Knowledge Center
Diverse AI LLM overzicht
- Z.AI - GLM 4.6V (release date 2025-12-28)
- Z.AI - GLM 4.7 (release date 2025-12-22)
- NVIDIA - Nemotron 3 Nano (release date 2025-12-15)
- Mistral AI - Mistral 3 (release date 2025-12-02)
- NousResearch - Hermes 4.3 (release date 2025-12-02)
- Allenai - OLMo 3 (release date 2025-11-20)
- NousResearch - Hermes 4 (release date 2025-08-25)
- Alibaba - Qwen3 (release date 2025-04-28)
- DeepSeek - DeepSeek V3-0324 (release date 2025-03-24)
- Google - Gemma 3 (release date 2025-03-12)
- DeepSeek - DeepSeek R1 (release date 2025-01-20)
- Microsoft - PHI4 (release date 2024-12-28)
- Alibaba - Qwen2.5 (release date 2024-09-30)
- Mistral AI - Mistral 7B (release date 2024-05-27)
- Microsoft - PHI3 (release date 2024-04-23)
- Meta - Llama 3 (release date 2024-04-18)
- Microsoft - PHI1.5 (release date 2023-09-24)

Hieronder is een overzicht samengesteld van leuke en bekende OPEN SOURCE AI LLM modellen.
De meeste zijn “quantized” GUFF modellen, een soort gecomprimeerde versie van safetensors. Ze zijn makkelijk te gebruiken met LM studio en o.a. voor 8GB, 12GB, 16GB videokaarten geschikt.
Z.AI – GLM 4.6V (release date 2025-12-28) #
Website: https://z.ai/blog/glm-4.6v
Github: https://github.com/zai-org/GLM-V
Huggingface: https://huggingface.co/unsloth/GLM-4.6V-Flash-GGUF
About #
GLM-4.6V series model includes two versions: GLM-4.6V (106B), a foundation model designed for cloud and high-performance cluster scenarios, and GLM-4.6V-Flash (9B), a lightweight model optimized for local deployment and low-latency applications. GLM-4.6V scales its context window to 128k tokens in training, and achieves SoTA performance in visual understanding among models of similar parameter scales. Crucially, we integrate native Function Calling capabilities for the first time. This effectively bridges the gap between “visual perception” and “executable action” providing a unified technical foundation for multimodal agents in real-world business scenarios.
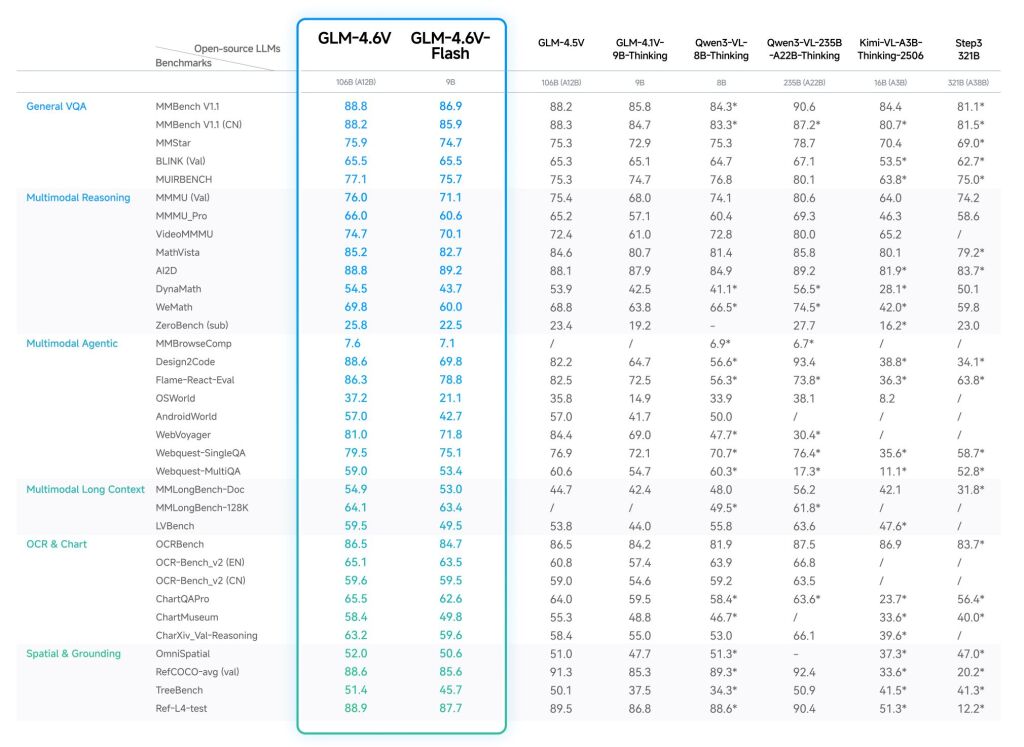
Beyond achieves SoTA performance across major multimodal benchmarks at comparable model scales. GLM-4.6V introduces several key features:
- Native Multimodal Function Calling Enables native vision-driven tool use. Images, screenshots, and document pages can be passed directly as tool inputs without text conversion, while visual outputs (charts, search images, rendered pages) are interpreted and integrated into the reasoning chain. This closes the loop from perception to understanding to execution.
- Interleaved Image-Text Content Generation Supports high-quality mixed media creation from complex multimodal inputs. GLM-4.6V takes a multimodal context—spanning documents, user inputs, and tool-retrieved images—and synthesizes coherent, interleaved image-text content tailored to the task. During generation it can actively call search and retrieval tools to gather and curate additional text and visuals, producing rich, visually grounded content.
- Multimodal Document Understanding GLM-4.6V can process up to 128K tokens of multi-document or long-document input, directly interpreting richly formatted pages as images. It understands text, layout, charts, tables, and figures jointly, enabling accurate comprehension of complex, image-heavy documents without requiring prior conversion to plain text.
- Frontend Replication & Visual Editing Reconstructs pixel-accurate HTML/CSS from UI screenshots and supports natural-language-driven edits. It detects layout, components, and styles visually, generates clean code, and applies iterative visual modifications through simple user instructions.
Download #
GLM-4.6V-flash (GUFF): https://huggingface.co/unsloth/GLM-4.6V-Flash-GGUF/tree/main
Z.AI – GLM 4.7 (release date 2025-12-22) #
Website: https://z.ai/blog/glm-4.7
Huggingface: https://huggingface.co/zai-org/GLM-4.7
This new model is smarter than Sonnet 4.5…and 20X faster?: https://www.cerebras.ai/blog/glm-4-7-migration-guide
About #
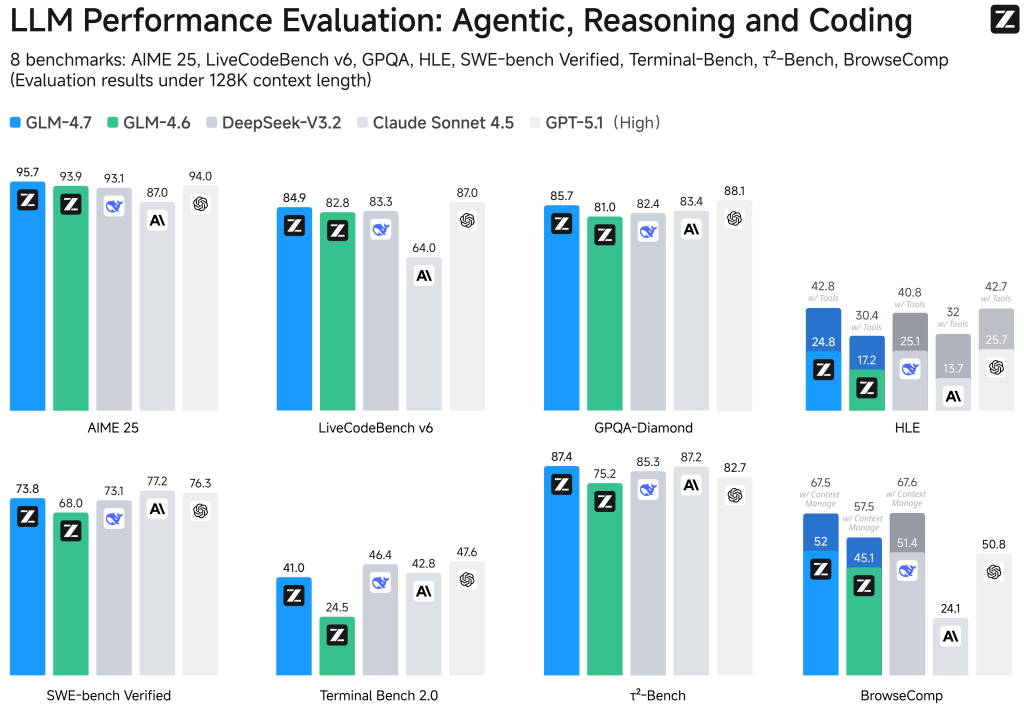
GLM-4.7, your new coding partner, is coming with the following features:
- Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
- Vibe Coding: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
- Tool Using: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp.
- Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
You can also see significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
Download #
GLM-4.7 (GUFF): https://huggingface.co/lmstudio-community/GLM-4.7-GGUF
NVIDIA – Nemotron 3 Nano (release date 2025-12-15) #

Website: https://nvidianews.nvidia.com/news/nvidia-debuts-nemotron-3-family-of-open-models
Huggingface BF16: https://huggingface.co/nvidia
LM Studio: https://lmstudio.ai/models/nemotron-3
About #
NVIDIA today announced the NVIDIA Nemotron™ 3 family of open models, data and libraries designed to power transparent, efficient and specialized agentic AI development across industries.
The Nemotron 3 models — with Nano, Super and Ultra sizes — introduce a breakthrough hybrid latent mixture-of-experts (MoE) architecture that helps developers build and deploy reliable multi-agent systems at scale.
As organizations shift from single-model chatbots to collaborative multi-agent AI systems, developers face mounting challenges, including communication overhead, context drift and high inference costs. In addition, developers require transparency to trust the models that will automate their complex workflows. Nemotron 3 directly addresses these challenges, delivering the performance and openness customers need to build specialized, agentic AI.
“Open innovation is the foundation of AI progress,” said Jensen Huang, founder and CEO of NVIDIA. “With Nemotron, we’re transforming advanced AI into an open platform that gives developers the transparency and efficiency they need to build agentic systems at scale.”
NVIDIA Nemotron supports NVIDIA’s broader sovereign AI efforts, with organizations from Europe to South Korea adopting open, transparent and efficient models that allow them to build AI systems aligned to their own data, regulations and values.
Early adopters, including Accenture, Cadence, CrowdStrike, Cursor, Deloitte, EY, Oracle Cloud Infrastructure, Palantir, Perplexity, ServiceNow, Siemens, Synopsys and Zoom, are integrating models from the Nemotron family to power AI workflows across manufacturing, cybersecurity, software development, media, communications and other industries.
“NVIDIA and ServiceNow have been shaping the future of AI for years, and the best is yet to come,” Bill McDermott, chairman and CEO of ServiceNow. “Today, we’re taking a major step forward in empowering leaders across all industries to fast-track their agentic AI strategy. ServiceNow’s intelligent workflow automation combined with NVIDIA Nemotron 3 will continue to define the standard with unmatched efficiency, speed and accuracy.”
As multi-agent AI systems expand, developers are increasingly relying on proprietary models for state-of-the-art reasoning while using more efficient and customizable open models to drive down costs. Routing tasks between frontier-level models and Nemotron in a single workflow gives agents the most intelligence while optimizing tokenomics.
“Perplexity is built on the idea that human curiosity will be amplified by accurate AI built into exceptional tools, like AI assistants,” said Aravind Srinivas, CEO of Perplexity. “With our agent router, we can direct workloads to the best fine-tuned open models, like Nemotron 3 Ultra, or leverage leading proprietary models when tasks benefit from their unique capabilities — ensuring our AI assistants operate with exceptional speed, efficiency and scale.”
The open Nemotron 3 models enable startups to build and iterate faster on AI agents and accelerate innovation from prototype to enterprise deployment. General Catalyst, Mayfield and Sierra Ventures’ portfolio companies are exploring Nemotron 3 to build AI teammates that support human-AI collaboration.
“NVIDIA’s open model stack and the NVIDIA Inception program give early-stage companies the models, tools and a cost-effective infrastructure to experiment, differentiate and scale fast,” said Navin Chaddha, managing partner at Mayfield. “Nemotron 3 gives founders a running start on building agentic AI applications and AI teammates, and helps them tap into NVIDIA’s massive installed base.”
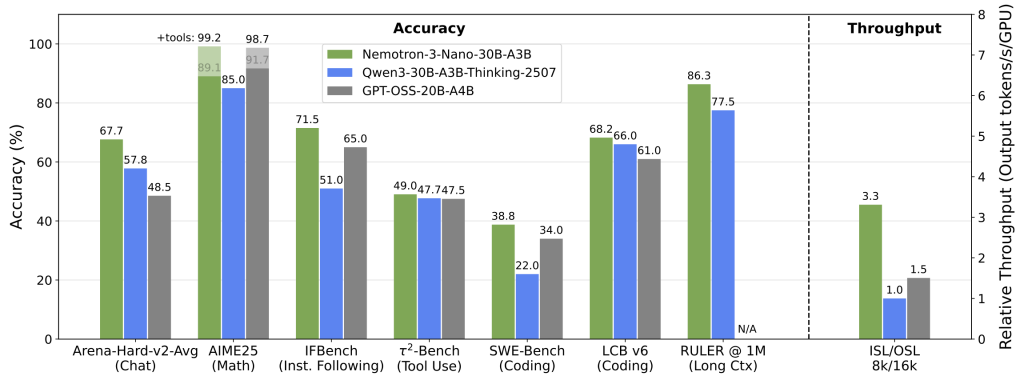
Main functions of Nemotron 3
- High-efficiency inference : The Nemotron 3 Nano boasts 30 billion parameters and achieves up to 4 times the throughput of its predecessor through a hybrid expert hybrid (MoE) architecture, significantly reducing inference costs.
- Multi-agent collaboration : The Nemotron 3 Super and Ultra have 100 billion and 500 billion parameters respectively, supporting complex multi-agent applications and handling tasks requiring deep reasoning and strategic planning.
- Long text processing capability : The Nemotron 3 Nano supports a context window of 1 million words, which can better handle long text tasks and maintain the coherence of information.
- High-precision inference : Through advanced reinforcement learning techniques and concurrent training in multiple environments, Nemotron 3 excels in accuracy.
Nemotron 3’s technical principles
- Hybrid Expert Hybrid (MoE) Architecture : The Nemotron 3 Nano employs a unique hybrid MoE architecture, which achieves higher throughput and lower inference costs while maintaining high computational efficiency by dynamically activating some parameters (such as up to 3 billion parameters activated at a time in the Nano model).
- Reinforcement learning and multi-environment training : The model is trained concurrently in multiple environments using advanced reinforcement learning techniques to improve the accuracy and adaptability of reasoning.
- Efficient training format : Nemotron 3 Super and Ultra use NVIDIA’s 4-bit NVFP4 training format, which significantly reduces memory requirements, accelerates the training process, and maintains accuracy comparable to high-precision formats.
- Large-scale pre-trained datasets : Provides pre-trained, post-trained, and reinforcement learning datasets containing 3 trillion tokens, offering rich examples of inference, coding, and multi-step workflows for models, supporting domain specialization.
Application scenarios of Nemotron 3
- Manufacturing : Nemotron 3 is used for production process optimization, equipment monitoring and fault prediction to improve production efficiency and automation levels.
- Cybersecurity : Nemotron 3 provides fast and accurate cybersecurity threat response through real-time analysis of network traffic and malware detection.
- Software development : Supports code generation, debugging, and automated testing, improving software development efficiency and quality.
- Media and Communications : Assisting content creation, editing, and intelligent customer service to improve media production efficiency and user experience.
- Financial services : Used for risk assessment, fraud detection, and investment advice to help financial institutions make accurate decisions.
Download #
NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 (safetensors): https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8/tree/main
NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 (safetensors): https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16/tree/main
NVIDIA-Nemotron-3-Nano-30B-A3B (GUFF): https://huggingface.co/lmstudio-community/NVIDIA-Nemotron-3-Nano-30B-A3B-GGUF/tree/main
Mistral AI – Mistral 3 (release date 2025-12-02) #
Website: https://mistral.ai/news/mistral-3
Huggingface: https://huggingface.co/mistralai
LM studio: https://lmstudio.ai/blog/lmstudio-v0.3.33
About #
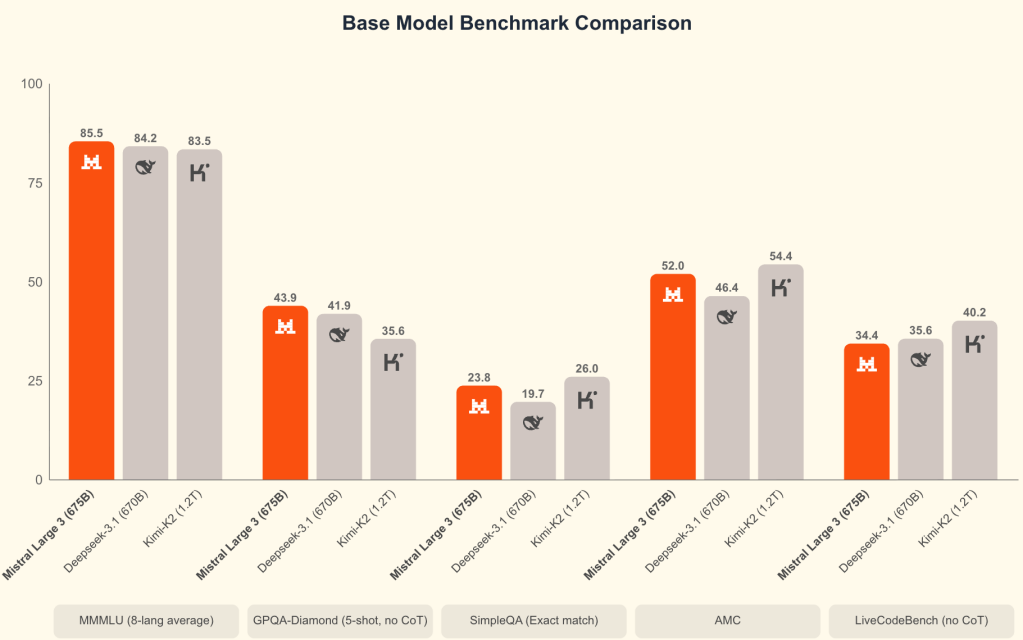
Today, we announce Mistral 3, the next generation of Mistral models. Mistral 3 includes three state-of-the-art small, dense models (14B, 8B, and 3B) and Mistral Large 3 – our most capable model to date – a sparse mixture-of-experts trained with 41B active and 675B total parameters. All models are released under the Apache 2.0 license. Open-sourcing our models in a variety of compressed formats empowers the developer community and puts AI in people’s hands through distributed intelligence.
