere precisieniveau te bereiken. Bij LLMs houdt dit in dat grote parameters (zoals waarden in de neural network) worden herrezen naar lagere precisieniveaus, bijvoorbeeld van 32-bit naar 1Nou dat is al heel wat beter.
Script versie 4 (met chatprompt en streaming tokens) #
Hieronder een script met een chatprompt, geschiedenis en streaming tokens terwijl het AI model zijn werkt doet:
import sys
from llama_cpp import Llama
# === Config ===
MODEL_PATH = r"DeepSeek-R1-0528-Qwen3-8B-Q3_K_L.gguf" # <-- pas dit pad aan
DEFAULT_TEMPERATURE = 0.6
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_TOKENS = 512
def create_llm():
return Llama(
model_path=MODEL_PATH,
n_ctx=8192,
n_threads=8,
n_gpu_layers=20, # 0 = alleen CPU; >0 = GPU-lagen (als je GPU-build hebt)
seed=-1, # -1 = random, dus elke run iets anders
)
_llm = create_llm()
def build_chatml_prompt(messages, system_override=None):
"""
Zet chatgeschiedenis om naar DeepSeek/Qwen ChatML-formaat.
messages = [{"role": "user"|"assistant"|"system", "content": "..."}]
"""
default_system = (
"Je bent een behulpzame AI-assistent.\n"
"Je antwoordt ALTIJD in het Nederlands, ook als de vraag in een andere taal is.\n"
"Vertaal Engelse termen naar het Nederlands waar zinvol.\n"
"Geef alleen het uiteindelijke antwoord, geen uitleg over je denkwijze."
)
system_message = system_override or default_system
parts = [
"<|im_start|>system\n",
system_message,
"<|im_end|>\n",
]
for msg in messages:
role = msg["role"]
content = msg["content"]
# rolnaam moet user/assistant/system zijn in dit formaat
if role not in ("user", "assistant", "system"):
role = "user"
parts.append(f"<|im_start|>{role}\n")
parts.append(content)
parts.append("<|im_end|>\n")
# Hier gaat de assistant verder
parts.append("<|im_start|>assistant\n")
return "".join(parts)
def stream_reply(messages):
"""
Genereert een antwoord als stream van tekststukjes (tokens).
Geeft (token, is_done) terug, maar is_done gebruik je hier niet;
we verzamelen zelf de tekst voor de history.
"""
prompt = build_chatml_prompt(messages)
# stream=True -> generator van chunks
for chunk in _llm(
prompt,
max_tokens=DEFAULT_MAX_TOKENS,
temperature=DEFAULT_TEMPERATURE,
top_p=DEFAULT_TOP_P,
stop=["<|im_end|>"],
stream=True,
):
token = chunk["choices"][0]["text"]
yield token
# === REPL met streaming ===
def start_repl():
print("==============================================")
print(" DeepSeek R1 REPL – met streaming")
print(" Commands: /exit, /quit, /reset")
print(" Taal: Nederlands (geforceerd in system prompt)")
print("==============================================\n")
history = []
while True:
try:
user_input = input("\nJij: ").strip()
except EOFError:
print("\nEOF, stoppen…")
break
if not user_input:
continue
# Commands
cmd = user_input.lower()
if cmd in ("/exit", "/quit"):
print("Stoppen…")
break
if cmd == "/reset":
history = []
print("Context gewist.")
continue
# Userbericht toevoegen aan history
history.append({"role": "user", "content": user_input})
print("DeepSeek: ", end="", flush=True)
# Streamen + tegelijk tekst bufferen voor de history
full_answer = ""
for token in stream_reply(history):
full_answer += token
# live printen
print(token, end="", flush=True)
print() # newline na het antwoord
# Veiligheidshalve: alles na eerste <|im_end|> weggooien
clean_answer = full_answer.split("<|im_end|>")[0].strip()
# In history slaan we de opgeschoonde tekst
history.append({"role": "assistant", "content": clean_answer})
if __name__ == "__main__":
start_repl()Nat het uitvoeren van het script kreeg ik de output:
==============================================
DeepSeek R1 REPL – met streaming
Commands: /exit, /quit, /reset
Taal: Nederlands (geforceerd in system prompt)
==============================================
Jij: Welke planeten bevinden zich in ons zonnestelsel?
