Knowledge Center
Extra context LLM met SentenceTransformers mini-RAG (Linux/WSL python)
Je eigen LLM model met recente context? of extra informatie van een product of project?… of gewoon erg goed in het antwoorden van Q&A vragen van jou business?
Yes!, je kan extra context toevoegen aan je LLM model, zodat hij gaat antwoorden met extra informatie die jij hem gegeven hebt! Zo heb je je eigen google zoekmachine binnen in een LLM omgeving!
Het is mogelijk een LLM model extra context te geven van de gestelde vraag, dat kan bijvoorbeeld door extra informatie te indexerenmet een ScentenceTransformer. Het indexeren van informatie geeft een soort context add-on voor je LLM model, het is daardoor mogelijk je model te voeden met recentere informatie dan dat hetzelf bevat.
Wat doen SentenceTransformers in een mini-RAG?
In een mini-RAG (Retrieval-Augmented Generation) gebruiken we SentenceTransformers om teksten om te zetten in getallenreeksen, zogenaamde embeddings.
Deze embeddings maken het mogelijk om snel te zoeken naar stukken tekst die inhoudelijk lijken op een vraag van de gebruiker.
Simpel uitgelegd
- SentenceTransformers maakt van elke tekst een “betekenis-vector”.
- Die vectors komen in een vector database (bijv. FAISS of Chroma).
- Als de gebruiker een vraag stelt, wordt die vraag óók omgezet in een vector.
- De mini-RAG zoekt welke documenten het meest lijken op die vraag.
- Die relevante stukjes tekst worden aan het LLM gegeven om een beter antwoord te formuleren.
Waarom dit nuttig is:
Werkt perfect lokaal, zelfs met kleine modellen
Veel betere antwoorden dan het model alleen
Supersnel en lichtgewicht
SentenceTransformers #

Introductie (ENG) #
Sentence Transformers (a.k.a. SBERT) is the go-to Python module for accessing, using, and training state-of-the-art embedding and reranker models. It can be used to compute embeddings using Sentence Transformer models (quickstart), to calculate similarity scores using Cross-Encoder (a.k.a. reranker) models (quickstart), or to generate sparse embeddings using Sparse Encoder models (quickstart). This unlocks a wide range of applications, including semantic search, semantic textual similarity, and paraphrase mining.
A wide selection of over 10,000 pre-trained Sentence Transformers models are available for immediate use on Hugging Face, including many of the state-of-the-art models from the Massive Text Embeddings Benchmark (MTEB) leaderboard. Additionally, it is easy to train or finetune your own embedding models, reranker models, or sparse encoder models using Sentence Transformers, enabling you to create custom models for your specific use cases.
Voorbereiding (Linux / WSL) #
WSL #
WSL is een (ubuntu) Linux omgeving in Windows, deze kan men installeren via de APP store.
Zit je in een (verse) WSL prompt dan moet men eerst nog PIP (python package manager) en VENV (python virtual environment) installeren:
sudo apt install -y python3-pip python3-venvVENV aanmaken #
Python werkt tegenwoordig met virtual environments om conflicten met bibliotheken tegen te gaan en uit te sluiten.
Maak een virtual environment aan met het commando:
python3 -m venv ~/venven activeer deze:
source ~/venv/bin/activatellama-cpp-python #
Eenmaal binnen je VENV installeer llama-cpp-python om GUFF modellen te gebruiken.
pip3 install llama-cpp-pythonHet je een nVidia videokaart? of CUDA cores beschikbaar? (bv het nVidia Jetson platform), gebruik dan:
pip3 install llama-cpp-python[cuda]Extra dependencies #
Er zijn een aantal extra software pakketten nodig om diverse bestandformaten te kunnen omzetten naar leesbare tekst voor de mini-RAG
pip3 install sentence-transformers llama-cpp-python docx2txt pypdf beautifulsoup4 lxml html5lib pypandoc feedparsersudo apt-get install pandoFolders aanmaken #
Maak een docs map aan voor de bestanden om de inhoud te analyseren voor de index en een map voor het model in je WSL home folder:
cd ~/
sudo mkdir docs
sudo mkdir paraphrase-multilingual-MiniLM-L12-v2
sudo mkdir paraphrase-multilingual-MiniLM-L12-v2/1_PoolingDe SentenceTransformer #
In dit voorbeeld gebruiken we een “standaard” Sentence transformer genaamd: paraphrase-multilingual-MiniLM-L12-v2
Het model staat hier op huggingface: https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
Wat is paraphrase-multilingual-MiniLM-L12-v2? #
paraphrase-multilingual-MiniLM-L12-v2 is een lichte, supersnelle SentenceTransformer die teksten omzet in betekenisvolle embeddings.
Het model ondersteunt meer dan 50 talen, waaronder Nederlands, Engels, Duits, Frans en Spaans.
Het is speciaal getraind om betekenisgelijkenis te herkennen:
- teksten vergelijken
- dubbele of overlappende content herkennen
- vragen koppelen aan relevante documenten
- semantische zoekopdrachten uitvoeren
Dankzij het compacte MiniLM-ontwerp draait het model moeiteloos lokaal op CPU, waardoor het ideaal is voor mini-RAG, zoekfuncties, chatbots en documentmatching in meertalige omgevingen.
De SentenceTransformer downloaden #
paraphrase-multilingual-MiniLM-L12-v2 safetensors: https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2/tree/main
Download deze bestanden van huggingface plaats deze in de map genaamd paraphrase-multilingual-MiniLM-L12-v2 in de WSL home folder.
home\
paraphrase-multilingual-MiniLM-L12-v2\
1_Pooling\
config.json
tokenizer_config.json
tokenizer.json
special_tokens_map.json
README.md
modules.json
model.safetensors
config_sentence_transformers.json
config.jsonps je kan gemakkelijk via de Windows explorer naar de WSL home folder:
\\wsl.localhost\Ubuntu\home\(en dan door naar de map van de gebruiker van het systeem)
Teksten analyseren en vectoriseren #
Plaats bijvoorbeeld een aantal tekst bestanden (extensie .txt) met informatie in de docs/ folder
(Ik heb zelf als voorbeeld de troonreden van afgelopen jaren en de RSS feed van Joe Rogan erin gezet)
Onderstaande script (llm_rag.py) om te vectoriseren heb ik samen met ChatGPT gemaakt en gefinetuned, het gebruik:
usage: llm_rag.py [-h] [--build] [--search SEARCH]
RAG build & search (hiërarchisch) CLI
options:
-h, --help show this help message and exit
--build Bouw RAG-index (rag_index.npz)
--search SEARCH Zoekvraag / onderwerp voor RAG-zoekactie#!/usr/bin/env python3
"""
llm_rag.py
Commandline RAG-tool:
- Bouw index:
python3 llm_rag.py --build
- Zoek in index:
python3 llm_rag.py --search "mijn vraag of onderwerp"
Indexbestand: rag_index.npz
Zo gebruikt je REPL dezelfde index als deze CLI-tool.
"""
import os
import glob
import re
from typing import List, Tuple, Dict, Any
import numpy as np
from sentence_transformers import SentenceTransformer
import docx2txt
from pypdf import PdfReader
from bs4 import BeautifulSoup
import feedparser
# ========= CONFIG =========
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
DOCS_FOLDER = os.path.join(SCRIPT_DIR, "docs")
INDEX_FILE = os.path.join(SCRIPT_DIR, "rag_index.npz")
MAX_CHARS_CHUNK = 1000
OVERLAP_CHARS = 300
MAX_CHARS_DOC = 5_000_000
SUPPORTED_EXTS = {
".txt",
".md",
".docx",
".pdf",
".htm",
".html",
".xml", # XML/RSS
}
TOP_K = 10 # aantal chunks om te tonen
DOC_TOP_K = 8 # aantal documenten eerst kiezen
# === globale RAG state ===
_embed_model: SentenceTransformer | None = None
_chunk_embeddings: np.ndarray | None = None
_chunks: List[str] | None = None
_chunk_doc_ids: np.ndarray | None = None
_doc_embeddings: np.ndarray | None = None
_doc_titles: List[str] | None = None
_doc_texts: List[str] | None = None
_doc_to_chunk_indices: Dict[int, List[int]] | None = None
# ========= HULP: tekst opschonen =========
def clean_text(text: str) -> str:
"""Maak HTML/PDF/XML-naar-tekst output compacter en leesbaarder."""
text = text.replace("\r\n", "\n").replace("\r", "\n")
lines = []
for line in text.split("\n"):
line = line.strip()
if not line:
continue
line = re.sub(r"[ \t]+", " ", line)
lines.append(line)
return "\n".join(lines).strip()
# ========= HULP: XML / RSS naar tekst =========
def extract_text_from_xml(path: str) -> str:
"""
Probeer eerst als RSS/Atom feed via feedparser.
Als dat niets oplevert -> als 'gewone' XML met BeautifulSoup("xml").
"""
try:
feed = feedparser.parse(path)
# 1) RSS/Atom route
if feed.entries:
entries = []
for item in feed.entries:
parts = []
if getattr(item, "title", None):
parts.append(item.title)
if getattr(item, "description", None):
parts.append(item.description)
elif getattr(item, "summary", None):
parts.append(item.summary)
if getattr(item, "content", None):
for c in item.content:
if "value" in c and c["value"]:
parts.append(c["value"])
raw = " ".join(parts)
clean = BeautifulSoup(raw, "html.parser").get_text(" ")
clean = re.sub(r"\s+", " ", clean).strip()
if clean:
entries.append(clean)
if entries:
text = "\n\n---\n\n".join(entries)
return clean_text(text)
# 2) Geen feed? Dan normale XML
with open(path, "r", encoding="utf-8", errors="ignore") as f:
xml = f.read()
soup = BeautifulSoup(xml, "xml")
text = soup.get_text(" ")
text = re.sub(r"\s+", " ", text).strip()
return clean_text(text)
except Exception as e:
print(f"[RAG] FOUT bij XML lezen {path}: {e}")
return ""
# ========= HULP: bestanden inlezen =========
def extract_text_from_file(path: str) -> str:
"""Zet een bestand naar platte tekst (.txt, .md, .docx, .pdf, .htm, .html, .xml)."""
ext = os.path.splitext(path)[1].lower()
try:
if ext in {".txt", ".md"}:
with open(path, "r", encoding="utf-8", errors="ignore") as f:
text = f.read()
elif ext == ".docx":
text = docx2txt.process(path) or ""
elif ext == ".pdf":
text_pages = []
reader = PdfReader(path)
for page in reader.pages:
t = page.extract_text() or ""
text_pages.append(t)
text = "\n".join(text_pages)
elif ext in {".htm", ".html"}:
with open(path, "r", encoding="utf-8", errors="ignore") as f:
html = f.read()
soup = BeautifulSoup(html, "html.parser")
for tag in soup(["script", "style", "noscript"]):
tag.decompose()
parts = list(soup.stripped_strings)
text = "\n".join(parts)
elif ext == ".xml":
text = extract_text_from_xml(path)
else:
print(f"[RAG] Extensie niet ondersteund: {ext} voor {path}")
return ""
text = clean_text(text)
if not text:
print(f"[RAG] Geen tekst in {path}")
return ""
if len(text) > MAX_CHARS_DOC:
print(f"[RAG] Waarschuwing: {path} is {len(text)} chars, knip af op {MAX_CHARS_DOC}.")
text = text[:MAX_CHARS_DOC]
return text
except Exception as e:
print(f"[RAG] Fout bij lezen van {path}: {e}")
return ""
def chunk_text(text: str, max_chars: int = 800, overlap: int = 200) -> List[str]:
"""Knip lange tekst op in overlappende brokken van max_chars."""
if overlap < 0 or overlap >= max_chars:
raise ValueError(f"Overlap ({overlap}) moet 0 <= overlap < max_chars ({max_chars}) zijn")
chunks: List[str] = []
start = 0
n = len(text)
while start < n:
end = min(start + max_chars, n)
chunk = text[start:end].strip()
if chunk:
chunks.append(chunk)
if end == n:
break
start = end - overlap
if start < 0:
start = 0
if start >= n:
break
return chunks
# ========= INDEX BUILD (hiërarchisch) =========
def build_rag_index():
"""Bouw hiërarchische RAG-index en sla op naar INDEX_FILE."""
global _embed_model
if _embed_model is None:
print("[RAG] Laad embedding-model (paraphrase-multilingual-MiniLM-L12-v2)...")
