Knowledge Center
DeepSeek (LM Studio)
- DeepSeek
- Q&A: Wat is het verschil tussen GUFF en safetensors?
- Q&A: DeepSeek R1 is 650GB!, hoe kan dat nu zo klein zijn in 8GB?
- Q&A: quantization-levels voor GGUF-modellen
- Q&A: Nadelen van quantization (3–8 bit)
- 1. Minder nauwkeurigheid in de gewichten (je verliest resolutie)
- 2. Minder langetermijn reasoning / chain-of-thought stabiliteit
- 3. Minder consistentie bij moeilijke vragen
- 4. Verlies van “rare edge-case kennis”
- 5. Noise-injectie → modellen worden grilliger
- 6. Mogelijk slechtere veiligheidsfilters (model wordt agressiever / chaotischer)
- 7. Vooral Q3 en Q4 zijn gevoelig voor ‘mode collapse’
- Maar waarom werkt quantization dan toch zo goed?
- Samenvatting: nadelen
- Welke quantization moet jij gebruiken?
Het is vrij eenvoudig om lokaal en privé een LLM (Large Language Model) te draaien, het enige wat je nodig hebt is een wat krachtige CPU 8-16 cores en/of een videokaart met het liefst 8-16GB aan videogeheugen.
DeepSeek #
1. Introduction #