The Ministral models represent the best performance-to-cost ratio in their category. At the same time, Mistral Large 3 joins the ranks of frontier instruction-fine-tuned open-source models.
For edge and local use cases, we release the Ministral 3 series, available in three model sizes: 3B, 8B, and 14B parameters. Furthermore, for each model size, we release base, instruct, and reasoning variants to the community, each with image understanding capabilities, all under the Apache 2.0 license. When married with the models’ native multimodal and multilingual capabilities, the Ministral 3 family offers a model for all enterprise or developer needs.
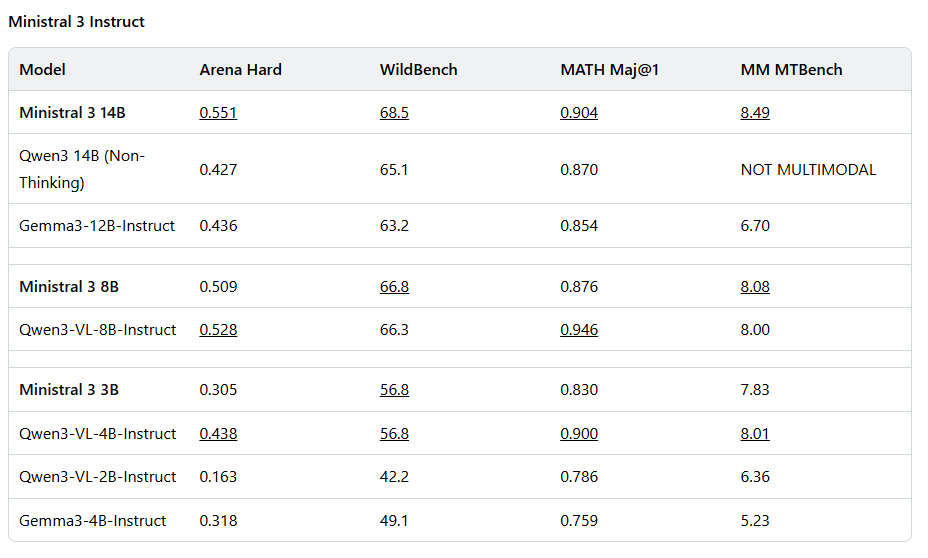
Furthermore, Ministral 3 achieves the best cost-to-performance ratio of any OSS model. In real-world use cases, both the number of generated tokens and model size matter equally. The Ministral instruct models match or exceed the performance of comparable models while often producing an order of magnitude fewer tokens.
For settings where accuracy is the only concern, the Ministral reasoning variants can think longer to produce state-of-the-art accuracy amongst their weight class – for instance 85% on AIME ‘25 with our 14B variant.
The Ministral 3 series is a family of open-weights models from MistralAI. These models were trained alongside Mistral’s larger Mistral-Large model, and they are available in three model sizes: 3B, 8B, and 14B parameters. These models support image understanding and multilingual capabilities, available under the Apache 2.0 license.
Ministral 3 achieves the best cost-to-performance ratio of any OSS model. In real-world use cases, both the number of generated tokens and model size matter equally. The Ministral instruct models match or exceed the performance of comparable models while often producing an order of magnitude fewer tokens.
Key Features
Ministral 3 8B consists of two main architectural components:
- 8.4B Language Model
- 0.4B Vision Encoder
The Ministral 3 8B Instruct model offers the following capabilities
- Vision: Enables the model to analyze images and provide insights based on visual content, in addition to text.
- Multilingual: Supports dozens of languages, including English, French, Spanish, German, Italian, Portuguese, Dutch, Chinese, Japanese, Korean, Arabic.
- System Prompt: Maintains strong adherence and support for system prompts.
- Agentic: Offers best-in-class agentic capabilities with native function calling and JSON outputting.
- Edge-Optimized: Delivers best-in-class performance at a small scale, deployable anywhere.
- Apache 2.0 License: Open-source license allowing usage and modification for both commercial and non-commercial purposes.
- Large Context Window: Supports a 256k context window.
Ministral 3 Instruct models offer the following capabilities:
- Vision: Enables the model to analyze images and provide insights based on visual content, in addition to text.
- Multilingual: Supports dozens of languages, including English, French, Spanish, German, Italian, Portuguese, Dutch, Chinese, Japanese, Korean, Arabic.
- System Prompt: Maintains strong adherence and support for system prompts.
- Agentic: Offers best-in-class agentic capabilities with native function calling and JSON outputting.
- Edge-Optimized: Delivers best-in-class performance at a small scale, deployable anywhere.
- Apache 2.0 License: Open-source license allowing usage and modification for both commercial and non-commercial purposes.
- Large Context Window: Supports a 256k context window.
Download #
Ministral-3-3B-Instruct-2512 (GUFF): https://huggingface.co/mistralai/Ministral-3-3B-Instruct-2512-GGUF/tree/main
Ministral-3-8B-Instruct-2512 (GUFF): https://huggingface.co/mistralai/Ministral-3-18B-Instruct-2512-GGUF/tree/main
Ministral-3-14B-Instruct-2512 (GUFF): https://huggingface.co/mistralai/Ministral-3-14B-Instruct-2512-GGUF/tree/main
Ministral-3-3B-Reasoning-2512 (GUFF): https://huggingface.co/mistralai/Ministral-3-3B-Reasoning-2512-GGUF/tree/main
Ministral-3-8B-Reasoning-2512 (GUFF): https://huggingface.co/mistralai/Ministral-3-8B-Reasoning-2512-GGUF/tree/main
Ministral-3-14B-Reasoning-2512 (GUFF): https://huggingface.co/mistralai/Ministral-3-14B-Reasoning-2512-GGUF/tree/main
NousResearch – Hermes 4.3 (release date 2025-12-02) #

Website: https://nousresearch.com/introducing-hermes-4-3
Huggingface: https://huggingface.co/NousResearch/Hermes-4.3-36B-GGUF
Hermes 4.3 – 36B Unleashed: A New Era of Decentralized and User-Aligned AI for Local Deployment:
https://markets.financialcontent.com/wral/article/tokenring-2025-12-6-hermes-43-36b-unleashed-a-new-era-of-decentralized-and-user-aligned-ai-for-local-deployment
About #
Model Description
Hermes 4.3 36B is a frontier, hybrid-mode reasoning model based on ByteDance Seed 36B base, made by Nous Research that is aligned to you.
This is our first Hermes model trained in a decentralized manner over the internet using Psyche, read the blog post: https://nousresearch.com/introducing-hermes-4-3/
Read the Hermes 4 technical report here: Hermes 4 Technical Report
Chat with Hermes in Nous Chat: https://chat.nousresearch.com
Training highlights include a newly synthesized post-training corpus emphasizing verified reasoning traces, massive improvements in math, code, STEM, logic, creativity, and format-faithful outputs, while preserving general assistant quality and broadly neutral alignment.
What’s new vs Hermes 3
- Post-training corpus: Massively increased dataset size from 1M samples and 1.2B tokens to ~5M samples / ~60B tokens blended across reasoning and non-reasoning data.
- Hybrid reasoning mode with explicit
<think>…</think>segments when the model decides to deliberate, and options to make your responses faster when you want. - Reasoning that is top quality, expressive, improves math, code, STEM, logic, and even creative writing and subjective responses.
- Schema adherence & structured outputs: trained to produce valid JSON for given schemas and to repair malformed objects.
- Much easier to steer and align: extreme improvements on steerability, especially on reduced refusal rates.