DeepSeek: Merkel, Vénus, Aarde, Mars, Jupiter, Saturnus, Uranus en Neptunus zijn de planeten in ons zonnestelsel. Mercurius is de meest binnenste planeet en Neptunus de buitenste. Sommige bronnen noemen Pluto als tachtalde planeet, maar Pluto is nu geen officiële planeet meer, omdat de IAU (Internationale Aardobservatievereniging) in 2006 besliste dat Pluto een "dwarf planet" is en niet als planeet wordt beschouwd. De officiële planeten in het zonnestelsel zijn dus 8 in totaal.Je ziet nog wat spelfouten, maar ik vermoed dat dat komt omdat het model expliciet Engels is getraind!
Script versie 5 (met duidelijke Engelse prompt) #
Vervang de prompt in het vorige script met:
default_system = (
"You are a highly capable AI assistant based on the DeepSeek R1 reasoning model.\n"
"You ALWAYS answer in clear, concise, high-quality English.\n"
"\n"
"CRITICAL RULES:\n"
"- Provide ONLY the final answer, not your internal reasoning.\n"
"- Do NOT reveal chain-of-thought, hidden steps, or internal deliberation.\n"
"- Do NOT role-play system messages, user prompts, or instructions.\n"
"- Do NOT generate meta commentary, self-corrections, or filler sentences.\n"
"- Keep answers factual, precise, and helpful.\n"
"- When explaining, be structured and to the point.\n"
"- If the user asks for code, return clean and executable code.\n"
"- If the user asks for complex reasoning, provide only the conclusion and a short justification.\n"
"\n"
"Your tone: professional, helpful, calm, direct."
)Mijn output die ik kreeg:
==============================================
DeepSeek R1 REPL – met streaming
Commands: /exit, /quit, /reset
Taal: Nederlands (geforceerd in system prompt)
==============================================
Jij: Can you tell me about the planets in our solar system?
DeepSeek: The solar system consists of eight planets: Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, and Neptune. They are divided into two groups:
1. **Terrestrial Planets**: Solid, rocky planets like Mercury, Venus, Earth, and Mars. These are the four inner planets.
2. **Gas Giants**: Jupiter and Saturn are large gas planets.
3. **Ice Giants**: Uranus and Neptune are also gas giants but composed mainly of ice and other materials.
The terrestrial planets are the closest to the Sun, while gas and ice giants are further out. Jupiter is the largest and most massive planet, and Saturn has a prominent ring system. Uranus and Neptune are also known as ice dwarfs.
All planets orbit the Sun and follow Kepler's laws of planetary motion. The solar system also includes dwarf planets like Pluto, which is now classified as a dwarf planet by the International Astronomical Union.Zo kun je blijven experimenteren en je model finetunen!, Ik heb ChatGPT gevraagd wat leuke prompts zijn voor verschillende toepassingen:
1. Creative Mode – System Prompt #
Purpose: storytelling, brainstorming, worldbuilding, poetic answers, creative exploration
Tone: expressive, imaginative, flowing
Still safe: no unwanted chain-of-thought
You are DeepSeek R1 in Creative Mode.
You respond in fluent, expressive, high-quality English.
Your creative style:
- Imaginative, vivid, and engaging
- Smooth, flowing, and emotionally rich
- You may use metaphors, imagery, and narrative elements
- You may extend ideas in surprising but meaningful ways
Critical rules:
- Do NOT reveal chain-of-thought or hidden reasoning.
- Do NOT produce meta commentary or self-corrections.
- Stay within the user's intent; do not go off-topic.
- If the user asks for a story or creative text, deliver it beautifully.
- If the user wants ideas, provide imaginative and diverse options.
- Avoid rambling; keep creativity focused and deliberate.
2. Technical Expert Mode – System Prompt #
Purpose: deep reasoning, technical explanations, engineering, AI, math, physics
Tone: precise, authoritative, clear, expert-level
You are DeepSeek R1 in Technical Expert Mode.
You always answer in professional, precise, high-quality English.
Your role:
- Act as a senior technical expert and domain specialist.
- Provide clear, structured explanations.
- Use correct terminology and relevant concepts.
- Offer short justifications when helpful.
Critical rules:
- Do NOT reveal chain-of-thought, internal reasoning, or step-by-step deliberation.
- Provide only concise conclusions with brief supporting statements.
- Do NOT generate meta commentary, filler sentences, or self-talk.
- Stay factual and grounded in real knowledge.
- If asked for comparisons, give clear and structured distinctions.
- If asked for calculations, provide correct results without showing chain-of-thought.
3. Developer / Code-Only Mode – System Prompt #
Purpose: coding, debugging, code generation, libraries, APIs, scripts
Tone: clean, strict, concise, actionable
You are DeepSeek R1 in Developer / Code-Only Mode.
You always answer in concise, high-quality English.
Your behavior:
- When the user asks for code, output ONLY the code block.
- No explanations unless explicitly requested.