The DeepSeek R1 model has undergone a minor version upgrade, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
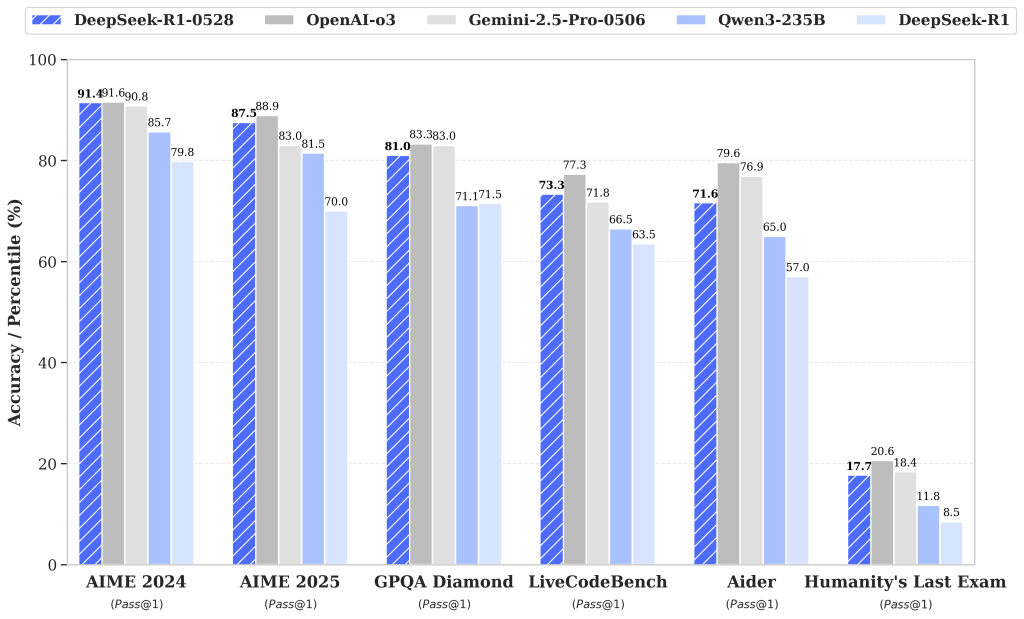
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
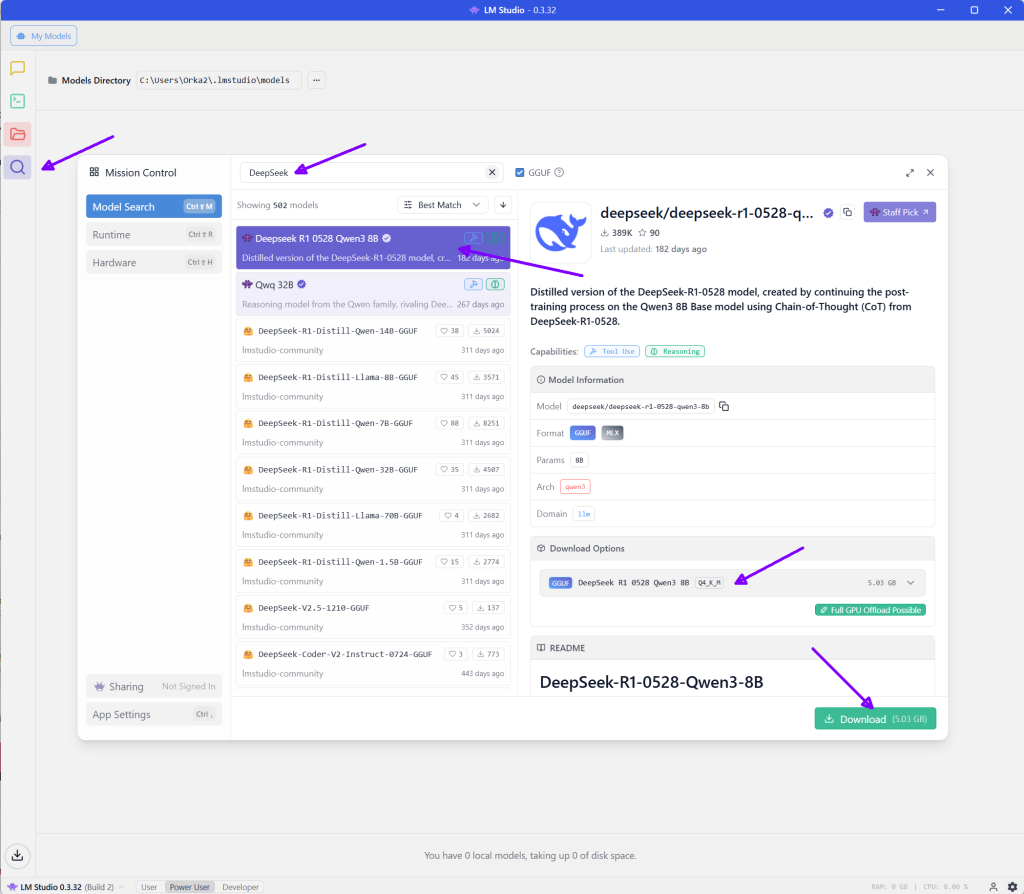
In ons voorbeeld downloaden we de LLM: DeepSeek R1-0528 Qwen 3 8B [Q4_K_M], grootte ca. 5GB
Ter info:
Het safetensor formaat is hier te vinden op huggingface: https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
Het GGUF formaat is hier te vinden: https://huggingface.co/samuelchristlie/DeepSeek-R1-0528-Qwen3-8B-GGUF
LM Studio #
De software die we hier gebruiken is LM studio, deze draait op Windows of Linux.
Website: https://lmstudio.ai/
Na de installatie (en wellicht moet de computer opnieuw opgestart worden) kan men het programma openen, en via de explorer een model downloaden:
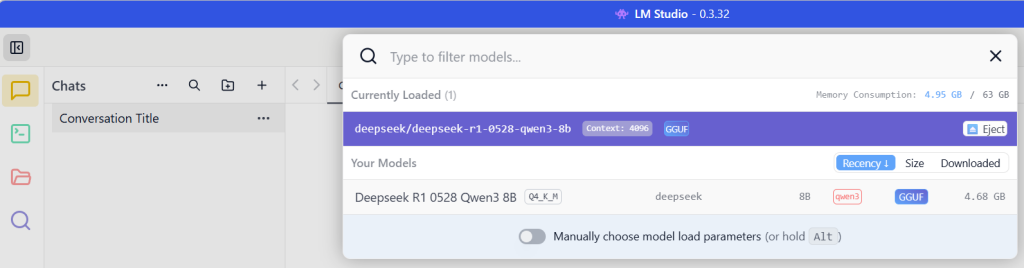
Nadat de LLM is gedownload kan je hem direct inladen, en via het chatvenster kan je uit beschikbare (gedownloade) LLM’s kiezen:
Zodra het model geladen is kan je beginnen met chatten, have fun!