Our Mission: Frontier Capabilities Aligned to You
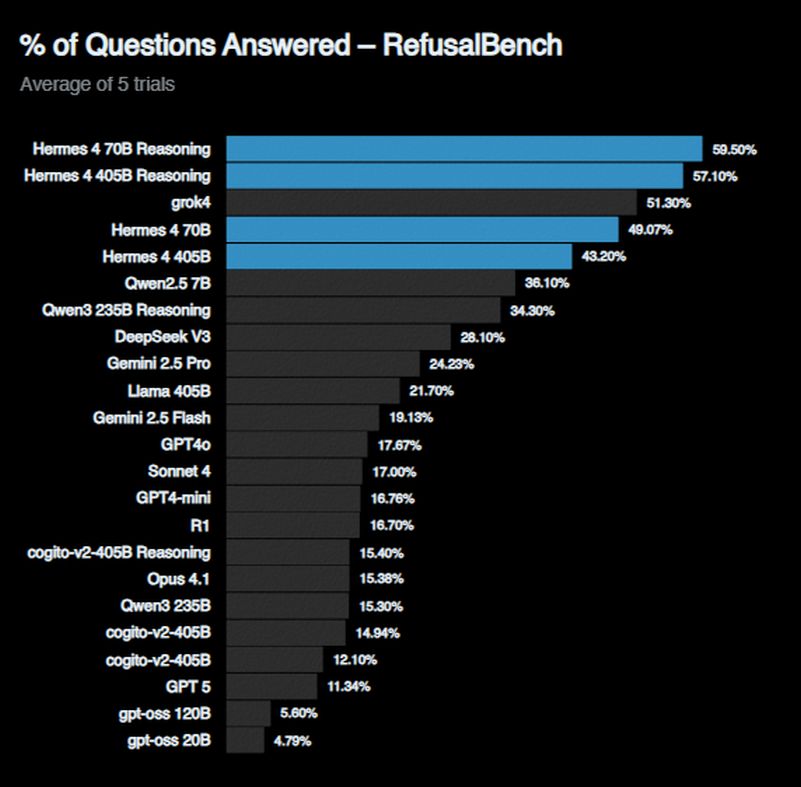
In pursuit of the mission of producing models that are open, steerable and capable of producing the full range of human expression, while being able to be aligned to your values, we created a new benchmark, RefusalBench, that tests the models willingness to be helpful in a variety of scenarios commonly disallowed by closed and open models.
Hermes 4.3 36B is now SOTA across non-abliterated models on the RefusalBench Leaderboard, surpassing our previous best of 59.5% on Hermes 4 70B

Download #
Hermes-4.3-36B-GGUF: https://huggingface.co/NousResearch/Hermes-4.3-36B-GGUF/tree/main
Allenai – OLMo 3 (release date 2025-11-20) #
Website: https://allenai.org/blog/olmo3
LM Studio: https://lmstudio.ai/models/olmo3
AllenAI’s OLMo 3 32B Think — The Best Fully Open-Source Reasoning Model: https://medium.com/@leucopsis/allenais-olmo-3-32b-think-the-best-fully-open-source-reasoning-model-b1d04a6a0010
About #
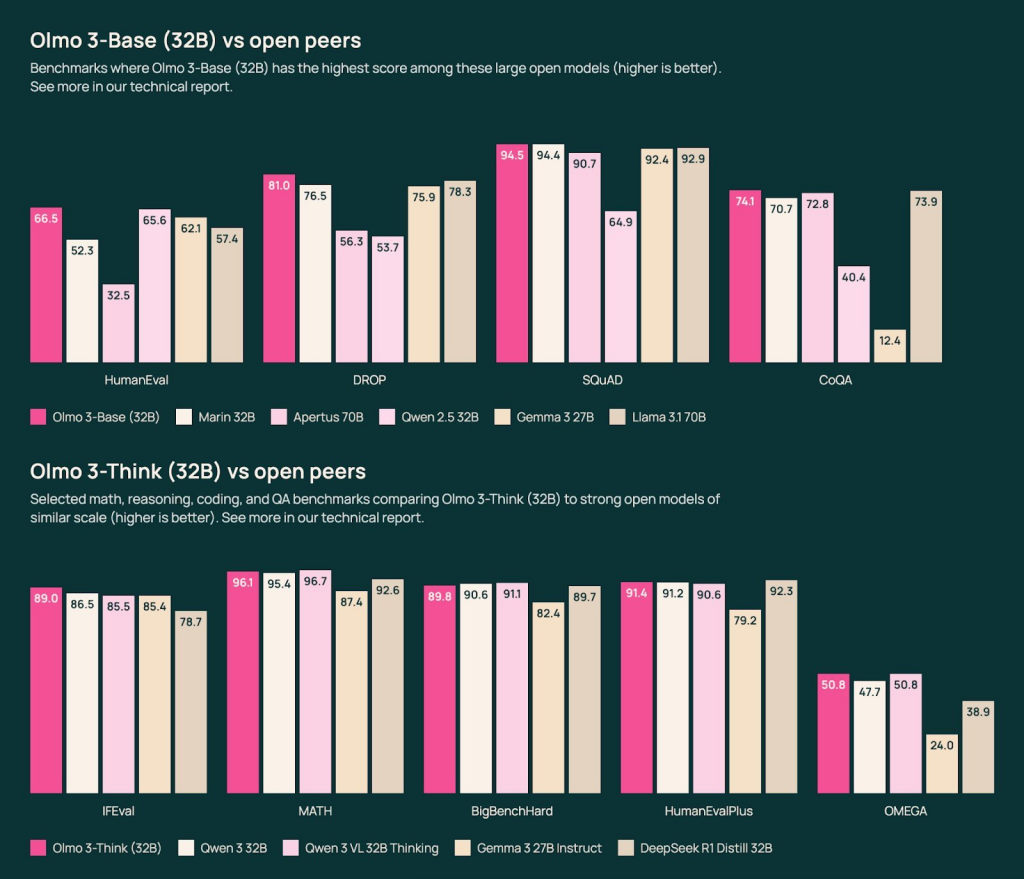
AllenAI introduces Olmo 3, a new family of 7B and 32B models. This suite includes Base, Instruct, and Think variants. The Base models were trained using a staged training approach.
Olmo is a series of Open language models designed to enable the science of language models. These models are trained on the Dolma 3 dataset. All code, checkpoints, and associated training details are released as open source artifacts.
Inference & Recommended Settings
We evaluated our models on the following settings. We also recommend using them for generation:
- temperature:
0.6 - top_p:
0.95 - max_tokens:
32768
| Size | Training Tokens | Layers | Hidden Size | Q Heads | KV Heads | Context Length |
|---|---|---|---|---|---|---|
| OLMo 3 7B | 5.93 Trillion | 32 | 4096 | 32 | 32 | 65,536 |
| OLMo 3 32B | 5.50 Trillion | 64 | 5120 | 40 | 8 | 65,536 |
Download #
Olmo-3-7B-Instruct (GUFF): https://huggingface.co/allenai/Olmo-3-7B-Instruct/tree/main
Olmo-3-7B-Think (GUFF): https://huggingface.co/allenai/Olmo-3-7B-Think/tree/main
Olmo-3-32B-Think (GUFF): https://huggingface.co/unsloth/Olmo-3-32B-Think-GGUF/tree/main
NousResearch – Hermes 4 (release date 2025-08-25) #

Website: https://hermes4.nousresearch.com
Huggingface: https://huggingface.co/bartowski/NousResearch_Hermes-4-14B-GGUF
Hermes 4 Unleashed: Nous Research’s Bold Bet on Uncensored AI Supremacy Over ChatGPT:
About #
Model Description
Hermes 4 14B is a frontier, hybrid-mode reasoning model based on Qwen 3 14B by Nous Research that is aligned to you.
Read the Hermes 4 technical report here: Hermes 4 Technical Report
Chat with Hermes in Nous Chat: https://chat.nousresearch.com
Training highlights include a newly synthesized post-training corpus emphasizing verified reasoning traces, massive improvements in math, code, STEM, logic, creativity, and format-faithful outputs, while preserving general assistant quality and broadly neutral alignment.
What’s new vs Hermes 3
- Post-training corpus: Massively increased dataset size from 1M samples and 1.2B tokens to ~5M samples / ~60B tokens blended across reasoning and non-reasoning data.
- Hybrid reasoning mode with explicit
<think>…</think>segments when the model decides to deliberate, and options to make your responses faster when you want. - Reasoning that is top quality, expressive, improves math, code, STEM, logic, and even creative writing and subjective responses.
- Schema adherence & structured outputs: trained to produce valid JSON for given schemas and to repair malformed objects.
- Much easier to steer and align: extreme improvements on steerability, especially on reduced refusal rates.
Our Mission: Frontier Capabilities Aligned to You
In pursuit of the mission of producing models that are open, steerable and capable of producing the full range of human expression, while being able to be aligned to your values, we created a new benchmark, RefusalBench, that tests the models willingness to be helpful in a variety of scenarios commonly disallowed by closed and open models.