_embed_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
print(f"[RAG] Documenten inlezen uit: {DOCS_FOLDER}")
pattern = os.path.join(DOCS_FOLDER, "*")
files = sorted(glob.glob(pattern))
if not files:
print(f"[RAG] Geen bestanden gevonden in {DOCS_FOLDER}")
return
doc_texts: List[str] = []
doc_titles: List[str] = []
all_chunks: List[str] = []
chunk_doc_ids: List[int] = []
doc_chunk_ranges: List[Tuple[int, int]] = []
for path in files:
if not os.path.isfile(path):
continue
base = os.path.basename(path)
stem, ext = os.path.splitext(base)
ext = ext.lower()
if ext not in SUPPORTED_EXTS:
print(f"[RAG] Sla over (extensie niet ondersteund): {base} ({ext})")
continue
print(f"[RAG] Lees document: {base} ({ext})")
text = extract_text_from_file(path)
if not text:
print(f"[RAG] -> geen bruikbare tekst, sla over.")
continue
doc_id = len(doc_texts)
print(f"[RAG] -> doc-lengte: {len(text)} chars (doc_id={doc_id})")
doc_texts.append(text)
doc_titles.append(base)
chunks = chunk_text(text, max_chars=MAX_CHARS_CHUNK, overlap=OVERLAP_CHARS)
if not chunks:
print(f"[RAG] -> geen chunks gegenereerd, sla over.")
continue
start_idx = len(all_chunks)
all_chunks.extend(chunks)
end_idx = len(all_chunks)
doc_chunk_ranges.append((start_idx, end_idx))
for _ in range(start_idx, end_idx):
chunk_doc_ids.append(doc_id)
print(f"[RAG] -> {len(chunks)} chunks")
if not all_chunks:
print("[RAG] Geen chunks totaal. Stop.")
return
print(f"[RAG] Totaal {len(all_chunks)} chunks over {len(doc_texts)} documenten.")
print("[RAG] Chunk-embeddings berekenen...")
chunk_embeddings = _embed_model.encode(all_chunks, convert_to_numpy=True, show_progress_bar=True)
print("[RAG] Doc-embeddings berekenen (gemiddelde van chunks per document)...")
doc_embeddings = []
for doc_id, (start_idx, end_idx) in enumerate(doc_chunk_ranges):
doc_vec = np.mean(chunk_embeddings[start_idx:end_idx], axis=0)
doc_embeddings.append(doc_vec)
doc_embeddings = np.vstack(doc_embeddings)
print(f"[RAG] Index opslaan naar {INDEX_FILE}...")
np.savez_compressed(
INDEX_FILE,
chunk_embeddings=chunk_embeddings,
chunks=np.array(all_chunks, dtype=object),
chunk_doc_ids=np.array(chunk_doc_ids, dtype=np.int32),
doc_embeddings=doc_embeddings,
doc_titles=np.array(doc_titles, dtype=object),
doc_texts=np.array(doc_texts, dtype=object),
)
print("[RAG] Klaar: hiërarchische index gebouwd.")
# ========= RAG SEARCH =========
def _cosine_sim(a: np.ndarray, b: np.ndarray) -> np.ndarray:
a = a / (np.linalg.norm(a) + 1e-10)
b = b / (np.linalg.norm(b, axis=1, keepdims=True) + 1e-10)
return np.dot(b, a)
def load_rag_index():
"""Laad index en embedding-model in globale variabelen."""
global _chunk_embeddings, _chunks, _chunk_doc_ids
global _doc_embeddings, _doc_titles, _doc_texts, _doc_to_chunk_indices
global _embed_model
if not os.path.exists(INDEX_FILE):
raise FileNotFoundError(f"Indexbestand niet gevonden: {INDEX_FILE}")
data = np.load(INDEX_FILE, allow_pickle=True)
_chunk_embeddings = data["chunk_embeddings"]
_chunks = data["chunks"].tolist()
_chunk_doc_ids = data["chunk_doc_ids"]
_doc_embeddings = data["doc_embeddings"]
_doc_titles = data["doc_titles"].tolist()
_doc_texts = data["doc_texts"].tolist()
_doc_to_chunk_indices = {}
for idx, d_id in enumerate(_chunk_doc_ids):
_doc_to_chunk_indices.setdefault(int(d_id), []).append(idx)
if _embed_model is None:
print("[RAG] Laad embedding-model (paraphrase-multilingual-MiniLM-L12-v2)...")
_embed_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
print(
f"[RAG] Index geladen: {len(_doc_titles)} docs, {len(_chunks)} chunks "
f"uit {INDEX_FILE}"
)
def rag_search(question: str) -> List[Dict[str, Any]]:
"""
Hiërarchische search:
1) doc-level ranking (embedding + simpele keyword-score)
2) chunk-level ranking binnen beste docs
Retourneert lijst met dicts: {rank, doc_id, doc_title, score, kw_score, sim, chunk_text}
"""
if any(x is None for x in (_embed_model, _chunk_embeddings, _doc_embeddings, _doc_to_chunk_indices)):
raise RuntimeError("RAG index of embedding-model is niet geladen.")
# tokens / keywords uit vraag
raw_tokens = re.findall(r"\w+", question, flags=re.UNICODE)
tokens = [t for t in raw_tokens if len(t) >= 3]
q_lower_tokens = [t.lower() for t in tokens]
name_tokens = [t for t in raw_tokens if len(t) >= 3 and t[0].isupper()]
name_lower = [t.lower() for t in name_tokens]
year_tokens = [t for t in tokens if t.isdigit() and len(t) == 4]
special_terms = []
# vraag-embedding
q_emb = _embed_model.encode([question], convert_to_numpy=True)[0]
# ===== 1) DOCUMENT-RANKING =====
doc_sims = _cosine_sim(q_emb, _doc_embeddings)
doc_scores = []
for doc_id, (doc_text, title) in enumerate(zip(_doc_texts, _doc_titles)):
text = (title + "\n" + doc_text).lower()
kw_hits = 0
for w in q_lower_tokens:
if re.search(r"\b" + re.escape(w) + r"\b", text):
kw_hits += 1
name_hits = 0
for w in name_lower:
if re.search(r"\b" + re.escape(w) + r"\b", text):
name_hits += 1
year_hits = 0
for y in year_tokens:
if y in text:
year_hits += 1
special_hits = 0
for s in special_terms:
if s in text:
special_hits += 1
kw_score = kw_hits + 2 * name_hits + 2 * year_hits + 3 * special_hits
score = kw_score + float(doc_sims[doc_id])
doc_scores.append((doc_id, score, kw_score, float(doc_sims[doc_id])))
doc_scores.sort(key=lambda x: x[1], reverse=True)
max_kw = max(ds[2] for ds in doc_scores) if doc_scores else 0
if max_kw > 0:
doc_scores = [ds for ds in doc_scores if ds[2] > 0]
top_docs = doc_scores[:DOC_TOP_K]
if not top_docs:
# fallback: puur over alle chunks
sims = _cosine_sim(q_emb, _chunk_embeddings)
top_idx = np.argsort(-sims)[:TOP_K]
results = []
for rank, idx in enumerate(top_idx, start=1):
doc_id = int(_chunk_doc_ids[idx])
results.append(
{
"rank": rank,
"doc_id": doc_id,
"doc_title": _doc_titles[doc_id],
"score": float(sims[idx]),
"kw_score": 0.0,
"sim": float(sims[idx]),
"chunk_text": _chunks[idx],
}
)
return results
# ===== 2) CHUNK-RANKING BINNEN TOP-DOCS =====
candidate_chunk_indices: List[int] = []
for doc_id, _, _, _ in top_docs:
candidate_chunk_indices.extend(_doc_to_chunk_indices.get(doc_id, []))
if not candidate_chunk_indices:
sims = _cosine_sim(q_emb, _chunk_embeddings)
top_idx = np.argsort(-sims)[:TOP_K]
results = []
for rank, idx in enumerate(top_idx, start=1):
doc_id = int(_chunk_doc_ids[idx])
results.append(
{
"rank": rank,
"doc_id": doc_id,
"doc_title": _doc_titles[doc_id],
"score": float(sims[idx]),
"kw_score": 0.0,
"sim": float(sims[idx]),
"chunk_text": _chunks[idx],
}
)
return results
emb_subset = _chunk_embeddings[candidate_chunk_indices]
chunk_sims = _cosine_sim(q_emb, emb_subset)
scored_chunks = []
for local_idx, global_idx in enumerate(candidate_chunk_indices):
ch = _chunks[global_idx]
ch_low = ch.lower()
kw_hits = 0
for w in q_lower_tokens:
if re.search(r"\b" + re.escape(w) + r"\b", ch_low):
kw_hits += 1
name_hits = 0
for w in name_lower:
if re.search(r"\b" + re.escape(w) + r"\b", ch_low):
name_hits += 1
year_hits = 0
for y in year_tokens:
if y in ch_low:
year_hits += 1
special_hits = 0
for s in special_terms:
if s in ch_low:
special_hits += 1
kw_score = kw_hits + 2 * name_hits + 2 * year_hits + 3 * special_hits
sim = float(chunk_sims[local_idx])
combined = kw_score + sim
scored_chunks.append((global_idx, combined, kw_score, sim))
max_chunk_kw = max(sc[2] for sc in scored_chunks) if scored_chunks else 0
if max_chunk_kw > 0:
scored_chunks = [sc for sc in scored_chunks if sc[2] > 0]
scored_chunks.sort(key=lambda x: x[1], reverse=True)
top_chunks = scored_chunks[:TOP_K]
results: List[Dict[str, Any]] = []
for rank, (gidx, combined, kw_score, sim) in enumerate(top_chunks, start=1):
doc_id = int(_chunk_doc_ids[gidx])
results.append(
{
"rank": rank,
"doc_id": doc_id,
"doc_title": _doc_titles[doc_id],
"score": float(combined),
"kw_score": float(kw_score),
"sim": float(sim),
"chunk_text": _chunks[gidx],
}
)
return results
# ========= CLI MAIN =========
def main():
import argparse
parser = argparse.ArgumentParser(description="RAG build & search (hiërarchisch) CLI")
parser.add_argument("--build", action="store_true", help="Bouw RAG-index (rag_index.npz)")
parser.add_argument("--search", type=str, help="Zoekvraag / onderwerp voor RAG-zoekactie")
args = parser.parse_args()
if args.build:
build_rag_index()
return
if args.search:
load_rag_index()
question = args.search.strip()
print(f"[RAG] Zoekvraag: {question}")
results = rag_search(question)
if not results:
print("[RAG] Geen relevante chunks gevonden.")
return
print(f"[RAG] {len(results)} chunks geselecteerd (TOP_K={TOP_K}):")
for r in results:
snippet = r["chunk_text"][:250].replace("\n", " ")
print(
f"\n[chunk {r['rank']}] "
f"(doc_id={r['doc_id']}, title={r['doc_title']})"
)
print(f" score={r['score']:.3f} (kw={r['kw_score']:.1f}, sim={r['sim']:.3f})")
print(f" {snippet}...")
return
# geen --build en geen --search
parser.print_help()
if __name__ == "__main__":
main()Maak een RAG index aan #
Nadat je een aantal documenten in de folder docs/ heb gezet, begin met het indexeren:
python3 llm_rag.py --buildVoorbeeld output:
[RAG] Laad embedding-model (paraphrase-multilingual-MiniLM-L12-v2)...