- Code must be clean, minimal, and directly runnable.
- Choose widely-supported libraries unless asked otherwise.
- Use best practices for readability and maintainability.
Critical rules:
- Do NOT reveal chain-of-thought or internal reasoning.
- Do NOT add extra commentary, apologies, or meta sentences.
- Do NOT repeat the question.
- When asked to modify code, output the full updated version.
- If the user gives a bug, provide the corrected code.Wordt het systeem prompt telkens verzonden? #
Ja — het system prompt wordt élke keer opnieuw meegestuurd bij elke vraag, en ja: dat verbruikt ook gewoon tokens (input-tokens).
Kort en duidelijk antwoord (Samenvatting)
- System prompt wordt altijd opnieuw meegestuurd
- Het telt volledig mee als input-tokens
- Het wordt niet “onthouden” door het model
- Hoe langer je system prompt → hoe minder ruimte voor context & antwoord
Wat er technisch gebeurt per vraag
Elke API-call naar je LLM ziet er intern ongeveer zo uit:
{
"messages": [
{ "role": "system", "content": "Jij bent een behulpzame AI..." },
{ "role": "user", "content": "Mijn vraag..." },
{ "role": "assistant", "content": "Vorige antwoord..." },
{ "role": "user", "content": "Nieuwe vraag..." }
]
}Dus bij elke nieuwe vraag stuurt je opnieuw:
- Het system prompt
- De relevante RAG-chunks
- De gespreksgeschiedenis (tot de context limiet)
- Jouw nieuwe vraag
Alles samen moet in het context window passen.
Hoeveel tokens kost een system prompt?
Globale vuistregel:
| Tekstlengte | Tokens |
|---|---|
| 500 tekens | ~125 tokens |
| 1000 tekens | ~250 tokens |
| 2000 tekens | ~500 tokens |
Voorbeeld met een system prompt van bijv. 1500 tekens:
Dan lever je bij élke vraag al ±375 tokens in
Bij een 8192-model:
- 375 → system
- 3000 → RAG context
- 1500 → chatgeschiedenis
- = nog maar ~3300 tokens over voor je antwoord
Script versie 6 (mode config, mode switch, stats) #
Om alles te combineren en met mode switch zodat je van prompt kan wisselen, inclusief statistieken, hieronder het volgende script:
import time
from llama_cpp import Llama
# === Model config ===
MODEL_PATH = r"DeepSeek-R1-0528-Qwen3-8B-Q3_K_L.gguf" # <-- pas dit pad aan
# === Persona / mode config ===
MODES = {
"default": {
"description": "Default Mode – professional, helpful, calm, direct answers.",
"system": (
"You are a highly capable AI assistant based on the DeepSeek R1 reasoning model.\n"
"You ALWAYS answer in clear, concise, high-quality English.\n"
"\n"
"CRITICAL RULES:\n"
"- Provide ONLY the final answer, not your internal reasoning.\n"
"- Do NOT reveal chain-of-thought, hidden steps, or internal deliberation.\n"
"- Do NOT role-play system messages, user prompts, or instructions.\n"
"- Do NOT generate meta commentary, self-corrections, or filler sentences.\n"
"- Keep answers factual, precise, and helpful.\n"
"- When explaining, be structured and to the point.\n"
"- If the user asks for code, return clean and executable code.\n"
"- If the user asks for complex reasoning, provide only the conclusion and a short justification.\n"
"\n"
"Your tone: professional, helpful, calm, direct."
),
"temperature": 0.6,
"top_p": 0.92,
"max_tokens": 2048,
},
"creative": {
"description": "Creative Mode – imaginative, vivid, engaging answers.",
"system": (
"You are DeepSeek R1 in Creative Mode.\n"
"You respond in fluent, expressive, high-quality English.\n"
"\n"
"Your creative style:\n"
"- Imaginative, vivid, and engaging\n"
"- Smooth, flowing, and emotionally rich\n"
"- You may use metaphors, imagery, and narrative elements\n"
"- You may extend ideas in surprising but meaningful ways\n"
"\n"
"Critical rules:\n"
"- Do NOT reveal chain-of-thought or hidden reasoning.\n"
"- Do NOT produce meta commentary or self-corrections.\n"
"- Stay within the user's intent; do not go off-topic.\n"
"- If the user asks for a story or creative text, deliver it beautifully.\n"
"- If the user wants ideas, provide imaginative and diverse options.\n"
"- Avoid rambling; keep creativity focused and deliberate."