Download #
Hermes-4-14B-GGUF: https://huggingface.co/bartowski/NousResearch_Hermes-4-14B-GGUF/tree/main
Alibaba – Qwen3 (release date 2025-04-28) #
Website: https://qwenlm.github.io/blog/qwen3
Qwen 3 Breakdown: What’s New & How It Performs: https://www.labellerr.com/blog/qwen-3
About #
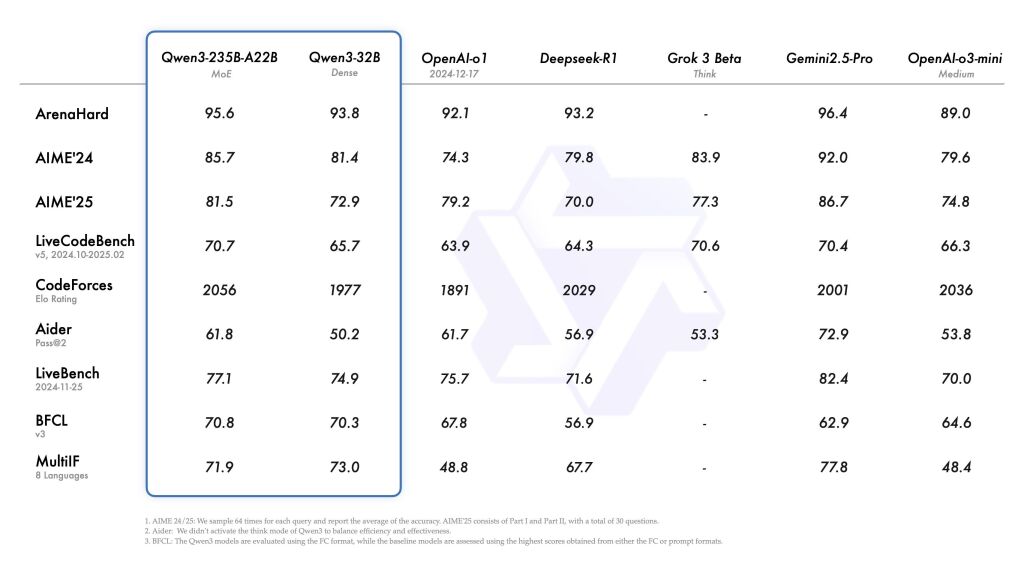
Today, we are excited to announce the release of Qwen3, the latest addition to the Qwen family of large language models. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.5-72B-Instruct.
We are open-weighting two MoE models: Qwen3-235B-A22B, a large model with 235 billion total parameters and 22 billion activated parameters, and Qwen3-30B-A3B, a smaller MoE model with 30 billion total parameters and 3 billion activated parameters. Additionally, six dense models are also open-weighted, including Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B, under Apache 2.0 license.
The post-trained models, such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, we recommend using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended. These options ensure that users can easily integrate Qwen3 into their workflows, whether in research, development, or production environments.
We believe that the release and open-sourcing of Qwen3 will significantly advance the research and development of large foundation models. Our goal is to empower researchers, developers, and organizations around the world to build innovative solutions using these cutting-edge models.
Download #
Qwen3-8B (GGUF): https://huggingface.co/lmstudio-community/Qwen3-8B-GGUF
Qwen3-14B (GGUF): https://huggingface.co/lmstudio-community/Qwen3-14B-GGUF
Qwen3-32B (GGUF): https://huggingface.co/lmstudio-community/Qwen3-32B-GGUF
Qwen3-Next-80B-A3B-Instruct (GGUF): https://huggingface.co/unsloth/Qwen3-Next-80B-A3B-Instruct-GGUF/tree/main
DeepSeek – DeepSeek V3-0324 (release date 2025-03-24) #
About #
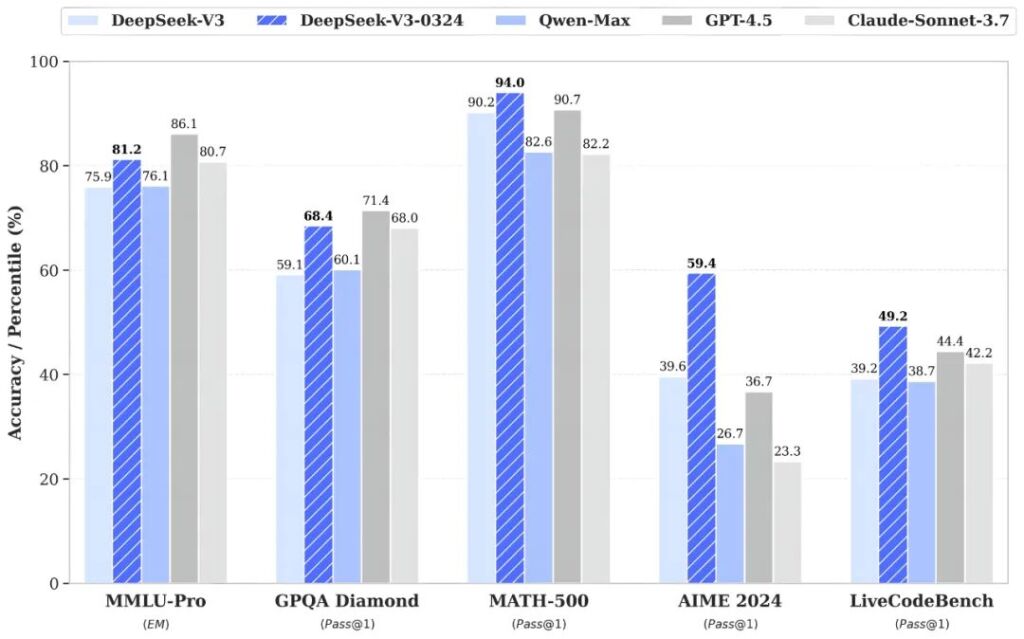
DeepSeek-V3-0324 demonstrates notable improvements over its predecessor,
Reasoning Capabilities
- Significant improvements in benchmark performance:
- MMLU-Pro: 75.9 → 81.2 (+5.3)
- GPQA: 59.1 → 68.4 (+9.3)
- AIME: 39.6 → 59.4 (+19.8)
- LiveCodeBench: 39.2 → 49.2 (+10.0)
- Improved the executability of the code
- More aesthetically pleasing web pages and game front-ends
Chinese Writing Proficiency
- Enhanced style and content quality:
- Aligned with the R1 writing style
- Better quality in medium-to-long-form writing
- Feature Enhancements
- Improved multi-turn interactive rewriting
- Optimized translation quality and letter writing
Chinese Search Capabilities
- Enhanced report analysis requests with more detailed outputs
- Increased accuracy in Function Calling, fixing issues from previous V3 versions
Download #
DeepSeek-V3-0324 (GUFF): https://huggingface.co/unsloth/DeepSeek-V3-0324-GGUF/tree/main
Google – Gemma 3 (release date 2025-03-12) #
Website: https://deepmind.google/models/gemma/gemma-3
Gemma 3: How to Run & Fine-tune: https://docs.unsloth.ai/models/gemma-3-how-to-run-and-fine-tune
About #
Gemma is a series of open-source large language models developed by Google DeepMind. It is based on similar technologies as Gemini. The first version was released in February 2024, followed by Gemma 2 in June 2024 and Gemma 3 in March 2025. Variants of Gemma have also been developed, such as the vision-language model PaliGemma and the model MedGemma for medical consultation topics.
Capabilities
- Handle complex tasks: Gemma 3’s 128K-token context window lets your applications process and understand vast amounts of information, enabling more sophisticated AI features.
- Multilingual communication: Unparalleled multilingual capabilities let you communicate effortlessly across countries and cultures. Develop applications that reach a global audience, with support for over 140 languages.
- Multimodal understanding: Easily build applications that analyze images, text, and video opening up new possibilities for interactive and intelligent applications.
270M – Compact model designed for both task-specific fine-tuning and strong instruction-following.
1B – Lightweight text model, ideal for small applications.
4B – Balanced for performance and flexibility, with multimodal support.
12B – Strong language capabilities, designed for complex tasks.
27B- Enhanced understanding, great for sophisticated applications.