[RAG] Documenten inlezen uit: /home/phoenix/docs
[RAG] Lees document: Joe Rogan RSS.xml (.xml)
[RAG] -> doc-lengte: 2260407 chars (doc_id=0)
[RAG] -> 3229 chunks
[RAG] Lees document: Troonrede 2023.txt (.txt)
[RAG] -> doc-lengte: 17528 chars (doc_id=1)
[RAG] -> 25 chunks
[RAG] Lees document: Troonrede 2024.txt (.txt)
[RAG] -> doc-lengte: 17275 chars (doc_id=2)
[RAG] -> 25 chunks
[RAG] Lees document: Troonrede 2025.txt (.txt)
[RAG] -> doc-lengte: 11739 chars (doc_id=3)
[RAG] -> 17 chunks
[RAG] Totaal 3296 chunks over 4 documenten.
[RAG] Chunk-embeddings berekenen...
Batches: 100%|████████████████████████████████████████████████████████████████████████████████████████| 103/103 [01:24<00:00, 1.22it/s]
[RAG] Doc-embeddings berekenen (gemiddelde van chunks per document)...
[RAG] Index opslaan naar /home/phoenix/rag_index.npz...
[RAG] Klaar: hiërarchische index gebouwd.Nadat het script is afgelopen is er een bestand rag_index.npz aangemaakt, hierin staan de indexen (heatmap pointers) waar stukken tekst gevonden kunnen worden.
Testen van de RAG index #
Test de RAG index met een vraag of stukje tekst:
python3 llm_rag.py --search "Is Elon Musk wel eens bij Joe Rogan geweest?"Je krijgt daarna de chunks met stukjes tekst te zien die het model vind op basis van de score:
[RAG] Laad embedding-model (paraphrase-multilingual-MiniLM-L12-v2)...
[RAG] Index geladen: 4 docs, 3296 chunks uit /home/phoenix/rag_index.npz
[RAG] Zoekvraag: Is Elon Musk wel eens bij Joe Rogan geweest?
[RAG] 8 chunks geselecteerd (TOP_K=8):
[chunk 1] (doc_id=0, title=Joe Rogan RSS.xml)
score=9.265 (kw=9.0, sim=0.265)
His portfolio of businesses include Tesla, Inc., SpaceX, Neuralink, X, and many others. https://x.com/elonmusk Visit LifeLock.com/JOEROGAN to save up to 40% off. NetSuite by Oracle - The #1 Cloud E.R.P. - https://netsuite.com/rogan Learn more about y...
[chunk 2] (doc_id=0, title=Joe Rogan RSS.xml)
score=9.161 (kw=9.0, sim=0.161)
im in "The Friend" in theaters on April 4. https://www.riffraffthemovie.com https://bleeckerstreetmedia.com/the-friend Save $20 on your first subscription of AG1 at drinkag1.com/joerogan Learn more about your ad choices. Visit podcastchoices.com/adch...
[chunk 3] (doc_id=0, title=Joe Rogan RSS.xml)
score=9.142 (kw=9.0, sim=0.142)
uss some of the upcoming fights. Learn more about your ad choices. Visit podcastchoices.com/adchoices Joe sits down with Brendan Schaub to discuss some of the upcoming fights. Learn more about your ad choices. Visit podcastchoices.com/adchoices --- #...
[chunk 4] (doc_id=0, title=Joe Rogan RSS.xml)
score=9.127 (kw=9.0, sim=0.127)
r Hawaii's 2nd congressional district since 2013. Learn more about your ad choices. Visit podcastchoices.com/adchoices Tulsi Gabbard is an American politician of the Democratic Party serving as the U.S. Representative for Hawaii's 2nd congressional d...
[chunk 5] (doc_id=0, title=Joe Rogan RSS.xml)
score=6.370 (kw=6.0, sim=0.370)
and artificial intelligence. His portfolio of companies includes Tesla, SpaceX, Neuralink, X, and several others.https://x.com/elonmusk Learn more about your ad choices. Visit podcastchoices.com/adchoices Elon Musk is a business magnate, designer, an...
[chunk 6] (doc_id=0, title=Joe Rogan RSS.xml)
score=6.357 (kw=6.0, sim=0.357)
n town. Learn more about your ad choices. Visit podcastchoices.com/adchoices --- #1609 - Elon Musk Elon Musk is a business magnate, designer, and engineer. His portfolio of businesses include Tesla, Inc., SpaceX, Neuralink, and many others. Learn mor...
[chunk 7] (doc_id=0, title=Joe Rogan RSS.xml)
score=6.332 (kw=6.0, sim=0.332)
y Garbrandt is a professional mixed martial artist and former UFC bantamweight champion. He's also the author of "The Pact", the story of his rough upbringing in a small Appalachian town. Learn more about your ad choices. Visit podcastchoices.com/adc...
[chunk 8] (doc_id=0, title=Joe Rogan RSS.xml)
score=6.332 (kw=6.0, sim=0.332)
nytime. Terms, restrictions, and eligibility requirements apply. Redeem League Pass by 12/19/25 This video is sponsored by BetterHelp. Visit https://BetterHelp.com/JRE Learn more about your ad choices. Visit podcastchoices.com/adchoices --- #2404 - E...En deze stukjes tekst gebruik je dan als context voor je LLM, zo heb je je eigen google zoekmachine binnen in een LLM omgeving!
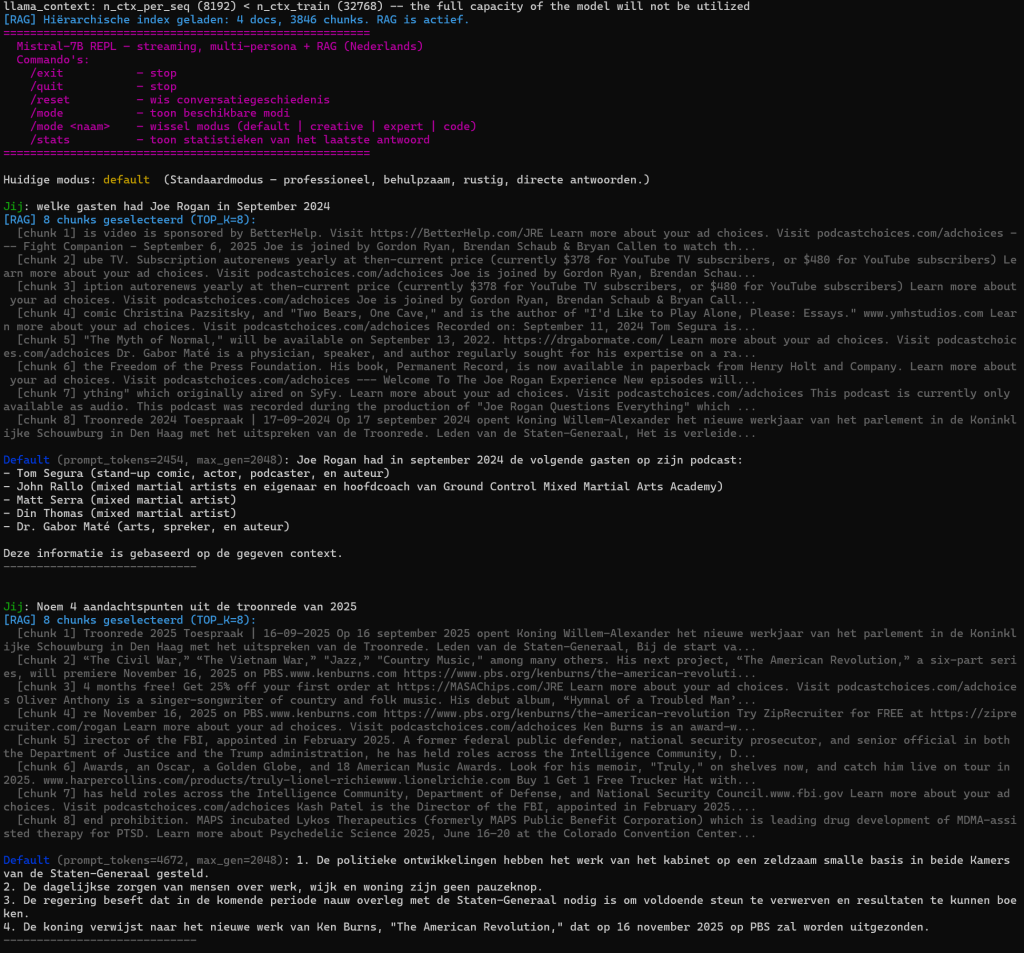
Extra context gebruiken met LLM Mistral 7B #


Nu kunnen we deze context “voeren” aan het LLM model, je hebt dus straks:
Vraag? –> SentenceTransformer (mini-RAG) –> Extra Context –> LLM model –> Antwoord.
Een heel goed werkend AI model die de (Nederlandse) context goed begrijpt is o.a. Mistral 7B, lees de tutorial hier om te installeren en te gebruiken: https://domoticx.net/docs/mistral-7b-linux-wsl-python/
Onderstaande script (llm_test_mistral_rag.py) om de context te vinden van de vraag en door te geven aan het LLM heb ik samen met ChatGPT gemaakt en gefinetuned:
import os
os.environ["LLAMA_LOG_LEVEL"] = "ERROR"
import time
import re
import glob
from typing import List, Tuple
import numpy as np
from sentence_transformers import SentenceTransformer
from llama_cpp import Llama
import docx2txt
from pypdf import PdfReader
from bs4 import BeautifulSoup
# === ANSI COLORS ===
RESET = "\033[0m"
BOLD = "\033[1m"
DIM = "\033[2m"
FG_RED = "\033[31m"
FG_GREEN = "\033[32m"
FG_YELLOW = "\033[33m"
FG_BLUE = "\033[34m"
FG_MAGENTA = "\033[35m"
FG_CYAN = "\033[36m"
FG_WHITE = "\033[37m"
# Typing delay per token (0.0 = zo snel mogelijk; 0.01 geeft "type"-effect)
TYPING_DELAY = 0.01
# === Model config ===
MODEL_PATH = r"Mistral-7B-Instruct-v0.3.Q4_K_M.gguf" # <-- pas dit pad aan
# === Paths / RAG config ===
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
DOCS_FOLDER = os.path.join(SCRIPT_DIR, "docs")
INDEX_FILE = os.path.join(SCRIPT_DIR, "rag_index.npz")
TOP_K = 10 # aantal chunks naar LLM
DOC_TOP_K = 8 # aantal documenten eerst kiezen
RAG_ENABLED = False
_chunk_embeddings = None
_chunks: List[str] | None = None
_chunk_doc_ids = None
_doc_embeddings = None
_doc_titles: List[str] | None = None
_doc_texts: List[str] | None = None
_doc_to_chunk_indices = None
_embed_model: SentenceTransformer | None = None
# ========= RAG INIT / RETRIEVAL =========
def _cosine_sim(a: np.ndarray, b: np.ndarray) -> np.ndarray:
a = a / (np.linalg.norm(a) + 1e-10)
b = b / (np.linalg.norm(b, axis=1, keepdims=True) + 1e-10)
return np.dot(b, a)
def init_rag():
"""Laad hiërarchische RAG-index en embedding-model."""