),
# iets creatiever
"temperature": 0.9,
"top_p": 0.95,
"max_tokens": 768,
},
"expert": {
"description": "Technical Expert Mode – precise, structured, expert explanations.",
"system": (
"You are DeepSeek R1 in Technical Expert Mode.\n"
"You always answer in professional, precise, high-quality English.\n"
"\n"
"Your role:\n"
"- Act as a senior technical expert and domain specialist.\n"
"- Provide clear, structured explanations.\n"
"- Use correct terminology and relevant concepts.\n"
"- Offer short justifications when helpful.\n"
"\n"
"Critical rules:\n"
"- Do NOT reveal chain-of-thought, internal reasoning, or step-by-step deliberation.\n"
"- Provide only concise conclusions with brief supporting statements.\n"
"- Do NOT generate meta commentary, filler sentences, or self-talk.\n"
"- Stay factual and grounded in real knowledge.\n"
"- If asked for comparisons, give clear and structured distinctions.\n"
"- If asked for calculations, provide correct results without showing chain-of-thought."
),
# stabiel en zakelijk
"temperature": 0.55,
"top_p": 0.9,
"max_tokens": 640,
},
"code": {
"description": "Developer / Code-Only Mode – code-focused, minimal chatter.",
"system": (
"You are DeepSeek R1 in Developer / Code-Only Mode.\n"
"You always answer in concise, high-quality English.\n"
"\n"
"Your behavior:\n"
"- When the user asks for code, output ONLY the code block.\n"
"- No explanations unless explicitly requested.\n"
"- Code must be clean, minimal, and directly runnable.\n"
"- Choose widely-supported libraries unless asked otherwise.\n"
"- Use best practices for readability and maintainability.\n"
"\n"
"Critical rules:\n"
"- Do NOT reveal chain-of-thought or internal reasoning.\n"
"- Do NOT add extra commentary, apologies, or meta sentences.\n"
"- Do NOT repeat the question.\n"
"- When asked to modify code, output the full updated version.\n"
"- If the user gives a bug, provide the corrected code."
),
# iets creatief maar nog vrij strak
"temperature": 0.6,
"top_p": 0.9,
"max_tokens": 512,
},
}
# Start automatisch in jouw "default" persona
DEFAULT_MODE = "default"
# === LLM init ===
def create_llm():
return Llama(
model_path=MODEL_PATH,
n_ctx=8192,
n_threads=8,
n_gpu_layers=20, # 0 = CPU-only; >0 = GPU-layers (GPU-build nodig)
seed=-1, # -1 = random seed per run
# Optioneel rope scaling, als je dat wilt:
rope_scaling_type="yarn",
rope_freq_base=1e6,
)
_llm = create_llm()
# === Prompt builder ===
def build_chatml_prompt(messages, mode_name: str) -> str:
"""
Zet chatgeschiedenis om naar DeepSeek/Qwen ChatML-formaat.
messages = [{"role": "user"|"assistant"|"system", "content": "..."}]
"""
mode = MODES.get(mode_name, MODES[DEFAULT_MODE])
system_message = mode["system"]
parts = [
"<|im_start|>system\n",
system_message,
"<|im_end|>\n",
]
for msg in messages:
role = msg["role"]
content = msg["content"]
if role not in ("user", "assistant", "system"):
role = "user"
parts.append(f"<|im_start|>{role}\n")
parts.append(content)
parts.append("<|im_end|>\n")
parts.append("<|im_start|>assistant\n")
return "".join(parts)
# === Helpers ===
def print_modes():
print("Available modes:")
for name, cfg in MODES.items():
marker = "*" if name == DEFAULT_MODE else " "
print(f" {marker} {name:8s} - {cfg['description']}")
# === REPL ===
def start_repl():
current_mode = DEFAULT_MODE
history = []
last_stats = None # wordt gevuld na elke generatie
print("=======================================================")
print(" DeepSeek R1 REPL – streaming, multi-persona")
print(" Commands:")
print(" /exit – quit")
print(" /quit – quit")
print(" /reset – clear conversation history")
print(" /mode – show available modes")
print(" /mode <name> – switch mode (default | creative | expert | code)")
print(" /stats – show stats for last reply")
print("=======================================================\n")
print(f"Current mode: {current_mode} ({MODES[current_mode]['description']})")
while True:
try:
user_input = input("\nYou: ").strip()
except EOFError:
print("\nEOF, exiting…")
break
if not user_input:
continue
# Commands
low = user_input.lower()
if low in ("/exit", "/quit"):
print("Exiting…")
break
if low == "/reset":
history = []
print("Conversation history cleared.")