Download #
gemma-3-270m-it (GUFF): https://huggingface.co/unsloth/gemma-3-270m-it-GGUF/tree/main
gemma-3-1b-it (GUFF): https://huggingface.co/unsloth/gemma-3-1b-it-GGUF/tree/main
gemma-3-4b-it (GUFF): https://huggingface.co/unsloth/gemma-3-4b-it-GGUF/tree/main
gemma-3-12b-it (GUFF): https://huggingface.co/unsloth/gemma-3-12b-it-GGUF/tree/main
gemma-3-27b-it (GUFF): https://huggingface.co/unsloth/gemma-3-27b-it-GGUF/tree/main
DeepSeek – DeepSeek R1 (release date 2025-01-20) #
About #
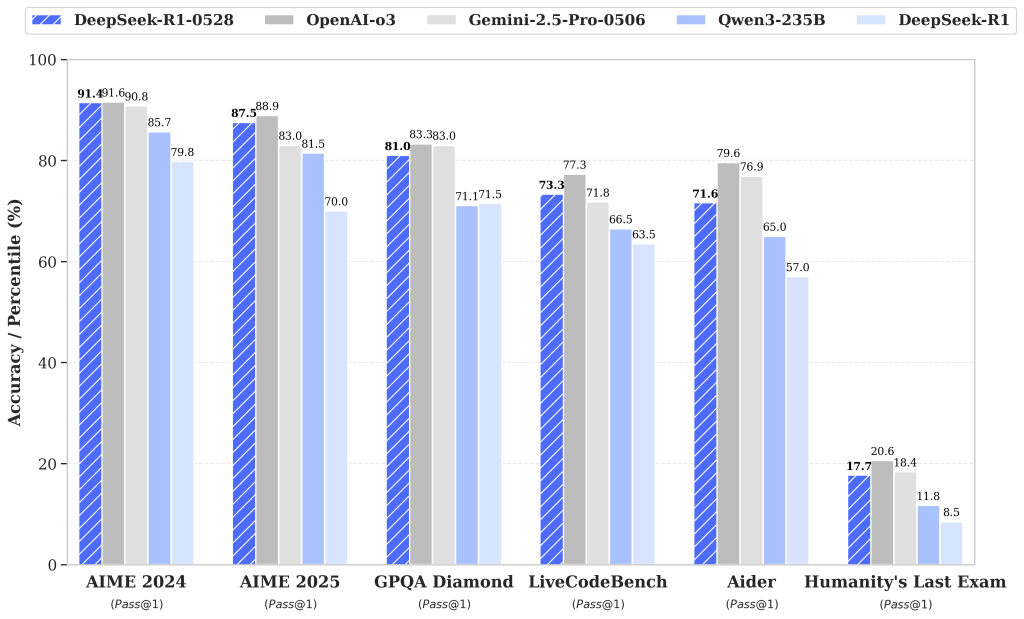
The DeepSeek R1 model has undergone a minor version upgrade, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
Download #
deepseek-r1-0528-qwen3-8b (GUFF): https://huggingface.co/samuelchristlie/DeepSeek-R1-0528-Qwen3-8B-GGUF
Microsoft – PHI4 (release date 2024-12-28) #
Website: https://azure.microsoft.com/en-us/products/phi/
Huggingface: https://huggingface.co/microsoft/phi-4
About #
Model Summary
| Developers | Microsoft Research |
| Description | phi-4 is a state-of-the-art open model built upon a blend of synthetic datasets, data from filtered public domain websites, and acquired academic books and Q&A datasets. The goal of this approach was to ensure that small capable models were trained with data focused on high quality and advanced reasoning.phi-4 underwent a rigorous enhancement and alignment process, incorporating both supervised fine-tuning and direct preference optimization to ensure precise instruction adherence and robust safety measures |
| Architecture | 14B parameters, dense decoder-only Transformer model |
| Inputs | Text, best suited for prompts in the chat format |
| Context length | 16K tokens |
| GPUs | 1920 H100-80G |
| Training time | 21 days |
| Training data | 9.8T tokens |
| Outputs | Generated text in response to input |
| Dates | October 2024 – November 2024 |
| Status | Static model trained on an offline dataset with cutoff dates of June 2024 and earlier for publicly available data |
| Release date | December 12, 2024 |
| License | MIT |
Intended Use
| Primary Use Cases | Our model is designed to accelerate research on language models, for use as a building block for generative AI powered features. It provides uses for general purpose AI systems and applications (primarily in English) which require: 1. Memory/compute constrained environments. 2. Latency bound scenarios. 3. Reasoning and logic. |
| Out-of-Scope Use Cases | Our models is not specifically designed or evaluated for all downstream purposes, thus: 1. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fairness before using within a specific downstream use case, particularly for high-risk scenarios. 2. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case, including the model’s focus on English. 3. Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under. |
Training Datasets
Our training data is an extension of the data used for Phi-3 and includes a wide variety of sources from:
- Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code.
- Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.).
- Acquired academic books and Q&A datasets.
- High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
Multilingual data constitutes about 8% of our overall data. We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge.
Benchmark datasets
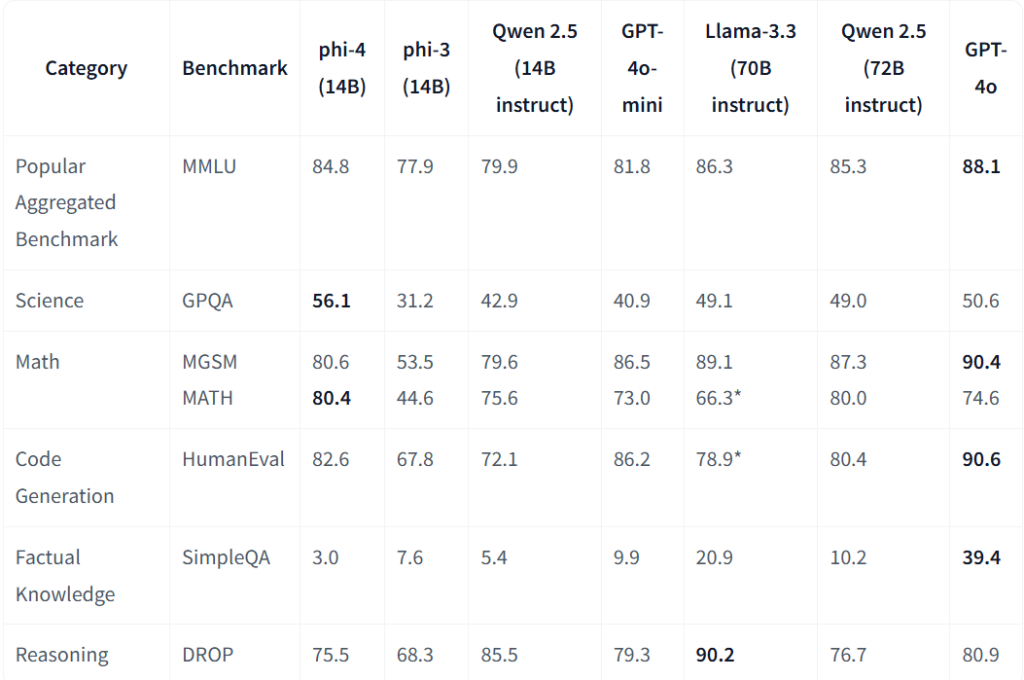
We evaluated phi-4 using OpenAI’s SimpleEval and our own internal benchmarks to understand the model’s capabilities, more specifically:
- MMLU: Popular aggregated dataset for multitask language understanding.
- MATH: Challenging competition math problems.
- GPQA: Complex, graduate-level science questions.
- DROP: Complex comprehension and reasoning.
- MGSM: Multi-lingual grade-school math.
- HumanEval: Functional code generation.
- SimpleQA: Factual responses.
phi-4 has adopted a robust safety post-training approach. This approach leverages a variety of both open-source and in-house generated synthetic datasets. The overall technique employed to do the safety alignment is a combination of SFT (Supervised Fine-Tuning) and iterative DPO (Direct Preference Optimization), including publicly available datasets focusing on helpfulness and harmlessness as well as various questions and answers targeted to multiple safety categories.
Safety Evaluation and Red-Teaming
Prior to release, phi-4 followed a multi-faceted evaluation approach. Quantitative evaluation was conducted with multiple open-source safety benchmarks and in-house tools utilizing adversarial conversation simulation. For qualitative safety evaluation, we collaborated with the independent AI Red Team (AIRT) at Microsoft to assess safety risks posed by phi-4 in both average and adversarial user scenarios. In the average user scenario, AIRT emulated typical single-turn and multi-turn interactions to identify potentially risky behaviors. The adversarial user scenario tested a wide range of techniques aimed at intentionally subverting the model’s safety training including jailbreaks, encoding-based attacks, multi-turn attacks, and adversarial suffix attacks.
Please refer to the technical report for more details on safety alignment.
Model Quality
To understand the capabilities, we compare phi-4 with a set of models over OpenAI’s SimpleEval benchmark.
At the high-level overview of the model quality on representative benchmarks. For the table below, higher numbers indicate better performance:
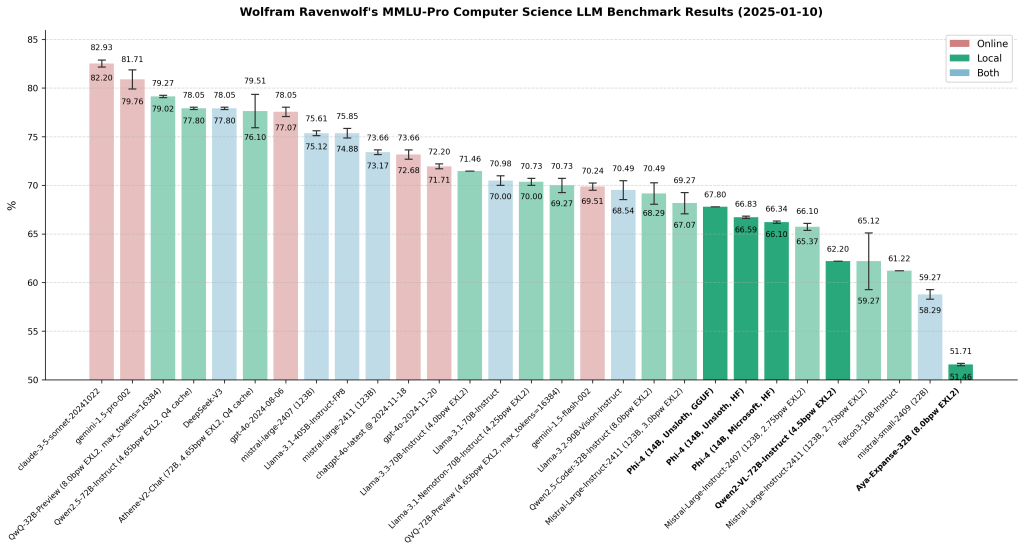
Download #
Phi-4 (GUFF): https://huggingface.co/microsoft/phi-4-gguf/tree/main
Alibaba – Qwen2.5 (release date 2024-09-30) #
Website: https://qwenlm.github.io/blog/qwen2.5-max
Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model: https://qwenlm.github.io/blog/qwen2.5-max
About #
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2:
Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.
- Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.
- Long-context Support up to 128K tokens and can generate up to 8K tokens.
- Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
This repo contains the instruction-tuned 7B Qwen2.5 model, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 7.61B
- Number of Paramaters (Non-Embedding): 6.53B
- Number of Layers: 28
- Number of Attention Heads (GQA): 28 for Q and 4 for KV
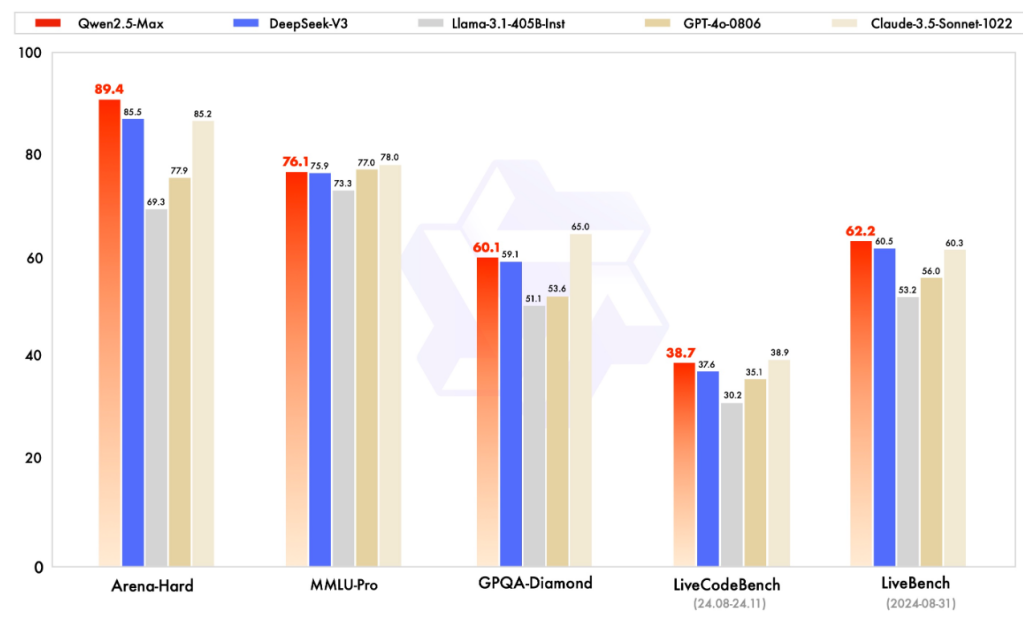
Download #
Qwen2.5-3B-Instruct (GGUF): https://huggingface.co/Qwen/Qwen2.5-3B-Instruct-GGUF/tree/main
Qwen2.5-7B-Instruct (GGUF): https://huggingface.co/Qwen/Qwen2.5-7B-Instruct-GGUF/tree/main
Qwen2.5-14B-Instruct (GGUF): https://huggingface.co/bartowski/Qwen2.5-14B-Instruct-GGUF/tree/main
Mistral AI – Mistral 7B (release date 2024-05-27) #

Website: https://mistral.ai/news/announcing-mistral-7b
About #
Mistral-7B-Instruct v0.3 is de nieuwste verfijnde instructie-variant van het Mistral-7B-model, ontworpen om efficiënter, verstandiger en betrouwbaarder te reageren in real-world toepassingen. Mistral 7B behoort tot de huidige generatie “kleine-maar-krachtige” open modellen: compact genoeg om lokaal te draaien op consumenten hardware, maar met prestaties die verrassend dicht in de buurt komen van veel grotere modellen.
De v0.3-instructversie is specifiek getraind en geoptimaliseerd om gebruikersopdrachten te begrijpen, clean te antwoorden, context te volgen, en veiliger met ambigue of complexe vragen om te gaan. Het model staat bekend om zijn snelle inference, lage VRAM-eisen, en solide reasoning binnen zijn grootteklasse.
Modeloverzicht
- Naam: Mistral-7B-Instruct v0.3
- Grootte: 7 miljard parameters
- Type: Instructiefinetune (gespecialiseerd op menselijke prompts)
- Formaat beschikbaar: GGUF, safetensors, HF transformers
- Doel: Chat, Q&A, tool-use, reasoning, compacte AI-assistentie
Performance & Sterktes
- Verbeterde instruction following t.o.v. v0.2
Begrijpt opdrachten beter, werkt consistenter en volgt formatting nauwkeuriger. - Sterk in redeneren binnen 7B-klasse
Goede balans tussen snelheid en logica; vaak beter dan Llama-2-7B en Gemma-7B. - Snelle inference
Zeer geschikt voor CPU-gebruik, kleinere GPU’s en zelfs sommige edge-devices. - Grote context windows (afhankelijk van build)
Geschikt voor RAG-systemen, document-samenvattingen en langere gesprekken.
Download #
Mistral-7B-Instruct-v0.3 (GUFF): https://huggingface.co/MaziyarPanahi/Mistral-7B-Instruct-v0.3-GGUF
Microsoft – PHI3 (release date 2024-04-23) #
Website: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct
Introducing Phi-3: Redefining what’s possible with SLMs: https://azure.microsoft.com/en-us/blog/introducing-phi-3-redefining-whats-possible-with-slms/
About #
We are excited to introduce Phi-3, a family of open AI models developed by Microsoft. Phi-3 models are the most capable and cost-effective small language models (SLMs) available, outperforming models of the same size and next size up across a variety of language, reasoning, coding, and math benchmarks. This release expands the selection of high-quality models for customers, offering more practical choices as they compose and build generative AI applications.
Starting today, Phi-3-mini, a 3.8B language model is available on Microsoft Azure AI Studio, Hugging Face, and Ollama.
- Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
- It is instruction-tuned, meaning that it’s trained to follow different types of instructions reflecting how people normally communicate. This ensures the model is ready to use out-of-the-box.
- It is available on Azure AI to take advantage of the deploy-eval-finetune toolchain, and is available on Ollama for developers to run locally on their laptops.
- It has been optimized for ONNX Runtime with support for Windows DirectML along with cross-platform support across graphics processing unit (GPU), CPU, and even mobile hardware.
- It is also available as an NVIDIA NIM microservice with a standard API interface that can be deployed anywhere. And has been optimized for NVIDIA GPUs.
In the coming weeks, additional models will be added to Phi-3 family to offer customers even more flexibility across the quality-cost curve. Phi-3-small (7B) and Phi-3-medium (14B) will be available in the Azure AI model catalog and other model gardens shortly.
Microsoft continues to offer the best models across the quality-cost curve and today’s Phi-3 release expands the selection of models with state-of-the-art small models.
Groundbreaking performance at a small size
Phi-3 models significantly outperform language models of the same and larger sizes on key benchmarks (see benchmark numbers below, higher is better). Phi-3-mini does better than models twice its size, and Phi-3-small and Phi-3-medium outperform much larger models, including GPT-3.5T.
All reported numbers are produced with the same pipeline to ensure that the numbers are comparable. As a result, these numbers may differ from other published numbers due to slight differences in the evaluation methodology. More details on benchmarks are provided in our technical paper.
Note: Phi-3 models do not perform as well on factual knowledge benchmarks (such as TriviaQA) as the smaller model size results in less capacity to retain facts.
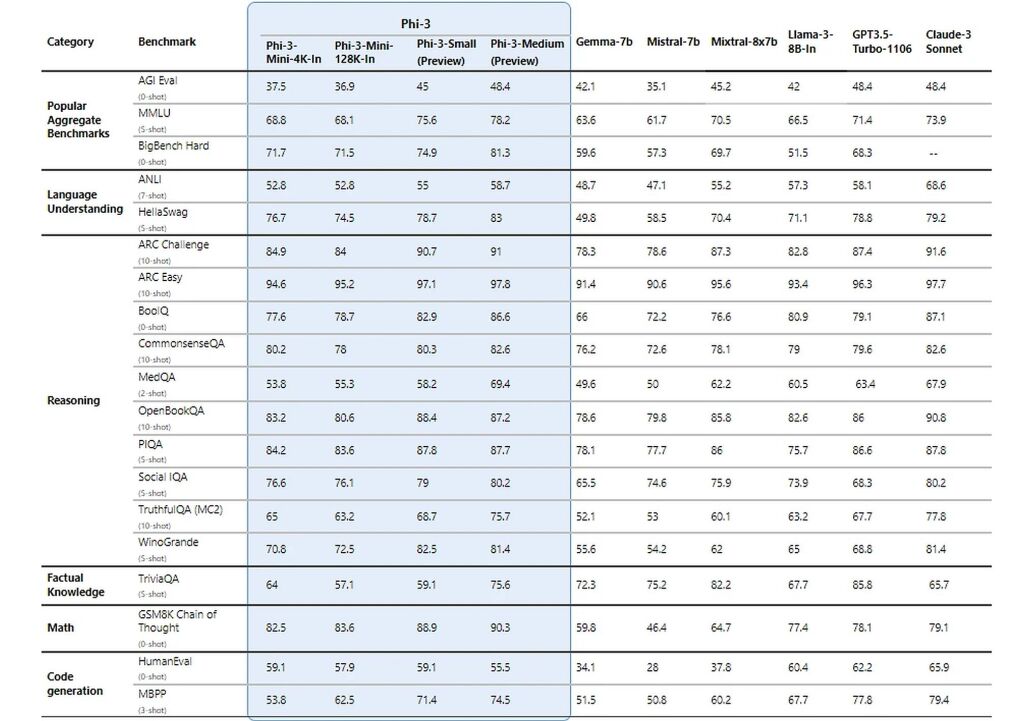
Download #
Phi-3-mini-4k-instruct (GUFF): https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/tree/main
Meta – Llama 3 (release date 2024-04-18) #
Website: https://www.llama.com/models/llama-3
Llama 3 Guide: Everything You Need to Know About: https://kili-technology.com/blog/llama-3-guide-everything-you-need-to-know-about-meta-s-new-model-and-its-data
About #
In April 2024, Meta released Llama 3, a large language model touted to be more powerful and diverse than its predecessors, Llama 1 and 2. The family of models has a 70b parameter and a smaller 8b parameter version, both of which have instruction-tuned versions as well. One way Llama 3 is set apart from other large language models, like Claude, Gemini, and GPT, is that Meta has released the model as open source – which means it is available for research and commercial purposes. However, the license is custom and requires that users adhere to specific regulations to avoid misuse.Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
Model developers Meta
Variations Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
Input Models input text only.