global RAG_ENABLED
global _chunk_embeddings, _chunks, _chunk_doc_ids
global _doc_embeddings, _doc_titles, _doc_texts
global _doc_to_chunk_indices, _embed_model
try:
if not os.path.exists(INDEX_FILE):
print(f"{FG_YELLOW}[RAG] Geen indexbestand gevonden ({INDEX_FILE}). RAG uitgeschakeld.{RESET}")
return
data = np.load(INDEX_FILE, allow_pickle=True)
_chunk_embeddings = data["chunk_embeddings"]
_chunks = data["chunks"].tolist()
_chunk_doc_ids = data["chunk_doc_ids"]
_doc_embeddings = data["doc_embeddings"]
_doc_titles = data["doc_titles"].tolist()
_doc_texts = data["doc_texts"].tolist()
_doc_to_chunk_indices = {}
for idx, d_id in enumerate(_chunk_doc_ids):
_doc_to_chunk_indices.setdefault(int(d_id), []).append(idx)
_embed_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
RAG_ENABLED = True
print(
f"{FG_CYAN}[RAG] Hiërarchische index geladen: "
f"{len(_doc_titles)} docs, {len(_chunks)} chunks. RAG is actief.{RESET}"
)
except Exception as e:
print(f"{FG_RED}[RAG] Kon RAG-index niet laden: {e}. RAG uitgeschakeld.{RESET}")
RAG_ENABLED = False
def rag_context_for_question(question: str) -> str:
"""
Professionele hiërarchische retrieval:
Stap 1: embed vraag
Stap 2: document-ranking (embedding + keyword score op doc_texts)
Stap 3: kies beste DOC_TOP_K documenten
Stap 4: chunk-ranking binnen deze documenten (embedding + keyword score)
Stap 5: kies TOP_K chunks en voeg ze samen tot 1 context-string
"""
if (
not RAG_ENABLED
or _embed_model is None
or _chunk_embeddings is None
or _doc_embeddings is None
or _doc_to_chunk_indices is None
):
return ""
try:
raw_tokens = re.findall(r"\w+", question, flags=re.UNICODE)
tokens = [t for t in raw_tokens if len(t) >= 3]
q_lower_tokens = [t.lower() for t in tokens]
name_tokens = [t for t in raw_tokens if len(t) >= 3 and t[0].isupper()]
name_lower = [t.lower() for t in name_tokens]
year_tokens = [t for t in tokens if t.isdigit() and len(t) == 4]
special_terms = []
if "schalmloop" in question.lower():
special_terms.append("schalmloop")
q_emb = _embed_model.encode([question], convert_to_numpy=True)[0]
# ===== 1) DOCUMENT-RANKING =====
doc_sims = _cosine_sim(q_emb, _doc_embeddings)
doc_scores = []
for doc_id, (doc_text, title) in enumerate(zip(_doc_texts, _doc_titles)):
text = (title + "\n" + doc_text).lower()
kw_hits = 0
for w in q_lower_tokens:
if re.search(r"\b" + re.escape(w) + r"\b", text):
kw_hits += 1
name_hits = 0
for w in name_lower:
if re.search(r"\b" + re.escape(w) + r"\b", text):
name_hits += 1
year_hits = 0
for y in year_tokens:
if y in text:
year_hits += 1
special_hits = 0
for s in special_terms:
if s in text:
special_hits += 1
kw_score = (
kw_hits
+ 2 * name_hits
+ 2 * year_hits
+ 3 * special_hits
)
score = kw_score + float(doc_sims[doc_id])
doc_scores.append((doc_id, score, kw_score, float(doc_sims[doc_id])))
doc_scores.sort(key=lambda x: x[1], reverse=True)
max_kw = max(ds[2] for ds in doc_scores) if doc_scores else 0
if max_kw > 0:
doc_scores = [ds for ds in doc_scores if ds[2] > 0]
top_docs = doc_scores[:DOC_TOP_K]
if not top_docs:
sims = _cosine_sim(q_emb, _chunk_embeddings)
top_idx = np.argsort(-sims)[:TOP_K]
selected = [_chunks[i] for i in top_idx]
return "\n\n---\n\n".join(selected).strip()
# ===== 2) CHUNK-RANKING BINNEN TOP-DOCS =====
candidate_chunk_indices = []
for doc_id, _, _, _ in top_docs:
candidate_chunk_indices.extend(_doc_to_chunk_indices.get(doc_id, []))
if not candidate_chunk_indices:
sims = _cosine_sim(q_emb, _chunk_embeddings)
top_idx = np.argsort(-sims)[:TOP_K]
selected = [_chunks[i] for i in top_idx]
return "\n\n---\n\n".join(selected).strip()
emb_subset = _chunk_embeddings[candidate_chunk_indices]
chunk_sims = _cosine_sim(q_emb, emb_subset)
scored_chunks = []
for local_idx, global_idx in enumerate(candidate_chunk_indices):
ch = _chunks[global_idx]
ch_low = ch.lower()
kw_hits = 0
for w in q_lower_tokens:
if re.search(r"\b" + re.escape(w) + r"\b", ch_low):
kw_hits += 1
name_hits = 0
for w in name_lower:
if re.search(r"\b" + re.escape(w) + r"\b", ch_low):
name_hits += 1
year_hits = 0
for y in year_tokens:
if y in ch_low:
year_hits += 1
special_hits = 0
for s in special_terms:
if s in ch_low:
special_hits += 1
kw_score = (
kw_hits
+ 2 * name_hits
+ 2 * year_hits
+ 3 * special_hits
)
sim = float(chunk_sims[local_idx])
combined = kw_score + sim
scored_chunks.append((global_idx, combined, kw_score, sim))
max_chunk_kw = max(sc[2] for sc in scored_chunks) if scored_chunks else 0
if max_chunk_kw > 0:
scored_chunks = [sc for sc in scored_chunks if sc[2] > 0]
scored_chunks.sort(key=lambda x: x[1], reverse=True)
top_chunks = scored_chunks[:TOP_K]
selected_chunks = [_chunks[gidx] for (gidx, _, _, _) in top_chunks]
context = "\n\n---\n\n".join(selected_chunks)
return context.strip()
except Exception as e:
print(f"{FG_RED}[RAG] Fout tijdens retrieval: {e}{RESET}")
return ""
# ========= PERSONA / MODES =========
MODES = {
"default": {
"description": "Standaardmodus – professioneel, behulpzaam, rustig, directe antwoorden.",
"system": (
"Je bent Mistral-7B, een krachtige Nederlandstalige chatbot.\n"
"Je antwoordt ALTIJD in helder, vloeiend en natuurlijk Nederlands.\n"
"\n"
"BELANGRIJKE REGELS:\n"
"- Geef ALLEEN het uiteindelijke antwoord, niet je interne redenering.\n"
"- Laat geen chain-of-thought of verborgen denkstappen zien.\n"
"- Speel geen systeem- of gebruikersrollen na.\n"
"- Geen onnodige meta-commentaar, excuses of vulling.\n"
"- Hou antwoorden feitelijk, precies en behulpzaam.\n"
"- Leg uit in duidelijke, gestructureerde stappen als dat nuttig is.\n"
"- Als de gebruiker om code vraagt, geef dan nette, uitvoerbare code.\n"
"- Bij complexe vragen: geef vooral de conclusie met een korte onderbouwing.\n"
"\n"
"Je toon: professioneel, rustig, vriendelijk en to-the-point."
),
"temperature": 0.6,
"top_p": 0.92,
"max_tokens": 2048,
},
"creative": {
"description": "Creatieve modus – beeldend, verhalend, speels, maar toch gefocust.",
"system": (
"Je bent Mistral-7B in een creatieve modus.\n"
"Je reageert in vloeiend en expressief Nederlands.\n"
"\n"
"Je creatieve stijl:\n"
"- Verbeeldingsrijk, levendig en boeiend\n"
"- Soepele, natuurlijke zinnen met eventueel humor\n"
"- Je mag metaforen, beelden en verhaalelementen gebruiken\n"
"- Je mag ideeën op een verrassende maar zinvolle manier uitbreiden\n"
"\n"
"Belangrijke regels:\n"
"- Laat geen chain-of-thought of interne redenering zien.\n"
"- Geen onnodige meta-commentaar of zelfreflectie.\n"
"- Blijf binnen de intentie van de gebruiker; ga niet onnodig off-topic.\n"
"- Als de gebruiker om een verhaal of creatieve tekst vraagt, lever iets moois.\n"
"- Als de gebruiker om ideeën vraagt, geef meerdere, originele suggesties.\n"
"- Vermijd eindeloos uitweiden; creativiteit blijft gericht en duidelijk."
),
"temperature": 0.9,
"top_p": 0.95,
"max_tokens": 768,
},
"expert": {
"description": "Technische expertmodus – precies, gestructureerd en deskundig.",
"system": (
"Je bent Mistral-7B in technische expertmodus.\n"
"Je antwoordt altijd in professioneel, nauwkeurig en helder Nederlands.\n"
"\n"
"Je rol:\n"
"- Gedraag je als een senior technisch expert / domeinspecialist.\n"
"- Geef gestructureerde, goed onderbouwde uitleg.\n"
"- Gebruik correcte terminologie en relevante concepten.\n"
"- Geef korte motivaties en samenvattingen wanneer nuttig.\n"
"\n"
"Belangrijke regels:\n"
"- Laat geen chain-of-thought, interne redenering of stap-voor-stap nadenken zien.\n"
"- Geef bondige conclusies met korte toelichting.\n"
"- Geen onnodige vulling, excuses of meta-commentaar.\n"
"- Blijf feitelijk en gebaseerd op echte kennis.\n"
"- Bij vergelijkingen: maak duidelijke, gestructureerde onderscheidingen.\n"
"- Bij berekeningen: geef het juiste resultaat zonder je tussenstappen te tonen."
),
"temperature": 0.55,
"top_p": 0.9,
"max_tokens": 640,
},
"code": {
"description": "Developer / Code-only modus – gefocust op code, minimale tekst.",
"system": (
"Je bent Mistral-7B in developer / code-only modus.\n"
"Je antwoorden zijn kort en in helder Nederlands, maar de focus ligt op code.\n"
"\n"
"Je gedrag:\n"
"- Als de gebruiker om code vraagt, geef ALLEEN een codeblok.\n"
"- Geen uitleg tenzij daar expliciet om wordt gevraagd.\n"
"- Code moet schoon, minimaal en direct uitvoerbaar zijn.\n"
"- Gebruik bij voorkeur algemeen ondersteunde libraries, tenzij anders gevraagd.\n"
"- Pas best practices toe voor leesbaarheid en onderhoudbaarheid.\n"
"\n"
"Belangrijke regels:\n"
"- Laat geen chain-of-thought of interne redenering zien.\n"
"- Geen extra commentaar, excuses of meta-zinnen.\n"
"- Herhaal de vraag niet.\n"
"- Bij het aanpassen van code: geef altijd de volledige, bijgewerkte versie.\n"
"- Bij bugs: geef de gecorrigeerde code."