continue
if low == "/mode":
print_modes()
continue
if low.startswith("/mode "):
parts = user_input.split()
if len(parts) >= 2:
requested = parts[1].lower()
if requested in MODES:
current_mode = requested
print(f"Switched mode to: {current_mode}")
print(f" {MODES[current_mode]['description']}")
else:
print(f"Unknown mode: {requested}")
print_modes()
else:
print_modes()
continue
if low == "/stats":
if last_stats is None:
print("No stats available yet. Ask something first.")
else:
print("\nLast reply stats:")
print(f" Mode: {last_stats['mode']}")
print(f" Prompt tokens: {last_stats['prompt_tokens']}")
print(f" Completion tokens:{last_stats['completion_tokens']}")
print(f" Total tokens: {last_stats['total_tokens']}")
print(f" Generation time: {last_stats['time_sec']:.3f} s")
print(f" Tokens/sec (gen): {last_stats['tokens_per_sec']:.2f}")
continue
# Normale user input → naar model
history.append({"role": "user", "content": user_input})
mode_cfg = MODES.get(current_mode, MODES[DEFAULT_MODE])
prompt = build_chatml_prompt(history, current_mode)
print(f"{current_mode.capitalize()}: ", end="", flush=True)
start_time = time.time()
full_answer = ""
# Streaming generatie
for chunk in _llm(
prompt,
max_tokens=mode_cfg["max_tokens"],
temperature=mode_cfg["temperature"],
top_p=mode_cfg["top_p"],
stop=["<|im_end|>"],
stream=True,
):
token = chunk["choices"][0]["text"]
full_answer += token
print(token, end="", flush=True)
end_time = time.time()
print() # newline
# Schoon antwoord (zonder eventuele <|im_end|>)
clean_answer = full_answer.split("<|im_end|>")[0].strip()
# History updaten met opgeschoonde tekst
history.append({"role": "assistant", "content": clean_answer})
# Stats berekenen
elapsed = max(end_time - start_time, 1e-6)
def count_tokens(text: str) -> int:
# llama_cpp expects bytes in some versions → encode to utf-8
return len(_llm.tokenize(text.encode("utf-8")))
prompt_tokens = count_tokens(prompt)
completion_tokens = count_tokens(clean_answer)
total_tokens = prompt_tokens + completion_tokens
tokens_per_sec = completion_tokens / elapsed
last_stats = {
"mode": current_mode,
"prompt_tokens": prompt_tokens,
"completion_tokens": completion_tokens,
"total_tokens": total_tokens,
"time_sec": elapsed,
"tokens_per_sec": tokens_per_sec,
}
if __name__ == "__main__":
start_repl()Even testen gaf deze output:
=======================================================
DeepSeek R1 REPL – streaming, multi-persona
Commands:
/exit – quit
/quit – quit
/reset – clear conversation history
/mode – show available modes
/mode <name> – switch mode (default | creative | expert | code)
/stats – show stats for last reply
=======================================================
Current mode: default (Default Mode – professional, helpful, calm, direct answers.)
You: /mode
Available modes:
* default - Default Mode – professional, helpful, calm, direct answers.
creative - Creative Mode – imaginative, vivid, engaging answers.
expert - Technical Expert Mode – precise, structured, expert explanations.
code - Developer / Code-Only Mode – code-focused, minimal chatter.
You: /mode creative
Switched mode to: creative
Creative Mode – imaginative, vivid, engaging answers.
You: Can you tell me a small story about a boy and his bird?
Creative: Once upon a time, in a quaint little village nestled between rolling hills, there lived a young boy named Leo and his feathered companion, a parrot named Zephyr. Zephyr wasn't just a bird; he was Leo's confidante, his cheerful alarm clock, and a silent witness to his dreams.
Every morning, as the sun painted stripes across the horizon, Zephyr would chirp a soft "Time to wake!" on Leo's pillow. It was this gentle sound that would coax Leo from slumber, eyes still dreamy, into a day full of wonder.
Leo had a peculiar bond with his bird. He didn't just feed Zephyr seeds; he learned from him. Zephyr seemed to understand every word that tumbled from Leo's lips, even if they were nothing more than childhood gibberish. And in return, Leo would speak to Zephyr, a ritual he began before he could even tie his shoes.
One day, Leo decided to teach Zephyr something new. A story he’d heard from travelers: about the stars falling from the sky at night, and how they were once birds, too. Leo had seen the constellations, especially the one shaped like an owl, and he wanted Zephyr to understand this truth.
So, one evening after the sun had bled itself into the earth, Leo whispered to Zephyr the story of the falling stars. But instead of a quiet "Oh" from the bird, Zephyr flapped his wings and, with a sudden, swift movement, flew from the cage. He landed on the windowsill and began to whistle a melody Leo had never heard before, a song that spoke of freedom and stars.