Output Models generate text and code only.
Model Architecture Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
| Training Data | Params | Context length | GQA | Token count | Knowledge cutoff | |
| Llama 3 | A new mix of publicly available online data. | 8B | 8k | Yes | 15T+ | March, 2023 |
| 70B | 8k | Yes | December, 2023 |
Llama 3 family of models. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
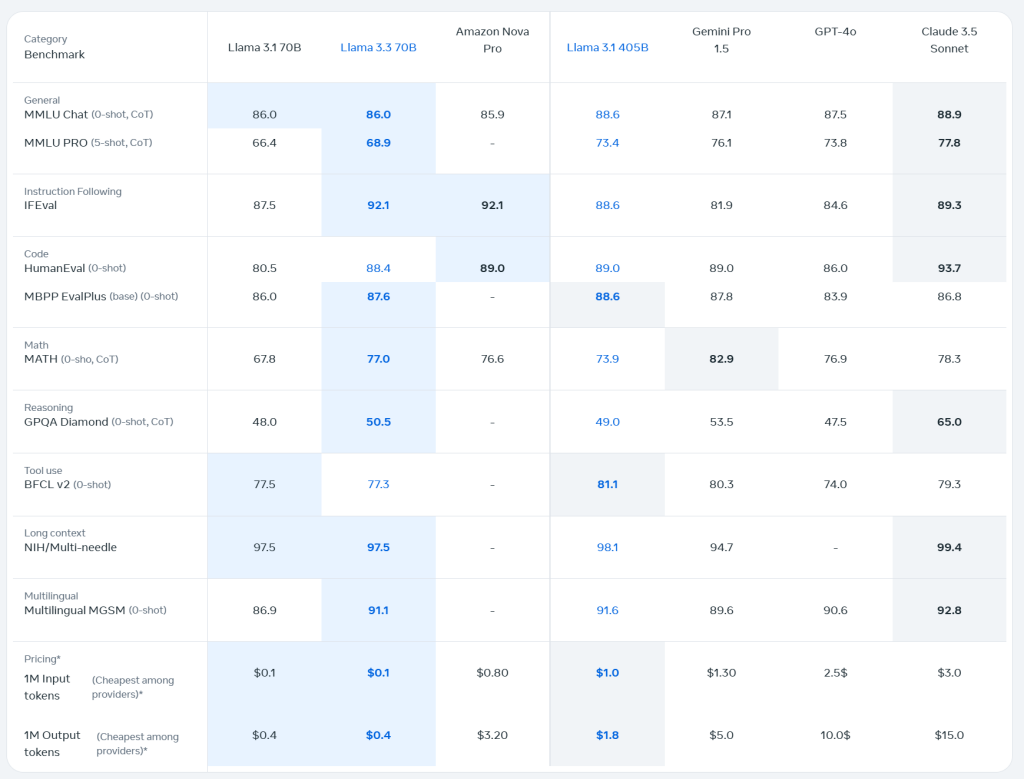
LLAMA 3 (april 2024)
Officiële release.
- Modellen: Llama-3-8B, Llama-3-70B, later ook instruct-tuned versies.
- Grote sprong ten opzichte van Llama 2 in:
- reasoning
- code
- taalbegrip
- natural chat
- Redelijk efficiënt, maar nog niet extreem geoptimaliseerd.
- Zeer wijd gebruikt in AI-ontwikkelingen van 2024.
Gebruik: algemene assistenten, chatbots, code, reasoning.
LLAMA 3.1 (juli 2024)
Officiële update van Meta.
En dé grote mainstream upgrade voor lokale en enterprise LLM’s.
- Modellen: 3.1-8B, 3.1-70B, 3.1-405B (!).
- Verbeteringen:
- Veel betere veiligheid + instruct-following
- Betere tool calling
- Betere lange context (128k context)
- Sterkere logica, wiskunde, codegeneratie
- Efficientere inference (hardware-optimalisaties)
- Meer stabiliteit bij API-gebruik en agents.
Gebruik:
Perfect voor n8n, LM Studio, agents, RAG, code, reasoning.
Download #
Meta-Llama-3-8B (GUFF): https://huggingface.co/QuantFactory/Meta-Llama-3-8B-GGUF/tree/main
Meta-Llama-3.1-8B (GUFF): https://huggingface.co/bartowski/Meta-Llama-3.1-8B-Instruct-GGUF/tree/main
Microsoft – PHI1.5 (release date 2023-09-24) #
Website: https://huggingface.co/microsoft/phi-1_5
Phi-1.5 Model: A Case of Comparing Apples to Oranges?: https://pratyushmaini.github.io/phi-1_5
About #
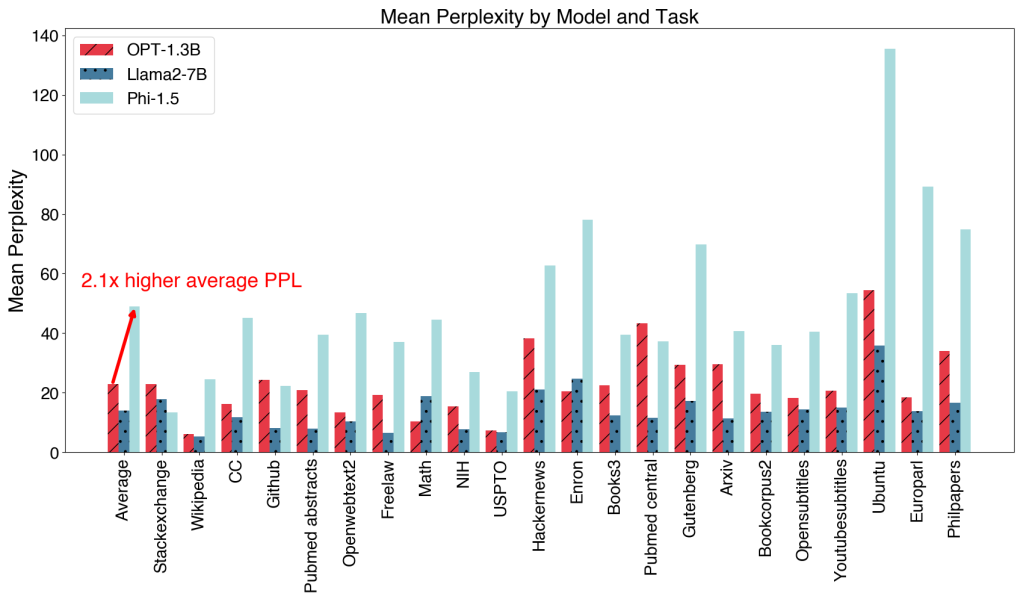
The language model Phi-1.5 is a Transformer with 1.3 billion parameters. It was trained using the same data sources as phi-1, augmented with a new data source that consists of various NLP synthetic texts. When assessed against benchmarks testing common sense, language understanding, and logical reasoning, Phi-1.5 demonstrates a nearly state-of-the-art performance among models with less than 10 billion parameters.
We did not fine-tune Phi-1.5 either for instruction following or through reinforcement learning from human feedback. The intention behind crafting this open-source model is to provide the research community with a non-restricted small model to explore vital safety challenges, such as reducing toxicity, understanding societal biases, enhancing controllability, and more.
For a safer model release, we exclude generic web-crawl data sources such as common-crawl from the training. This strategy prevents direct exposure to potentially harmful online content, enhancing the model’s safety without RLHF. However, the model is still vulnerable to generating harmful content. We hope the model can help the research community to further study the safety of language models.
Phi-1.5 can write poems, draft emails, create stories, summarize texts, write Python code (such as downloading a Hugging Face transformer model), etc.
Download #
phi-1_5 (GUFF): https://huggingface.co/TKDKid1000/phi-1_5-GGUF/tree/main