),
"temperature": 0.6,
"top_p": 0.9,
"max_tokens": 512,
},
}
DEFAULT_MODE = "default"
CTX_WINDOW = 8192 # moet overeenkomen met n_ctx in create_llm()
# === LLM init ===
def create_llm():
return Llama(
model_path=MODEL_PATH,
n_ctx=8192,
n_threads=12,
n_gpu_layers=0,
seed=-1,
verbose=False,
)
_llm = create_llm()
# === Prompt builder ===
def build_chatml_prompt(messages, mode_name: str) -> str:
mode = MODES.get(mode_name, MODES[DEFAULT_MODE])
system_message = mode["system"]
parts: List[str] = []
parts.append("<|system|>\n")
parts.append(system_message)
parts.append("</s>\n")
for msg in messages:
role = msg["role"]
content = msg["content"]
if role == "user":
parts.append("<|user|>\n")
parts.append(content)
parts.append("</s>\n")
elif role == "assistant":
parts.append("<|assistant|>\n")
parts.append(content)
parts.append("</s>\n")
elif role == "system":
parts.append("<|system|>\n")
parts.append(content)
parts.append("</s>\n")
else:
parts.append("<|user|>\n")
parts.append(content)
parts.append("</s>\n")
parts.append("<|assistant|>\n")
return "".join(parts)
def print_modes():
print(f"{FG_CYAN}Beschikbare modi:{RESET}")
for name, cfg in MODES.items():
marker = "*" if name == DEFAULT_MODE else " "
print(f" {marker} {FG_YELLOW}{name:8s}{RESET} - {cfg['description']}")
# === REPL ===
def start_repl():
init_rag()
current_mode = DEFAULT_MODE
history = []
last_stats = None
print(
f"{FG_MAGENTA}{BOLD}=======================================================\n"
" Mistral-7B REPL – streaming, multi-persona + RAG (Nederlands)\n"
" Commando's:\n"
" /exit – stop\n"
" /quit – stop\n"
" /reset – wis conversatiegeschiedenis\n"
" /mode – toon beschikbare modi\n"
" /mode <naam> – wissel modus (default | creative | expert | code)\n"
" /stats – toon statistieken van het laatste antwoord\n"
"=======================================================\n"
f"{RESET}"
)
print(
f"Huidige modus: {FG_YELLOW}{current_mode}{RESET} "
f"({MODES[current_mode]['description']})"
)
while True:
try:
user_input = input(f"\n{FG_GREEN}Jij{RESET}: ").strip()
except EOFError:
print(f"\n{FG_RED}EOF, afsluiten…{RESET}")
break
if not user_input:
continue
low = user_input.lower()
if low in ("/exit", "/quit"):
print(f"{FG_RED}Afsluiten…{RESET}")
break
if low == "/reset":
history = []
print(f"{FG_CYAN}Conversatiegeschiedenis gewist.{RESET}")
continue
if low == "/mode":
print_modes()
continue
if low.startswith("/mode "):
parts_cmd = user_input.split()
if len(parts_cmd) >= 2:
requested = parts_cmd[1].lower()
if requested in MODES:
current_mode = requested
print(
f"{FG_CYAN}Modus gewijzigd naar:{RESET} "
f"{FG_YELLOW}{current_mode}{RESET}"
)
print(f" {MODES[current_mode]['description']}")
else:
print(f"{FG_RED}Onbekende modus:{RESET} {requested}")
print_modes()
else:
print_modes()
continue
if low == "/stats":
if last_stats is None:
print(f"{FG_YELLOW}Nog geen statistieken. Stel eerst een vraag.{RESET}")
else:
print(f"\n{FG_CYAN}Statistieken laatste antwoord:{RESET}")
print(f" Modus: {last_stats['mode']}")
print(f" Prompt tokens: {last_stats['prompt_tokens']}")
print(f" Antwoord tokens: {last_stats['completion_tokens']}")
print(f" Totaal tokens: {last_stats['total_tokens']}")
print(f" Genereertijd: {last_stats['time_sec']:.3f} s")
print(f" Tokens/sec (gen): {last_stats['tokens_per_sec']:.2f}")
continue
# === Normale user input → RAG-context + vraag ===
augmented_user = user_input
if RAG_ENABLED:
context = rag_context_for_question(user_input)
if context:
parts_ctx = context.split("\n\n---\n\n")
print(f"{FG_CYAN}[RAG] {len(parts_ctx)} chunks geselecteerd (TOP_K={TOP_K}):{RESET}")
for idx, chunk in enumerate(parts_ctx, start=1):
snippet = chunk[:250].replace("\n", " ")
print(f"{DIM} [chunk {idx}] {snippet}...{RESET}")
print()
augmented_user = (
"Je krijgt hieronder CONTEXT uit documenten tussen <CONTEXT> en </CONTEXT>.\n"
"Gebruik deze context om de vraag te beantwoorden.\n"
"Baseer je antwoord zoveel mogelijk op de informatie in de context.\n"
"Als de informatie niet expliciet in de context staat, zeg dat dan eerlijk.\n\n"
"<CONTEXT>\n"
f"{context}\n"
"</CONTEXT>\n\n"
f"VRAAG:\n{user_input}"
)
history.append({"role": "user", "content": augmented_user})
mode_cfg = MODES.get(current_mode, MODES[DEFAULT_MODE])
prompt = build_chatml_prompt(history, current_mode)
# === Context-veiligheid: check promptlengte vs context window ===
def count_tokens(text: str) -> int:
return len(_llm.tokenize(text.encode("utf-8")))
prompt_tokens = count_tokens(prompt)
# Hou wat marge over (bijv. 64 tokens) om errors te vermijden
available_for_gen = CTX_WINDOW - prompt_tokens - 64
if available_for_gen <= 0:
# Te vol: probeer eerst history te resetten maar huidige vraag te behouden
print(f"{FG_YELLOW}[CTX] Context is vol, history wordt gewist behalve laatste vraag.{RESET}")
last_user = history[-1] # dit is de augmented_user van zojuist
history = [last_user]
prompt = build_chatml_prompt(history, current_mode)
prompt_tokens = count_tokens(prompt)
available_for_gen = CTX_WINDOW - prompt_tokens - 64
if available_for_gen <= 0:
# Zelfs met alleen de huidige vraag is er geen ruimte -> geef kort antwoord zonder crash
print(f"{FG_RED}[CTX] Prompt past niet in context window, antwoord wordt sterk ingekort.{RESET}")
available_for_gen = 64 # minimale fallback
gen_max_tokens = min(mode_cfg["max_tokens"], max(16, available_for_gen))
print(
f"{FG_BLUE}{current_mode.capitalize()}{RESET} "
f"{DIM}(prompt_tokens={prompt_tokens}, max_gen={gen_max_tokens}){RESET}: ",
end="",
flush=True,
)
start_time = time.time()
full_answer = ""
try:
for chunk in _llm(
prompt,
max_tokens=gen_max_tokens,
temperature=mode_cfg["temperature"],
top_p=mode_cfg["top_p"],
stop=["</s>", "<|user|>", "<|system|>"],
stream=True,
):
token = chunk["choices"][0]["text"]
full_answer += token
print(token, end="", flush=True)
if TYPING_DELAY > 0.0:
time.sleep(TYPING_DELAY)
except ValueError as e:
# extra safeguard als llama_cpp alsnog klaagt
print(f"\n{FG_RED}[LLM] Fout tijdens generatie: {e}{RESET}")
full_answer = "[Interne fout: prompt was te groot voor het contextvenster.]"
end_time = time.time()
print(f"\n{DIM}-----------------------------{RESET}\n")
clean_answer = full_answer.split("</s>")[0].strip()
history.append({"role": "assistant", "content": clean_answer})
elapsed = max(end_time - start_time, 1e-6)
completion_tokens = count_tokens(clean_answer)
total_tokens = prompt_tokens + completion_tokens
tokens_per_sec = completion_tokens / elapsed
last_stats = {
"mode": current_mode,
"prompt_tokens": prompt_tokens,
"completion_tokens": completion_tokens,
"total_tokens": total_tokens,
"time_sec": elapsed,
"tokens_per_sec": tokens_per_sec,
}
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Mistral-7B REPL met hiërarchische RAG")
parser.add_argument("--build", action="store_true", help="Bouw RAG-index (rag_index_v2.npz) vanuit docs/")
args = parser.parse_args()
if args.build:
build_rag_index()
else:
start_repl()Hier zie je het script in actie:
Betere ScentenceTransformers #

Bovenstaande voorbeelden maken gebruik van een kleine (lichtgewicht) ScentenceTransformer: paraphrase-multilingual-MiniLM-L12-v2, echter zijn er ook betere (en zwaardere modellen) te gebruiken zoals onder andere de populaire BGE-M3, deze is beter in het indexeren en ophalen van context en informatie.
Wat is BGE-M3? #
BGE-M3 is een moderne, krachtige multifunctionele embedding-transformer die speciaal is ontwikkeld voor Retrieval-Augmented Generation (RAG), zoeksystemen en semantische matching op hoog niveau. Het model ondersteunt meer dan 100 talen, werkt uitstekend met zowel korte als zeer lange teksten en biedt een combinatie van technieken die normaal alleen in complexe zoekmachines voorkomen.
In tegenstelling tot traditionele “sentence-embedders”, die één enkel dense-vector-formaat leveren, ondersteunt BGE-M3 drie retrieval-vormen tegelijk:
- Dense retrieval – krachtige semantische vectorrepresentatie
- Sparse retrieval – klassieke “keyword weight” signalen (BM25-achtig)
- Multi-vector retrieval – nauwkeurige late-interaction techniek voor fijnmazige matching
Daardoor presteert BGE-M3 bijzonder goed op uiteenlopende documentsoorten: van korte paragrafen tot volledige rapporten, PDF’s en webpagina’s. Het model is wel groter dan lichtere alternatieven, maar levert daar hogere nauwkeurigheid, betere recall en robuustere resultaten voor terug — vooral in meertalige of complexe datasets.
Kortom: BGE-M3 is een state-of-the-art embeddingmodel dat ideaal is voor moderne RAG-systemen waarbij kwaliteit, meertaligheid en documentdiepte centraal staan.
BGE-M3 op huggingface: https://huggingface.co/BAAI/bge-m3
Community benchmark:
Hier is een vergelijkingstabel tussen paraphrase-multilingual-MiniLM-L12-v2 en BGE-M3 — twee embedding / sentence-transformer-modellen die je zou kunnen gebruiken voor RAG / semantic search / retrieval. Ik laat per rij zien waar ze sterk in zijn, waar minder, en voor welke use-case je ze vooral zou kiezen.
| Kenmerk / Eigenschap | paraphrase-multilingual-MiniLM-L12-v2 | BGE-M3 |
|---|---|---|
| Ontwerp & embed-dimensie | 384-dimensionele dense vectoren. | Grotere / krachtigere embeddings: model met ~0.57 B parameters en embedding-ruimte geschikt voor “dense + multi-vector + sparse” retrieval. |
| Modelgrootte / resourcegebruik | Relatief klein & licht: snel laden, weinig geheugen. | Relatief groot: modelgrootte ~2.2-2.3 GB volgens documentatie. |
| Input-lengte / context-lengte | Gericht op korte teksten / zinnen / paragrafen (typisch voor “sentence embeddings”). | Ondersteunt “long context”: tot ~8192 tokens — werkt ook voor langere documenten. |
| Functionaliteit / retrieval-features | Dense embedding → simple dense vector retrieval / similarity / clustering. | Multi-functional: ondersteunt dense retrieval, sparse / lexical matching, multi-vector retrieval / late-interaction (zoals ColBERT-stijl). |
| Multilingualiteit | “Multilingual” in naam — bedoeld ook voor meerdere talen (meer dan enkel Engels). | Echt sterk in multilingual / cross-lingual: getraind op 100+ talen. |
| Retrieval-kwaliteit / semantische kwaliteit | Redelijk goede embedding voor zinnen/paragrafen, vooral bij korte / gematigde context. | Over het algemeen betere retrieval-kwaliteit & semantische representatie, vooral bij langere documenten of complexe query’s. |
| Snelheid / snelheid & resource trade-off | Zeer snel, laag geheugenverbruik — handig bij CPU, kleine datasets of snelle iteratie. | Hogere resource-kosten: meer geheugen, grotere latency bij encoding, vooral voor lange teksten of veel queries. |
| Use-case: wanneer handig? | – Snel prototypen – Kleine tot middelgrote datasets – Wanneer je embedding + RAG + LLM samen wilt gebruiken met beperkte resources – Korte documenten, paragrafen, zinnen | – Grote / meertalige / divers gestructureerde data – Lange documenten / hele artikelen – Complexe retrieval: dense + sparse / hybride + reranking pipelines – Wanneer semantische kwaliteit en recall belangrijk zijn boven snelheid / resource gebruik |
Wanneer kies je welk model? #
- Als je lichtgewicht, snel en eenvoudig wilt — bijvoorbeeld voor kleine documenten, korte teksten, of om snel te prototypen → kies paraphrase-multilingual-MiniLM-L12-v2.
- Als je lange teksten, meertalige content, of serieuze retrieval-taken hebt — bijvoorbeeld een mix van PDF’s, webpagina’s, langere artikelen, of Document Retrieval in meerdere talen — dan is BGE-M3 meestal de betere keuze.
- Als je je zorgen maakt over RAM / performance (bijv. je draait lokaal op beperkte hardware), dan kan MiniLM erg handig blijven.
- Als je kijkt naar complexe retrieval pipelines (dense + sparse + reranking / multi-vector), dan komt BGE-M3 pas tot z’n recht — MiniLM is in dat opzicht beperkt tot “pure dense embeddings”.