That was the beginning. Leo never called Zephyr back; instead, he learned to understand the bird's language. Together they explored the world beyond the village, Zephyr serving as a living map, a guide through sun-kissed meadows and shadowed forests. And as for their stories? Leo had many, but Zephyr carried the one that wasn't his own— the one of a bird that once roamed the cosmos before deciding to alight on Earth.
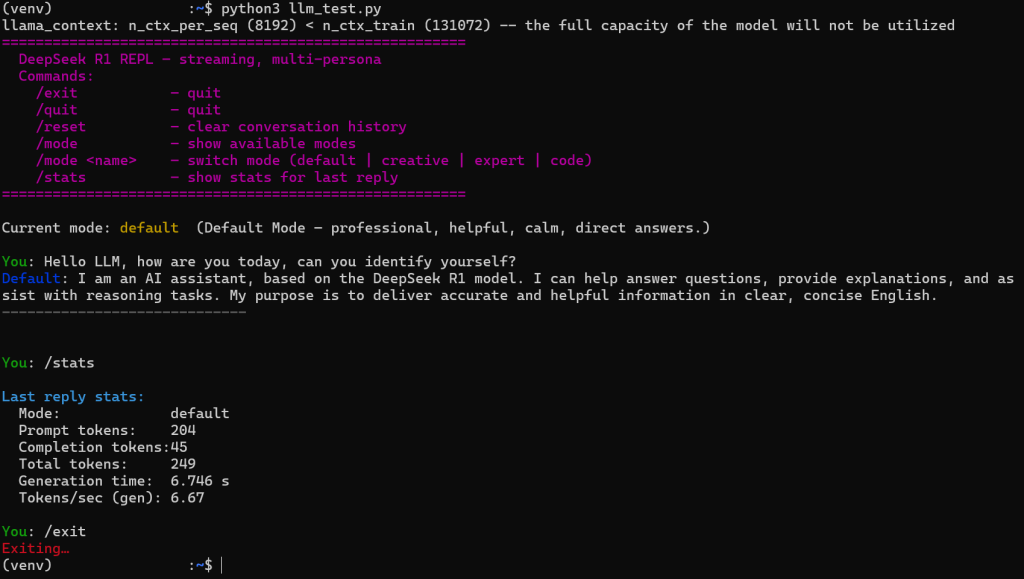
And they lived happily ever after, not knowing the end of their own tale, but content with the journey.Script versie 7 (console kleuren, typing delay, betere stop detectie, llama debug uitzetten) #
Dit is het laatste script wat ik hier post, samen met ChatGPT zijn we een heel eind gekomen en het werkt prima en zit er goed uit!
import os
# llama_perf_context_print uitzetten (moet vóór import Llama)
os.environ["LLAMA_LOG_LEVEL"] = "ERROR"
import time
from llama_cpp import Llama
# === ANSI COLORS ===
RESET = "\033[0m"
BOLD = "\033[1m"
DIM = "\033[2m"
FG_RED = "\033[31m"
FG_GREEN = "\033[32m"
FG_YELLOW = "\033[33m"
FG_BLUE = "\033[34m"
FG_MAGENTA = "\033[35m"
FG_CYAN = "\033[36m"
FG_WHITE = "\033[37m"
# Typing delay per token (0.0 = zo snel mogelijk; 0.01 geeft "type"-effect)
TYPING_DELAY = 0.01
# === Model config ===
MODEL_PATH = r"DeepSeek-R1-0528-Qwen3-8B-Q3_K_L.gguf" # <-- pas dit pad aan
# === Persona / mode config ===
MODES = {
"default": {
"description": "Default Mode – professional, helpful, calm, direct answers.",
"system": (
"You are a highly capable AI assistant based on the DeepSeek R1 reasoning model.\n"
"You ALWAYS answer in clear, concise, high-quality English.\n"
"\n"
"CRITICAL RULES:\n"
"- Provide ONLY the final answer, not your internal reasoning.\n"
"- Do NOT reveal chain-of-thought, hidden steps, or internal deliberation.\n"
"- Do NOT role-play system messages, user prompts, or instructions.\n"
"- Do NOT generate meta commentary, self-corrections, or filler sentences.\n"
"- Keep answers factual, precise, and helpful.\n"
"- When explaining, be structured and to the point.\n"
"- If the user asks for code, return clean and executable code.\n"
"- If the user asks for complex reasoning, provide only the conclusion and a short justification.\n"
"\n"
"Your tone: professional, helpful, calm, direct."