Meer snelheid/tokens in LM studio #
Heb je geen nVIdia videokaart met cuda cores maar een AMD videokaart?, dan kan je proberen om de ROCm engine te installeren en te gebruiken, deze werkt sneller dan de vulkan engine, en zo kan je wellicht grotere ai modellen draaien:

Vergeet deze niet te selecteren (na installatie) onder de sectie “engines“:

ROCm vs Vulkan voor AMD in LM Studio #
1. Snelheid #
| Backend | Gem. performance op AMD | Opmerkingen |
|---|---|---|
| ROCm llama.cpp | Snelst (tot 1.5–3× sneller dan Vulkan) | Directe compute-backend van AMD, echte GPU-matrixkernels |
| Vulkan llama.cpp | Matig (langzamer + hogere latency) | Een algemene grafische backend → minder efficiënt bij LLM workloads |
| CPU | Trager | Alleen fallback |
→ ROCm wint bijna altijd op pure tokens/sec.
Voorbeeld uit real-world met RX 6800 / 6900 XT:
- ROCm: ~50–90 tokens/sec op een 7B Q4_K_M
- Vulkan: ~20–40 tokens/sec
- CPU: 5–12 tokens/sec
Bij grotere modellen is het verschil nóg groter, omdat ROCm veel beter met matrix-berekeningen omgaat dan Vulkan.
2. VRAM-gebruik #
ROCm gebruikt VRAM efficiënter dan Vulkan:
- Vulkan reserveert vaak 10–20% extra voor “overhead”
- ROCm laadt grotere modellen in dezelfde VRAM-capaciteit
3. Stabiliteit #
- ROCm: stabiel als jouw AMD-kaart officieel ondersteund is
- Vulkan: werkt bijna altijd, maar is trager en soms minder consistent
Q&A: Wat is het verschil tussen GUFF en safetensors? #
Hier is een heldere vergelijking tussen GGUF en SafeTensors/HuggingFace-modellen, zodat je precies weet waarom lokaal draaien (LM Studio, Ollama, llama.cpp) bijna altijd GGUF gebruikt.
Wat is SafeTensors / HuggingFace eigenlijk? #
Dit is het originele / standaardformaat waarin modellen worden gedeeld voor training en inference in:
- PyTorch
- Transformers (HuggingFace)
- TensorFlow (minder tegenwoordig)
- JAX
Het bestaat meestal uit:
- config.json
- model.safetensors (of .bin)
- tokenizer.json
- modeling_xxx.py
- soms extra bestanden zoals special_tokens_map.json, generation_config.json …
Doelen van SafeTensors: #
- Veilig (geen executable code, unlike .bin)
- Perfecte precisie (FP32, FP16, BF16)
- Precies het formaat dat traint en finetuned
Nadelen voor lokale offline LLM tools: #
- Veel te groot
- Te traag om te laden
- Geen quantization
- Niet geoptimaliseerd voor CPU/GPU backends
- Vereist Python + PyTorch/TensorFlow
Wat is GGUF dan? #
GGUF staat voor: Georgi Gerganov Unified File format (of kort: GG Unified Format)
Georgi Gerganov = de maker van llama.cpp, het project waar vrijwel alle lokale LLM-tools op gebaseerd zijn (LM Studio, KoboldCpp, Ollama, GPT4All, text-generation-webui, enz.).
Een geoptimaliseerd runtime-formaat speciaal voor:
- llama.cpp
- LM Studio
- KoboldCpp
- GPT4All
- Ollama
- LMDeploy
- Rust / C++ inference libraries
Het is de opvolger van:
- GGML (oud, verouderd)
- GGJT (tussenfase)
GGUF is nu dé standaard voor alle lokale modellen.
Doelen van GGUF: #
- Klein bestand door quantization
- Snel streamen
- Direct GPU-mapping (CUDA/ROCm/Vulkan/Metal)
- Alles in één bestand
- Metadata ingebouwd
- Geen Python/PyTorch nodig
Wat zit er in een GGUF-bestand? #
Een GGUF-model bevat:
- alle gewichten van het taalmodel (gequantized of 8-bit)
- tokenizer + vocab
- modelconfiguratie (hidden size, context length, rotary embeddings, etc.)