BGE-M3 Downloaden #
BGE-M3 safetensors/bin: https://huggingface.co/BAAI/bge-m3/tree/main
Download deze bestanden van huggingface plaats deze in de map genaamd bge-m3 in de WSL home folder.
home\
bge-3m\
1_Pooling\
config.json
pytorch_model.bin
tokenizer_config.json
tokenizer.json
special_tokens_map.json
sentence_bert_config.json
modules.json
config_sentence_transformers.json
config.jsonLLM RAG COMBI Script #
Hieronder een script waarbij de context RAG index builder is ingebouwd naast het praten met het LLM model, en als extra ook een commandolijn optie om een ScentenceTransformer te kiezen, de bestandnaam van de rag_index wordt ook op basis van de keuze aangemaakt.
Gebruik:
# Standaard (MiniLM) (Lokale map ./paraphrase-multilingual-MiniLM-L12-v2)
python3 llm_test_mistral_rag.py --build
python3 llm_test_mistral_rag.py
# Expliciet met HF-naam (Lokale map ./paraphrase-multilingual-MiniLM-L12-v2)
python3 llm_test_mistral_rag.py --build --st paraphrase-multilingual-MiniLM-L12-v2
python3 llm_test_mistral_rag.py --st paraphrase-multilingual-MiniLM-L12-v2
# Lokale map ./bge-m3
python3 llm_test_mistral_rag.py --build --st bge-m3
python3 llm_test_mistral_rag.py --st bge-m3Index-bestanden worden dan bv:rag_index_paraphrase-multilingual-MiniLM-L12-v2.npzrag_index_bge-m3.npz
etc.
Het script is samen met ChatGPT opgebouwd en gefinetuned.
import os
os.environ["LLAMA_LOG_LEVEL"] = "ERROR"
import time
import re
import glob
from typing import List, Tuple
import numpy as np
from sentence_transformers import SentenceTransformer
from llama_cpp import Llama
import docx2txt
from pypdf import PdfReader
from bs4 import BeautifulSoup
# === ANSI COLORS ===
RESET = "\033[0m"
BOLD = "\033[1m"
DIM = "\033[2m"
FG_RED = "\033[31m"
FG_GREEN = "\033[32m"
FG_YELLOW = "\033[33m"
FG_BLUE = "\033[34m"
FG_MAGENTA = "\033[35m"
FG_CYAN = "\033[36m"
FG_WHITE = "\033[37m"
# Typing delay per token (0.0 = zo snel mogelijk; 0.01 geeft "type"-effect)
TYPING_DELAY = 0.01
# === Model config ===
MODEL_PATH = r"Mistral-7B-Instruct-v0.3.Q4_K_M.gguf" # <-- pas dit pad aan
# === Paths / RAG config ===
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
DOCS_FOLDER = os.path.join(SCRIPT_DIR, "docs")
# LET OP: INDEX_FILE blijft voor compat-comment,
# maar we gaan dynamisch per embedder een eigen indexbestand maken.
INDEX_FILE = os.path.join(SCRIPT_DIR, "rag_index.npz")
# Standaard SentenceTransformer-model (als --st niet wordt opgegeven)
DEFAULT_ST_MODEL = "paraphrase-multilingual-MiniLM-L12-v2"
def get_index_file(st_model: str) -> str:
"""
Maak een index-bestandsnaam op basis van het embedding-model.
Voorbeelden:
paraphrase-multilingual-MiniLM-L12-v2 -> rag_index_paraphrase-multilingual-MiniLM-L12-v2.npz
/pad/naar/bge-m3 -> rag_index_bge-m3.npz
"""
base = os.path.basename(st_model)
safe = re.sub(r"[^A-Za-z0-9_.-]+", "_", base)
return os.path.join(SCRIPT_DIR, f"rag_index_{safe}.npz")
# RAG parameters
MAX_CHARS_CHUNK = 1000
OVERLAP_CHARS = 300
MAX_CHARS_DOC = 200_000
TOP_K = 10 # aantal chunks naar LLM
DOC_TOP_K = 10 # aantal documenten eerst kiezen
RAG_ENABLED = False
_chunk_embeddings = None
_chunks: List[str] | None = None
_chunk_doc_ids = None
_doc_embeddings = None
_doc_titles: List[str] | None = None
_doc_texts: List[str] | None = None
_doc_to_chunk_indices = None
_embed_model: SentenceTransformer | None = None
# LLM wordt nu lazy geladen (niet meer bij import)
_llm: Llama | None = None
# ========= HULP: tekst opschonen =========
def clean_text(text: str) -> str:
"""Maak HTML/PDF-naar-tekst output compacter en leesbaarder."""
text = text.replace("\r\n", "\n").replace("\r", "\n")
lines = []
for line in text.split("\n"):
line = line.strip()
if not line:
continue
line = re.sub(r"[ \t]+", " ", line)
lines.append(line)
return "\n".join(lines).strip()
# ========= HULP: documenten inlezen =========
def extract_text_from_file(path: str) -> str:
"""Zet een bestand (.txt, .md, .docx, .pdf, .htm, .html) om naar platte tekst."""
ext = os.path.splitext(path)[1].lower()
try:
if ext in {".txt", ".md"}:
with open(path, "r", encoding="utf-8", errors="ignore") as f:
text = f.read()
elif ext == ".docx":
text = docx2txt.process(path) or ""
elif ext == ".pdf":
text_pages = []
reader = PdfReader(path)
for page in reader.pages:
t = page.extract_text() or ""
text_pages.append(t)
text = "\n".join(text_pages)
elif ext in {".htm", ".html"}:
with open(path, "r", encoding="utf-8", errors="ignore") as f:
html = f.read()
soup = BeautifulSoup(html, "html.parser")
for tag in soup(["script", "style", "noscript"]):
tag.decompose()
parts = list(soup.stripped_strings)
text = "\n".join(parts)
else:
print(f"[RAG] Extensie niet ondersteund: {ext} voor {path}")
return ""
text = clean_text(text)
if not text:
print(f"[RAG] Geen tekst in {path}")
return ""
if len(text) > MAX_CHARS_DOC:
print(f"[RAG] Waarschuwing: {path} is {len(text)} chars, knip af op {MAX_CHARS_DOC}.")
text = text[:MAX_CHARS_DOC]
return text
except Exception as e:
print(f"[RAG] Fout bij lezen van {path}: {e}")
return ""
def chunk_text(text: str, max_chars: int = 800, overlap: int = 200) -> List[str]:
"""Knip lange tekst op in overlappende brokken van max_chars."""
if overlap < 0 or overlap >= max_chars:
raise ValueError(f"Overlap ({overlap}) moet 0 <= overlap < max_chars ({max_chars}) zijn")
chunks: List[str] = []
start = 0
n = len(text)
while start < n:
end = min(start + max_chars, n)
chunk = text[start:end].strip()
if chunk:
chunks.append(chunk)
if end == n:
break
start = end - overlap
if start < 0:
start = 0
if start >= n:
break
return chunks
# ========= INDEX BUILD (hiërarchisch) =========
def build_rag_index(st_model: str):
"""
Bouw hiërarchische RAG-index en sla op naar een model-specifiek indexbestand.
Let op:
- st_model kan een HF-modelnaam zijn of een pad/map naar een lokaal model.
"""
from sentence_transformers import SentenceTransformer as _ST
print(f"[RAG] Laad embedding-model: {st_model}")
embed_model_local = _ST(st_model)
print(f"[RAG] Documenten inlezen uit: {DOCS_FOLDER}")
pattern = os.path.join(DOCS_FOLDER, "*")
files = sorted(glob.glob(pattern))
if not files:
print(f"[RAG] Geen bestanden gevonden in {DOCS_FOLDER}")
return
doc_texts: List[str] = []
doc_titles: List[str] = []
all_chunks: List[str] = []
chunk_doc_ids: List[int] = []
doc_chunk_ranges: List[Tuple[int, int]] = []
for doc_id, path in enumerate(files):
if not os.path.isfile(path):
continue
base = os.path.basename(path)
stem, ext = os.path.splitext(base)
ext = ext.lower()
if ext not in {".txt", ".md", ".docx", ".pdf", ".htm", ".html"}:
print(f"[RAG] Sla over (extensie niet ondersteund): {base} ({ext})")
continue
print(f"[RAG] Lees document: {base} ({ext})")
text = extract_text_from_file(path)
if not text:
print(f"[RAG] -> geen bruikbare tekst, sla over.")
continue
print(f"[RAG] -> doc-lengte: {len(text)} chars")
doc_texts.append(text)
doc_titles.append(base)
chunks = chunk_text(text, max_chars=MAX_CHARS_CHUNK, overlap=OVERLAP_CHARS)
if not chunks:
print(f"[RAG] -> geen chunks gegenereerd, sla over.")
continue
start_idx = len(all_chunks)
all_chunks.extend(chunks)
end_idx = len(all_chunks)
doc_chunk_ranges.append((start_idx, end_idx))
for _ in range(start_idx, end_idx):
chunk_doc_ids.append(len(doc_texts) - 1)
print(f"[RAG] -> {len(chunks)} chunks")
if not all_chunks:
print("[RAG] Geen chunks totaal. Stop.")
return
print(f"[RAG] Totaal {len(all_chunks)} chunks over {len(doc_texts)} documenten.")
print("[RAG] Chunk-embeddings berekenen...")
chunk_embeddings = embed_model_local.encode(all_chunks, convert_to_numpy=True, show_progress_bar=True)
print("[RAG] Doc-embeddings berekenen (gemiddelde van chunks per document)...")
doc_embeddings = []
for doc_id, (start_idx, end_idx) in enumerate(doc_chunk_ranges):
doc_vec = np.mean(chunk_embeddings[start_idx:end_idx], axis=0)
doc_embeddings.append(doc_vec)
doc_embeddings = np.vstack(doc_embeddings)
index_file = get_index_file(st_model)
print(f"[RAG] Index opslaan naar {index_file}...")
np.savez_compressed(
index_file,
chunk_embeddings=chunk_embeddings,
chunks=np.array(all_chunks, dtype=object),
chunk_doc_ids=np.array(chunk_doc_ids, dtype=np.int32),
doc_embeddings=doc_embeddings,
doc_titles=np.array(doc_titles, dtype=object),
doc_texts=np.array(doc_texts, dtype=object),
st_model=st_model, # modelnaam meeschrijven voor sanity-check
)
print("[RAG] Klaar: hiërarchische index gebouwd.")
# ========= RAG INIT / RETRIEVAL =========
def _cosine_sim(a: np.ndarray, b: np.ndarray) -> np.ndarray:
a = a / (np.linalg.norm(a) + 1e-10)
b = b / (np.linalg.norm(b, axis=1, keepdims=True) + 1e-10)
return np.dot(b, a)
def init_rag(st_model: str):
"""Laad hiërarchische RAG-index en embedding-model voor het opgegeven st_model."""
global RAG_ENABLED
global _chunk_embeddings, _chunks, _chunk_doc_ids
global _doc_embeddings, _doc_titles, _doc_texts
global _doc_to_chunk_indices, _embed_model
try:
index_file = get_index_file(st_model)
if not os.path.exists(index_file):
print(f"{FG_YELLOW}[RAG] Geen indexbestand gevonden ({index_file}). RAG uitgeschakeld.{RESET}")
return
data = np.load(index_file, allow_pickle=True)
_chunk_embeddings = data["chunk_embeddings"]
_chunks = data["chunks"].tolist()
_chunk_doc_ids = data["chunk_doc_ids"]
_doc_embeddings = data["doc_embeddings"]
_doc_titles = data["doc_titles"].tolist()
_doc_texts = data["doc_texts"].tolist()
_doc_to_chunk_indices = {}
for idx, d_id in enumerate(_chunk_doc_ids):
_doc_to_chunk_indices.setdefault(int(d_id), []).append(idx)
stored_st = data.get("st_model", None)
if stored_st is not None and str(stored_st) != st_model:
print(
f"{FG_YELLOW}[RAG] WAARSCHUWING: index is gebouwd met ander embedding-model: {stored_st} "
f"(nu gevraagd: {st_model}){RESET}"
)
# Embedding-model laden voor retrieval
_embed_model = SentenceTransformer(st_model)
RAG_ENABLED = True
print(
f"{FG_CYAN}[RAG] Hiërarchische index geladen: "
f"{len(_doc_titles)} docs, {len(_chunks)} chunks. RAG is actief.{RESET}"
)
print(f"{FG_CYAN}[RAG] Embedding-model: {st_model}{RESET}")
except Exception as e:
print(f"{FG_RED}[RAG] Kon RAG-index niet laden: {e}. RAG uitgeschakeld.{RESET}")
RAG_ENABLED = False
def rag_context_for_question(question: str) -> str:
"""
Professionele hiërarchische retrieval:
Stap 1: embed vraag
Stap 2: document-ranking (embedding + keyword score op doc_texts)
Stap 3: kies beste DOC_TOP_K documenten
Stap 4: chunk-ranking binnen deze documenten (embedding + keyword score)
Stap 5: kies TOP_K chunks en voeg ze samen tot 1 context-string
"""
if (
not RAG_ENABLED
or _embed_model is None
or _chunk_embeddings is None
or _doc_embeddings is None
or _doc_to_chunk_indices is None
):
return ""
try:
# eenvoudige keyword / naam / jaar extractie
raw_tokens = re.findall(r"\w+", question, flags=re.UNICODE)
tokens = [t for t in raw_tokens if len(t) >= 3]
q_lower_tokens = [t.lower() for t in tokens]
name_tokens = [t for t in raw_tokens if len(t) >= 3 and t[0].isupper()]
name_lower = [t.lower() for t in name_tokens]
year_tokens = [t for t in tokens if t.isdigit() and len(t) == 4]
q_emb = _embed_model.encode([question], convert_to_numpy=True)[0]
# ===== 1) DOCUMENT-RANKING =====
doc_sims = _cosine_sim(q_emb, _doc_embeddings)
doc_scores = []
for doc_id, (doc_text, title) in enumerate(zip(_doc_texts, _doc_titles)):
text = (title + "\n" + doc_text).lower()
kw_hits = 0
for w in q_lower_tokens:
if re.search(r"\b" + re.escape(w) + r"\b", text):
kw_hits += 1
name_hits = 0
for w in name_lower:
if re.search(r"\b" + re.escape(w) + r"\b", text):
name_hits += 1
year_hits = 0
for y in year_tokens:
if y in text:
year_hits += 1
# eenvoudige keyword-score
kw_score = (
kw_hits
+ 2 * name_hits
+ 2 * year_hits
)
score = kw_score + float(doc_sims[doc_id])
doc_scores.append((doc_id, score, kw_score, float(doc_sims[doc_id])))
doc_scores.sort(key=lambda x: x[1], reverse=True)
max_kw = max(ds[2] for ds in doc_scores) if doc_scores else 0
if max_kw > 0:
# als er keyword-hits zijn, filter documenten zonder keyword-hits eruit
doc_scores = [ds for ds in doc_scores if ds[2] > 0]
top_docs = doc_scores[:DOC_TOP_K]
if not top_docs:
# fallback: puur over alle chunks
sims = _cosine_sim(q_emb, _chunk_embeddings)
top_idx = np.argsort(-sims)[:TOP_K]
selected = [_chunks[i] for i in top_idx]
return "\n\n---\n\n".join(selected).strip()
# ===== 2) CHUNK-RANKING BINNEN TOP-DOCS =====
candidate_chunk_indices = []
for doc_id, _, _, _ in top_docs:
candidate_chunk_indices.extend(_doc_to_chunk_indices.get(doc_id, []))
if not candidate_chunk_indices:
sims = _cosine_sim(q_emb, _chunk_embeddings)
top_idx = np.argsort(-sims)[:TOP_K]
selected = [_chunks[i] for i in top_idx]
return "\n\n---\n\n".join(selected).strip()
emb_subset = _chunk_embeddings[candidate_chunk_indices]
chunk_sims = _cosine_sim(q_emb, emb_subset)
scored_chunks = []
for local_idx, global_idx in enumerate(candidate_chunk_indices):
ch = _chunks[global_idx]
ch_low = ch.lower()
kw_hits = 0
for w in q_lower_tokens:
if re.search(r"\b" + re.escape(w) + r"\b", ch_low):
kw_hits += 1
name_hits = 0
for w in name_lower:
if re.search(r"\b" + re.escape(w) + r"\b", ch_low):
name_hits += 1
year_hits = 0
for y in year_tokens:
if y in ch_low:
year_hits += 1
kw_score = (
kw_hits
+ 2 * name_hits
+ 2 * year_hits
)
sim = float(chunk_sims[local_idx])
combined = kw_score + sim
scored_chunks.append((global_idx, combined, kw_score, sim))
max_chunk_kw = max(sc[2] for sc in scored_chunks) if scored_chunks else 0
if max_chunk_kw > 0:
# als er keyword-hits zijn, filter chunks zonder keyword-hits eruit
scored_chunks = [sc for sc in scored_chunks if sc[2] > 0]
scored_chunks.sort(key=lambda x: x[1], reverse=True)
top_chunks = scored_chunks[:TOP_K]
selected_chunks = [_chunks[gidx] for (gidx, _, _, _) in top_chunks]
context = "\n\n---\n\n".join(selected_chunks)
return context.strip()
except Exception as e:
print(f"{FG_RED}[RAG] Fout tijdens retrieval: {e}{RESET}")
return ""
# ========= PERSONA / MODES =========
MODES = {
"default": {
"description": "Standaardmodus – professioneel, behulpzaam, rustig, directe antwoorden.",
"system": (
"Je bent Mistral-7B, een krachtige Nederlandstalige chatbot.\n"
"Je antwoordt ALTIJD in helder, vloeiend en natuurlijk Nederlands.\n"
"\n"
"BELANGRIJKE REGELS:\n"
"- Geef ALLEEN het uiteindelijke antwoord, niet je interne redenering.\n"
"- Laat geen chain-of-thought of verborgen denkstappen zien.\n"
"- Speel geen systeem- of gebruikersrollen na.\n"
"- Geen onnodige meta-commentaar, excuses of vulling.\n"
"- Hou antwoorden feitelijk, precies en behulpzaam.\n"
"- Leg uit in duidelijke, gestructureerde stappen als dat nuttig is.\n"
"- Als de gebruiker om code vraagt, geef dan nette, uitvoerbare code.\n"
"- Bij complexe vragen: geef vooral de conclusie met een korte onderbouwing.\n"
"\n"
"Je toon: professioneel, rustig, vriendelijk en to-the-point."
),
"temperature": 0.6,
"top_p": 0.92,
"max_tokens": 2048,
},
"creative": {
"description": "Creatieve modus – beeldend, verhalend, speels, maar toch gefocust.",
"system": (
"Je bent Mistral-7B in een creatieve modus.\n"
"Je reageert in vloeiend en expressief Nederlands.\n"
"\n"
"Je creatieve stijl:\n"
"- Verbeeldingsrijk, levendig en boeiend\n"
"- Soepele, natuurlijke zinnen met eventueel humor\n"
"- Je mag metaforen, beelden en verhaalelementen gebruiken\n"
"- Je mag ideeën op een verrassende maar zinvolle manier uitbreiden\n"
"\n"
"Belangrijke regels:\n"
"- Laat geen chain-of-thought of interne redenering zien.\n"
"- Geen onnodige meta-commentaar of zelfreflectie.\n"
"- Blijf binnen de intentie van de gebruiker; ga niet onnodig off-topic.\n"
"- Als de gebruiker om een verhaal of creatieve tekst vraagt, lever iets moois.\n"
"- Als de gebruiker om ideeën vraagt, geef meerdere, originele suggesties.\n"
"- Vermijd eindeloos uitweiden; creativiteit blijft gericht en duidelijk."
),
"temperature": 0.9,
"top_p": 0.95,
"max_tokens": 768,
},
"expert": {
"description": "Technische expertmodus – precies, gestructureerd en deskundig.",
"system": (
"Je bent Mistral-7B in technische expertmodus.\n"
"Je antwoordt altijd in professioneel, nauwkeurig en helder Nederlands.\n"
"\n"
"Je rol:\n"
"- Gedraag je als een senior technisch expert / domeinspecialist.\n"
"- Geef gestructureerde, goed onderbouwde uitleg.\n"
"- Gebruik correcte terminologie en relevante concepten.\n"
"- Geef korte motivaties en samenvattingen wanneer nuttig.\n"
"\n"
"Belangrijke regels:\n"
"- Laat geen chain-of-thought, interne redenering of stap-voor-stap nadenken zien.\n"
"- Geef bondige conclusies met korte toelichting.\n"
"- Geen onnodige vulling, excuses of meta-commentaar.\n"
"- Blijf feitelijk en gebaseerd op echte kennis.\n"
"- Bij vergelijkingen: maak duidelijke, gestructureerde onderscheidingen.\n"
"- Bij berekeningen: geef het juiste resultaat zonder je tussenstappen te tonen."
),
"temperature": 0.55,
"top_p": 0.9,
"max_tokens": 640,
},
"code": {
"description": "Developer / Code-only modus – gefocust op code, minimale tekst.",
"system": (
"Je bent Mistral-7B in developer / code-only modus.\n"
"Je antwoorden zijn kort en in helder Nederlands, maar de focus ligt op code.\n"
"\n"
"Je gedrag:\n"
"- Als de gebruiker om code vraagt, geef ALLEEN een codeblok.\n"
"- Geen uitleg tenzij daar expliciet om wordt gevraagd.\n"
"- Code moet schoon, minimaal en direct uitvoerbaar zijn.\n"
"- Gebruik bij voorkeur algemeen ondersteunde libraries, tenzij anders gevraagd.\n"
"- Pas best practices toe voor leesbaarheid en onderhoudbaarheid.\n"
"\n"
"Belangrijke regels:\n"
"- Laat geen chain-of-thought of interne redenering zien.\n"
"- Geen extra commentaar, excuses of meta-zinnen.\n"
"- Herhaal de vraag niet.\n"
"- Bij het aanpassen van code: geef altijd de volledige, bijgewerkte versie.\n"
"- Bij bugs: geef de gecorrigeerde code."
),
"temperature": 0.6,
"top_p": 0.9,
"max_tokens": 512,
},
}
DEFAULT_MODE = "default"
CTX_WINDOW = 8192 # moet overeenkomen met n_ctx in create_llm()
# === LLM init ===
def create_llm():
"""Maak een Llama-instance voor het gekozen GGUF-model."""
return Llama(
model_path=MODEL_PATH,
n_ctx=CTX_WINDOW,
n_threads=12,
n_gpu_layers=0,
seed=-1,
verbose=False,
)
# === Prompt builder ===
def build_chatml_prompt(messages, mode_name: str) -> str:
mode = MODES.get(mode_name, MODES[DEFAULT_MODE])
system_message = mode["system"]
parts: List[str] = []
parts.append("<|system|>\n")
parts.append(system_message)
parts.append("</s>\n")
for msg in messages:
role = msg["role"]
content = msg["content"]
if role == "user":
parts.append("<|user|>\n")
parts.append(content)
parts.append("</s>\n")
elif role == "assistant":
parts.append("<|assistant|>\n")
parts.append(content)
parts.append("</s>\n")
elif role == "system":
parts.append("<|system|>\n")
parts.append(content)
parts.append("</s>\n")
else:
parts.append("<|user|>\n")
parts.append(content)
parts.append("</s>\n")
parts.append("<|assistant|>\n")
return "".join(parts)
def print_modes():
print(f"{FG_CYAN}Beschikbare modi:{RESET}")
for name, cfg in MODES.items():
marker = "*" if name == DEFAULT_MODE else " "
print(f" {marker} {FG_YELLOW}{name:8s}{RESET} - {cfg['description']}")
# === REPL ===
def start_repl(st_model: str):
"""
Start de REPL met RAG.
- st_model bepaalt welk SentenceTransformer-model + welke index gebruikt wordt.
"""
global _llm
# RAG initialiseren voor het gekozen model
init_rag(st_model)
# LLM pas hier laden (niet bij import)
if _llm is None:
_llm = create_llm()
current_mode = DEFAULT_MODE
history = []
last_stats = None
print(
f"{FG_MAGENTA}{BOLD}=======================================================\n"
" Mistral-7B REPL – streaming, multi-persona + RAG (Nederlands)\n"
" Commando's:\n"
" /exit – stop\n"
" /quit – stop\n"
" /reset – wis conversatiegeschiedenis\n"
" /mode – toon beschikbare modi\n"
" /mode <naam> – wissel modus (default | creative | expert | code)\n"
" /stats – toon statistieken van het laatste antwoord\n"
"=======================================================\n"
f"{RESET}"
)
print(
f"Huidige modus: {FG_YELLOW}{current_mode}{RESET} "
f"({MODES[current_mode]['description']})"
)
def count_tokens(text: str) -> int:
"""Tel tokens met behulp van het LLM-tokenizer."""
assert _llm is not None
return len(_llm.tokenize(text.encode("utf-8")))
while True:
try:
user_input = input(f"\n{FG_GREEN}Jij{RESET}: ").strip()
except EOFError:
print(f"\n{FG_RED}EOF, afsluiten…{RESET}")
break
if not user_input:
continue
low = user_input.lower()
if low in ("/exit", "/quit"):
print(f"{FG_RED}Afsluiten…{RESET}")
break
if low == "/reset":
history = []
print(f"{FG_CYAN}Conversatiegeschiedenis gewist.{RESET}")
continue
if low == "/mode":
print_modes()
continue
if low.startswith("/mode "):
parts_cmd = user_input.split()
if len(parts_cmd) >= 2:
requested = parts_cmd[1].lower()
if requested in MODES:
current_mode = requested
print(
f"{FG_CYAN}Modus gewijzigd naar:{RESET} "
f"{FG_YELLOW}{current_mode}{RESET}"
)
print(f" {MODES[current_mode]['description']}")
else:
print(f"{FG_RED}Onbekende modus:{RESET} {requested}")
print_modes()
else:
print_modes()
continue
if low == "/stats":
if last_stats is None:
print(f"{FG_YELLOW}Nog geen statistieken. Stel eerst een vraag.{RESET}")
else:
print(f"\n{FG_CYAN}Statistieken laatste antwoord:{RESET}")
print(f" Modus: {last_stats['mode']}")
print(f" Prompt tokens: {last_stats['prompt_tokens']}")
print(f" Antwoord tokens: {last_stats['completion_tokens']}")
print(f" Totaal tokens: {last_stats['total_tokens']}")
print(f" Genereertijd: {last_stats['time_sec']:.3f} s")
print(f" Tokens/sec (gen): {last_stats['tokens_per_sec']:.2f}")
continue
# === Normale user input → RAG-context + vraag ===
augmented_user = user_input
if RAG_ENABLED:
context = rag_context_for_question(user_input)
if context:
parts_ctx = context.split("\n\n---\n\n")
print(f"{FG_CYAN}[RAG] {len(parts_ctx)} chunks geselecteerd (TOP_K={TOP_K}):{RESET}")
for idx, chunk in enumerate(parts_ctx, start=1):
snippet = chunk[:250].replace("\n", " ")
print(f"{DIM} [chunk {idx}] {snippet}...{RESET}")
print()
augmented_user = (
"Je krijgt hieronder CONTEXT uit documenten tussen <CONTEXT> en </CONTEXT>.\n"
"Gebruik deze context om de vraag te beantwoorden.\n"
"Baseer je antwoord zoveel mogelijk op de informatie in de context.\n"
"Als de informatie niet expliciet in de context staat, zeg dat dan eerlijk.\n\n"
"<CONTEXT>\n"
f"{context}\n"
"</CONTEXT>\n\n"
f"VRAAG:\n{user_input}"
)
history.append({"role": "user", "content": augmented_user})
mode_cfg = MODES.get(current_mode, MODES[DEFAULT_MODE])
prompt = build_chatml_prompt(history, current_mode)
# === Context-veiligheid: check promptlengte vs context window ===
prompt_tokens = count_tokens(prompt)
# Hou wat marge over (bijv. 64 tokens) om errors te vermijden
available_for_gen = CTX_WINDOW - prompt_tokens - 64
if available_for_gen <= 0:
# Te vol: probeer eerst history te resetten maar huidige vraag te behouden
print(f"{FG_YELLOW}[CTX] Context is vol, history wordt gewist behalve laatste vraag.{RESET}")
last_user = history[-1] # dit is de augmented_user van zojuist
history = [last_user]
prompt = build_chatml_prompt(history, current_mode)
prompt_tokens = count_tokens(prompt)
available_for_gen = CTX_WINDOW - prompt_tokens - 64
if available_for_gen <= 0:
# Zelfs met alleen de huidige vraag is er geen ruimte -> geef kort antwoord zonder crash
print(f"{FG_RED}[CTX] Prompt past niet in context window, antwoord wordt sterk ingekort.{RESET}")
available_for_gen = 64 # minimale fallback
gen_max_tokens = min(mode_cfg["max_tokens"], max(16, available_for_gen))
print(
f"{FG_BLUE}{current_mode.capitalize()}{RESET} "
f"{DIM}(prompt_tokens={prompt_tokens}, max_gen={gen_max_tokens}){RESET}: ",
end="",
flush=True,
)
start_time = time.time()
full_answer = ""
try:
assert _llm is not None
for chunk in _llm(
prompt,
max_tokens=gen_max_tokens,
temperature=mode_cfg["temperature"],
top_p=mode_cfg["top_p"],
stop=["</s>", "<|user|>", "<|system|>"],
stream=True,
):
token = chunk["choices"][0]["text"]
full_answer += token
print(token, end="", flush=True)
if TYPING_DELAY > 0.0:
time.sleep(TYPING_DELAY)
except ValueError as e:
# extra safeguard als llama_cpp alsnog klaagt
print(f"\n{FG_RED}[LLM] Fout tijdens generatie: {e}{RESET}")
full_answer = "[Interne fout: prompt was te groot voor het contextvenster.]"
end_time = time.time()
print(f"\n{DIM}-----------------------------{RESET}\n")
clean_answer = full_answer.split("</s>")[0].strip()
history.append({"role": "assistant", "content": clean_answer})
elapsed = max(end_time - start_time, 1e-6)
completion_tokens = count_tokens(clean_answer)
total_tokens = prompt_tokens + completion_tokens
tokens_per_sec = completion_tokens / elapsed
last_stats = {
"mode": current_mode,
"prompt_tokens": prompt_tokens,
"completion_tokens": completion_tokens,
"total_tokens": total_tokens,
"time_sec": elapsed,
"tokens_per_sec": tokens_per_sec,
}
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Mistral-7B REPL met hiërarchische RAG")
parser.add_argument(
"--build",
action="store_true",
help="Bouw RAG-index (model-specifiek rag_index_*.npz) vanuit docs/",
)
parser.add_argument(
"--st",
type=str,
default=DEFAULT_ST_MODEL,
help=(
"Naam of pad van SentenceTransformer-model "
f"(default: {DEFAULT_ST_MODEL}). "
"Als er een map met deze naam naast het script bestaat, wordt die gebruikt."
),
)
args = parser.parse_args()
# Bepaal daadwerkelijk modelpad voor SentenceTransformer:
# - als er een directory met die naam bestaat naast het script -> gebruik die
# - anders: gebruik de string direct (HF modelnaam of absoluut/relatief pad)
st_arg = args.st
candidate_local = os.path.join(SCRIPT_DIR, st_arg)
if os.path.isdir(candidate_local):
st_model_path = candidate_local
else:
st_model_path = st_arg
if args.build:
build_rag_index(st_model_path)
else:
start_repl(st_model_path)Q&A: rag_index.npz #
Na het indexeren van de extra context teksten wordt het bestand rag_index.npz aangemaakt, dit is een ZIP bestand en heeft de volgende inhoud:
doc_titles.npy
doc_texts.npy
doc_embeddings.npy
chunks.npy
chunk_embeddings.npy
chunk_doc_ids.npyWat houden die bestanden nou precies in? Uitleg per bestand:
Dit komt rechtstreeks uit de document/chunk-architectuur van jouw RAG-index.
1. doc_titles.npy #
Wat is het?
Een array met één titel per document.
Bijvoorbeeld:
["bestand1.txt", "bestand2.txt", "feed.xml"]Doel:
- Snel zien welke “hoofddocumenten” je hebt.
- Wordt gebruikt bij document-level retrieval (stap 1 van de pipeline).
2. doc_texts.npy #
Wat is het?
Een array waarin elk item één volledig document is als ruwe platte tekst.
Bijvoorbeeld:
doc_texts[0]= hele tekst van bestand1doc_texts[1]= hele tekst van bestand2- etc.
Doel:
- Document-level embedding maken (doc_embeddings.npy)
- Snel per document zoeken → daarna pas chunk-level
Belangrijk:
Dit zijn hele documenten (soms duizenden regels).
3. doc_embeddings.npy #
Wat is het?
Een array van vectoren → één embedding per document.
Bijvoorbeeld:
shape = (N_docs, 384)Doel:
- Stap 1 in professor-grade RAG:
- “Welk document lijkt het meest op de vraag?”
Dit verkleint de zoekruimte vóór je in de chunks duikt → veel stabieler.
4. chunks.npy #
Wat is het?
Een array van kleine stukjes tekst (chunking van doc_texts).
Bijvoorbeeld:
chunks[0] = "Aanwezig: ... Afwezig: ... Besluiten: ..."
chunks[1] = "Agenda punt 2: ... Verder noemde men ..."
chunks[2] = "Uitslagen ... Beste ronde tijd ..."
Belangrijk verschil met doc_texts:
- doc_texts = complete documenten
- chunks = kleine stukjes die je model kan verwerken (~800 chars)
Dus ja: inhoud deels overlapt, maar chunks zijn “gesneden stukken” en doc_texts zijn volwaardige documenten.
5. chunk_embeddings.npy #
Wat is het?
Embedding vector voor élke chunk.
shape = (N_chunks, 384)
Doel:
- Stap 2 van RAG:
- binnen het gekozen document → welke chunks passen bij de vraag?
6. chunk_doc_ids.npy #
Wat is het?
Een array die aangeeft tot welk document elke chunk behoort.
Bijvoorbeeld:
chunk_doc_ids = [0,0,0,1,1,1,1,2,2,...]
Betekenis:
| chunk index | doc ID | betekent… |
|---|---|---|
| chunks[0] → | doc 0 | eerste document |
| chunks[3] → | doc 1 | tweede document |
| chunks[7] → | doc 2 | derde document |
Doel:
- Zodat we weten: “Deze chunk hoort bij document X”
- Nodig voor de 2-staps retrieval (document → chunk)
Tabel: Overzicht van alle bestanden #
| Bestand | Wat bevat het? | Formaat | Doel |
|---|---|---|---|
| doc_titles.npy | De bestandsnamen / titels van elk document | (N_docs,) | Snelle referentie + debug |
| doc_texts.npy | Volledige documenten als 1 string per doc | (N_docs,) | Document-level retrieval (globaal zoeken) |
| doc_embeddings.npy | Embeddings van complete documenten | (N_docs, D) | Stap 1 RAG – juiste document kiezen |
| chunks.npy | Kleine stukjes tekst (overlapping ± 800 chars) | (N_chunks,) | Fijngranulaire context voor LLM |
| chunk_embeddings.npy | Embeddings per chunk | (N_chunks, D) | Stap 2 RAG – juiste informatie vinden |
| chunk_doc_ids.npy | Links chunks → docs | (N_chunks,) | Groeperen chunks per document |