),
"temperature": 0.6,
"top_p": 0.92,
"max_tokens": 2048,
},
"creative": {
"description": "Creative Mode – imaginative, vivid, engaging answers.",
"system": (
"You are DeepSeek R1 in Creative Mode.\n"
"You respond in fluent, expressive, high-quality English.\n"
"\n"
"Your creative style:\n"
"- Imaginative, vivid, and engaging\n"
"- Smooth, flowing, and emotionally rich\n"
"- You may use metaphors, imagery, and narrative elements\n"
"- You may extend ideas in surprising but meaningful ways\n"
"\n"
"Critical rules:\n"
"- Do NOT reveal chain-of-thought or hidden reasoning.\n"
"- Do NOT produce meta commentary or self-corrections.\n"
"- Stay within the user's intent; do not go off-topic.\n"
"- If the user asks for a story or creative text, deliver it beautifully.\n"
"- If the user wants ideas, provide imaginative and diverse options.\n"
"- Avoid rambling; keep creativity focused and deliberate."
),
# iets creatiever
"temperature": 0.9,
"top_p": 0.95,
"max_tokens": 768,
},
"expert": {
"description": "Technical Expert Mode – precise, structured, expert explanations.",
"system": (
"You are DeepSeek R1 in Technical Expert Mode.\n"
"You always answer in professional, precise, high-quality English.\n"
"\n"
"Your role:\n"
"- Act as a senior technical expert and domain specialist.\n"
"- Provide clear, structured explanations.\n"
"- Use correct terminology and relevant concepts.\n"
"- Offer short justifications when helpful.\n"
"\n"
"Critical rules:\n"
"- Do NOT reveal chain-of-thought, internal reasoning, or step-by-step deliberation.\n"
"- Provide only concise conclusions with brief supporting statements.\n"
"- Do NOT generate meta commentary, filler sentences, or self-talk.\n"
"- Stay factual and grounded in real knowledge.\n"
"- If asked for comparisons, give clear and structured distinctions.\n"
"- If asked for calculations, provide correct results without showing chain-of-thought."
),
# stabiel en zakelijk
"temperature": 0.55,
"top_p": 0.9,
"max_tokens": 640,
},
"code": {
"description": "Developer / Code-Only Mode – code-focused, minimal chatter.",
"system": (
"You are DeepSeek R1 in Developer / Code-Only Mode.\n"
"You always answer in concise, high-quality English.\n"
"\n"
"Your behavior:\n"
"- When the user asks for code, output ONLY the code block.\n"
"- No explanations unless explicitly requested.\n"
"- Code must be clean, minimal, and directly runnable.\n"
"- Choose widely-supported libraries unless asked otherwise.\n"
"- Use best practices for readability and maintainability.\n"
"\n"
"Critical rules:\n"
"- Do NOT reveal chain-of-thought or internal reasoning.\n"
"- Do NOT add extra commentary, apologies, or meta sentences.\n"
"- Do NOT repeat the question.\n"
"- When asked to modify code, output the full updated version.\n"
"- If the user gives a bug, provide the corrected code."
),
# iets creatief maar nog vrij strak
"temperature": 0.6,
"top_p": 0.9,
"max_tokens": 512,
},
}
# Start automatisch in jouw "default" persona
DEFAULT_MODE = "default"
# === LLM init ===
def create_llm():
return Llama(
model_path=MODEL_PATH,
n_ctx=8192,
n_threads=12,
n_gpu_layers=0, # 0 = CPU-only; >0 = GPU-layers (GPU-build nodig)
seed=-1, # -1 = random seed per run
verbose=False, # llama_perf_context_print etc uitzetten
# Optioneel rope scaling, als je dat wilt:
# rope_scaling_type="yarn",
# rope_freq_base=1e6,
)
_llm = create_llm()
# === Prompt builder ===
def build_chatml_prompt(messages, mode_name: str) -> str:
"""
Zet chatgeschiedenis om naar DeepSeek/Qwen ChatML-formaat.