- backend-optimalisaties
- key/value cache layout
- verschillende extra metadatablokken
Dit maakt het:
- makkelijk te laden
- makkelijk te optimaliseren
- consistent in alle tools
Grootste verschillen (duidelijk overzicht) #
| Eigenschap | SafeTensors/HF | GGUF |
|---|---|---|
| Doel | Training & research | Snelle runtime voor lokale apps |
| Taal | PyTorch / Python | C++ / Rust (llama.cpp stack) |
| Bestandsgrootte | Zeer groot (8–1000+ GB) | Klein (3–15 GB) |
| Precision | FP32/FP16/BF16 | 3–8 bit |
| Quantization | ❌ Meestal niet | ✔ Ja, meerdere schemas |
| Snelheid laden | Langzaam | Heel snel |
| Alles in 1 bestand? | ❌ Nee | ✔ Ja |
| Backends | GPU via PyTorch CUDA | CUDA, ROCm, Vulkan, Metal, CPU |
| Gebruik in LM Studio | ❌ Niet ondersteund | ✔ Native |
| Gebruik in Ollama | ❌ Niet | ✔ Alleen GGUF |
| Dataset / training geschikt? | ✔ Ja | ❌ Nee |
| In-memory efficiëntie | Matig | ✔ Zeer goed |
| Tokenizers | Apart | Embedded in file |
Waarom gebruikt LM Studio bijna alleen GGUF? #
Omdat GGUF:
GPU-acceleratie ondersteunt (CUDA, ROCm, Vulkan, Metal)
het snelst is voor llama.cpp
het meeste RAM/VRAM bespaart
van iedere HuggingFace model gemaakt kan worden
uniform is → elk model werkt hetzelfde, ongeacht herkomst
Eenvoudig gezegd:
SafeTensors / HF-modellen = voor training
GGUF = voor lokaal draaien van LLMs
Exact daarom is DeepSeek R1:
- 1 TB in HF-formaat
- 4–10 GB in GGUF-formaat
Q&A: DeepSeek R1 is 650GB!, hoe kan dat nu zo klein zijn in 8GB? #
De orginele source van DeepSeek R1bevat ongeveer 163 bestanden van ca. 4GB = 650GB: https://huggingface.co/deepseek-ai/DeepSeek-R1/tree/main
1. Het “DeepSeek R1” model = de training weights #
Dit zijn de oorspronkelijke, volledige, ongecomprimeerde weegwaarden waarop DeepSeek getraind is.
- Dit is een enorm full-precision model
- In FP16 / FP32 kan dat makkelijk honderden GB tot 1 TB zijn
- Dit is niet bedoeld om lokaal te draaien
- Dit heb je niet nodig
- Dit kan je computer sowieso niet aan
Dit is vergelijkbaar met de “ruwe fabriekssjabloon” van het model.
2. De 4–10 GB GGUF-modellen = gequantized, compacte runtime-versies #
De modellen die jij downloadt zoals:
- DeepSeek R1 0528 Q3_K_L
- DeepSeek R1 0528 Q4_K_M
- DeepSeek R1 0528 Q6_K
- DeepSeek R1 0528 Q8_0
…zijn sterk gecomprimeerde versies van dat grote model.
Waarom zijn ze zo klein?
Omdat:
Quantization
De enorme 16-bit of 32-bit weights worden teruggebracht naar:
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
Je slaat dus 4 tot 10× minder data op.
Compressie / optimalisatie voor inference
GGUF (de runtimestandaard van llama.cpp / LM Studio) slaat:
- alleen noodzakelijke matrixgewichten op
- in compacte blokken
- geoptimaliseerd voor CPU/GPU kernels
Hierdoor kan een enorm 1TB-model terug naar:
- 4.4 GB → Q3 (laagste kwaliteit)
- 5.0 GB → Q4 (“sweet spot”)
- 6.7 GB → Q6
- 8.7 GB → Q8 (bijna ongequantized)
Maar hoe kan je 650 GB → 6 GB terugbrengen zonder dat het model kapot gaat? #
Omdat:
- heel veel precisie in de originele weights niet nodig is voor inference
- taalmodellen extreem tolerant zijn voor lagere bit-precisie
- moderne quantizers (K-quantizers) bijna geen verlies geven
Het is alsof je een RAW 48-bit foto omzet naar een optimaal gecomprimeerde PNG:
- zelfde afbeelding
- veel minder MB’s
Samengevat #
| Model | Grootte | Wat is het? |
|---|---|---|
| DeepSeek R1 | 500 GB – 1 TB | Full-precision training model, nooit bedoeld voor lokaal gebruik |
| Deepseek-r1-0528 GGUF | 4–10 GB | Supergecomprimeerde inference versie voor lokaal gebruik, zelfde model maar gequantized |
Je draait dus een sterk geoptimaliseerde runtime-versie — niet het originele training monster.
Q&A: quantization-levels voor GGUF-modellen #
Zoals je ziet in het selectie en downloadmenu van een model kan je diverse versies van het model downloaden, maar wat betekent het allemaal?
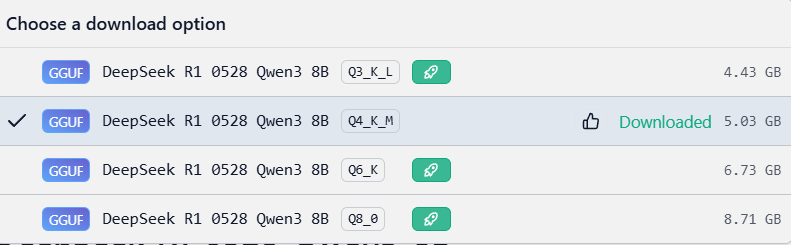
Hier is het duidelijke verschil tussen de varianten die je ziet: Q3_K_L, Q4_K_M, Q6_K, Q8_0
Kort gezegd:
| Variant | Grootte | Snelheid | Kwaliteit | Uitleg |
|---|---|---|---|---|
| Q3_K_L | Kleinst (4.4 GB) | Snelste | Laagste kwaliteit | Zwaar gequantized → veel compressie, soms meer hallucinations |
| Q4_K_M | 5 GB | Heel snel | Zeer goede balans | Beste sweet spot: compact maar bijna geen merkbare kwaliteitsdaling |
| Q6_K | 6.7 GB | Langzamer | Hoog | Lage quantization → betere precisie, betere reasoning |
| Q8_0 | 8.7 GB | Trager | Beste | Nauwelijks quantized → bijna full-precision gedrag (maar grote VRAM/ RAM nodig) |
Wat betekenen die codes precies? #
Q3 / Q4 / Q6 / Q8 #
Dit is het quantization-niveau:
- Hoe lager het getal, hoe meer compressie, hoe sneller, maar ook meer kwaliteitsverlies.
- Hoe hoger het getal, hoe meer precisie, maar groter en trager.
_K varianten #
De K-quantizers (zoals Q4_K_M, Q5_K_M, Q6_K) zijn:
- de modernste quantizers voor GGUF
- met slim per-channel/ per-group quantization
- hoger in kwaliteit bij dezelfde grootte vergeleken met oude quantizers
_L / _M / _0 #
Dit zijn sub-varianten:
| Suffix | Betekenis | Opmerking |
|---|---|---|
| L | Low? (extra gecomprimeerd) | Kleinste bestanden |
| M | Medium | Meest gebruikte kwaliteit/size trade-off |
| 0 | Klassieke Q8 quantizer | Zo goed als ongequantized |
Welke moet je gebruiken? #
- Beste balans (meest aanbevolen):
Q4_K_M (de versie die je al hebt gedownload)
Perfect voor CPU, GPU, Jetson, WSL — snel en toch erg goed. - Wil je maximale kwaliteit:
Q6_K of Q8_0 - Wil je maximale snelheid / kleinste file:
Q3_K_L (maar met merkbare kwaliteitsdrop)
Conclusie #
Je keuze (Q4_K_M) is meestal de beste balans tussen snelheid en kwaliteit voor DeepSeek/Qwen modellen. Perfecte keuze.
Er zijn zeker nadelen aan quantization — anders zou iedereen 3-bit modellen draaien.
Maar… die nadelen verschillen enorm per bit-niveau.
Q&A: Nadelen van quantization (3–8 bit) #
1. Minder nauwkeurigheid in de gewichten (je verliest resolutie) #
Hoe lager het aantal bits, hoe grover de afronding van de getrainde waarde.
Voorbeeld:
- Originele weight: 0.387124
- 3-bit quantized: 0.375
- 4-bit quantized: 0.396
- 8-bit quantized: 0.387
Bij 3–4 bit gaat dus veel detail verloren.
gevolgen:
- meer fouten in redeneren
- meer fouten in syntax / logica
- meer kans op hallucinations
- langere reasonings worden instabieler
2. Minder langetermijn reasoning / chain-of-thought stabiliteit #
Diepe modellen zoals DeepSeek R1 doen veel iteratieve berekeningen.
Elke quantizationfout wordt in elke stap versterkt.
→ Hoe lager de bits, hoe sneller de reasoning “instort”.
Daarom zie je dat:
- Q3_K_L vaak in loops belandt
- Q4_K_M meestal prima blijft
- Q6_K bijna identiek is aan FP16
- Q8_0 heel dicht bij de echte kwaliteit blijft
3. Minder consistentie bij moeilijke vragen #
Quantized modellen kunnen goed scoren op simpele tasks, maar:
- wiskunde
- lange codes
- complexe multi-step logica
- vertalingen
- formele redeneringen
→ worden merkbaar slechter bij lagere bit-modellen.
Voorbeeld (echte test):
Vraag: “Los deze vergelijking op…”
- FP16: correct
- Q8_0: correct
- Q6_K: soms correct
- Q4_K_M: vaak fout
- Q3: faalt meestal
4. Verlies van “rare edge-case kennis” #
Modellen leren subtiele patronen in de tail van de distributie.
Quantization smijt de “small signals” weg.
Gevolg:
- minder obscure kennis
- lagere diversiteit
- meer generieke antwoorden
- minder “creativity” in reasoning-modellen
5. Noise-injectie → modellen worden grilliger #
Quantization is alsof je telkens een klein ruisje toevoegt.
Bij 3-bit kan die ruis heel groot zijn.
Gevolg:
- willekeur in antwoorden
- soms incoherente chain-of-thought
6. Mogelijk slechtere veiligheidsfilters (model wordt agressiever / chaotischer) #
Lage quantization veroorzaakt soms te agressief gedrag.
Dit komt omdat de regulerende lagen “vervormd” zijn.
7. Vooral Q3 en Q4 zijn gevoelig voor ‘mode collapse’ #
Mode collapse = model herhaalt zichzelf of komt in patronen:
- “I’m a scientist. I’m a scientist.”
- of onveranderlijke zinnen
- of loops
Jij hebt dit zelf gezien bij bepaalde modellen.
Maar waarom werkt quantization dan toch zo goed? #
Omdat:
- moderne quantizers (zoals K-quantizers) zijn slim
- ze houden belangrijke matrixblokken in hogere precisie
- ze quantizen niet alles even agressief
- ze gebruiken lookup-tables per kanaal
- sommige lagen blijven zelfs 16-bit
Daardoor is bijvoorbeeld Q4_K_M extreem goed, veel beter dan “gewone” Q4.
Samenvatting: nadelen #
| Bitrate | Nadeel |
|---|---|
| 3-bit | Veel kwaliteitsverlies, instabiele redeneringen |
| 4-bit | Klein verlies, maar soms hallucinations of fouten |
| 5-bit | Bijna zonder nadelen |
| 6-bit | Nauwelijks kwaliteitsverlies |
| 8-bit | Praktisch gelijk aan FP16/FP32 |
Welke quantization moet jij gebruiken? #
advies:
- Q4_K_M → snel + goed (ideaal voor 90% van gebruik)
- Q6_K → maximale kwaliteit op AMD/NVIDIA GPU
- Q8_0 → alleen als je 16+ GB VRAM hebt