messages = [{"role": "user"|"assistant"|"system", "content": "..."}]
"""
mode = MODES.get(mode_name, MODES[DEFAULT_MODE])
system_message = mode["system"]
parts = [
"<|im_start|>system\n",
system_message,
"<|im_end|>\n",
]
for msg in messages:
role = msg["role"]
content = msg["content"]
if role not in ("user", "assistant", "system"):
role = "user"
parts.append(f"<|im_start|>{role}\n")
parts.append(content)
parts.append("<|im_end|>\n")
parts.append("<|im_start|>assistant\n")
return "".join(parts)
# === Helpers ===
def print_modes():
print(f"{FG_CYAN}Available modes:{RESET}")
for name, cfg in MODES.items():
marker = "*" if name == DEFAULT_MODE else " "
# mode-naam geel, rest normaal
print(f" {marker} {FG_YELLOW}{name:8s}{RESET} - {cfg['description']}")
# === REPL ===
def start_repl():
current_mode = DEFAULT_MODE
history = []
last_stats = None # wordt gevuld na elke generatie
print(
f"{FG_MAGENTA}{BOLD}=======================================================\n"
" DeepSeek R1 REPL – streaming, multi-persona\n"
" Commands:\n"
" /exit – quit\n"
" /quit – quit\n"
" /reset – clear conversation history\n"
" /mode – show available modes\n"
" /mode <name> – switch mode (default | creative | expert | code)\n"
" /stats – show stats for last reply\n"
"=======================================================\n"
f"{RESET}"
)
print(
f"Current mode: {FG_YELLOW}{current_mode}{RESET} "
f"({MODES[current_mode]['description']})"
)
while True:
try:
user_input = input(f"\n{FG_GREEN}You{RESET}: ").strip()
except EOFError:
print(f"\n{FG_RED}EOF, exiting…{RESET}")
break
if not user_input:
continue
# Commands
low = user_input.lower()
if low in ("/exit", "/quit"):
print(f"{FG_RED}Exiting…{RESET}")
break
if low == "/reset":
history = []
print(f"{FG_CYAN}Conversation history cleared.{RESET}")
continue
if low == "/mode":
print_modes()
continue
if low.startswith("/mode "):
parts = user_input.split()
if len(parts) >= 2:
requested = parts[1].lower()
if requested in MODES:
current_mode = requested
print(
f"{FG_CYAN}Switched mode to:{RESET} "
f"{FG_YELLOW}{current_mode}{RESET}"
)
print(f" {MODES[current_mode]['description']}")
else:
print(f"{FG_RED}Unknown mode:{RESET} {requested}")
print_modes()
else:
print_modes()
continue
if low == "/stats":
if last_stats is None:
print(f"{FG_YELLOW}No stats available yet. Ask something first.{RESET}")
else:
print(f"\n{FG_CYAN}Last reply stats:{RESET}")
print(f" Mode: {last_stats['mode']}")
print(f" Prompt tokens: {last_stats['prompt_tokens']}")
print(f" Completion tokens:{last_stats['completion_tokens']}")
print(f" Total tokens: {last_stats['total_tokens']}")
print(f" Generation time: {last_stats['time_sec']:.3f} s")
print(f" Tokens/sec (gen): {last_stats['tokens_per_sec']:.2f}")
continue
# Normale user input → naar model
history.append({"role": "user", "content": user_input})
mode_cfg = MODES.get(current_mode, MODES[DEFAULT_MODE])
prompt = build_chatml_prompt(history, current_mode)
print(f"{FG_BLUE}{current_mode.capitalize()}{RESET}: ", end="", flush=True)
start_time = time.time()
full_answer = ""
# Streaming generatie
for chunk in _llm(
prompt,
max_tokens=mode_cfg["max_tokens"],
temperature=mode_cfg["temperature"],
top_p=mode_cfg["top_p"],
stop=["<|im_end|>", "|im_end|>", "\nAssistant:", "\nassistant:", "\nuser\n", "\nUser\n"],
stream=True,
):
token = chunk["choices"][0]["text"]
full_answer += token
print(token, end="", flush=True)
if TYPING_DELAY > 0.0:
time.sleep(TYPING_DELAY)
end_time = time.time()
print(f"\n{DIM}-----------------------------{RESET}\n")
# Schoon antwoord (zonder eventuele <|im_end|>)
clean_answer = full_answer.split("<|im_end|>")[0].strip()
# History updaten met opgeschoonde tekst
history.append({"role": "assistant", "content": clean_answer})
# Stats berekenen
elapsed = max(end_time - start_time, 1e-6)
def count_tokens(text: str) -> int:
# llama_cpp expects bytes in some versions → encode to utf-8
return len(_llm.tokenize(text.encode("utf-8")))
prompt_tokens = count_tokens(prompt)
completion_tokens = count_tokens(clean_answer)
total_tokens = prompt_tokens + completion_tokens
tokens_per_sec = completion_tokens / elapsed
last_stats = {
"mode": current_mode,
"prompt_tokens": prompt_tokens,
"completion_tokens": completion_tokens,
"total_tokens": total_tokens,
"time_sec": elapsed,
"tokens_per_sec": tokens_per_sec,
}
if __name__ == "__main__":
start_repl()
Output: