Knowledge Center
LM Studio MCP plugins en context

Inleiding #
Wanneer je LM studio hebt geïnstalleerd, kan je via MCP plugin extra functionaliteit of context meegeven aan je LLM, het mooie hiervan is dat de LLM zelf kiest en nagaat aan de hand van je vraag om een plugin te starten. Hieronder vind je enkele stappen om je op weg te helpen.
Wat is MCP?
LM Studio ondersteunt tegenwoordig “plugins” via MCP (Model Context Protocol). Dat werkt met een mcp.json configuratiebestand waarin je tools, servers of integraties definieert.
Met MCP kan een LLM lokaal:
- Externe tools starten
- Data ophalen via lokale servers
- Integreren met bv:
- Filesystem tools
- Databases
- RAG-servers
- API bridges
- Eigen Python/Node tools
Vergelijkbaar met plugins/tools zoals bij OpenAI, maar dan 100% lokaal.
MCP Script – Huidige datum en tijd #
Als je (bv Mistral 3) om de tijd vraagt, krijg je veelal dezelfde reactie terug:
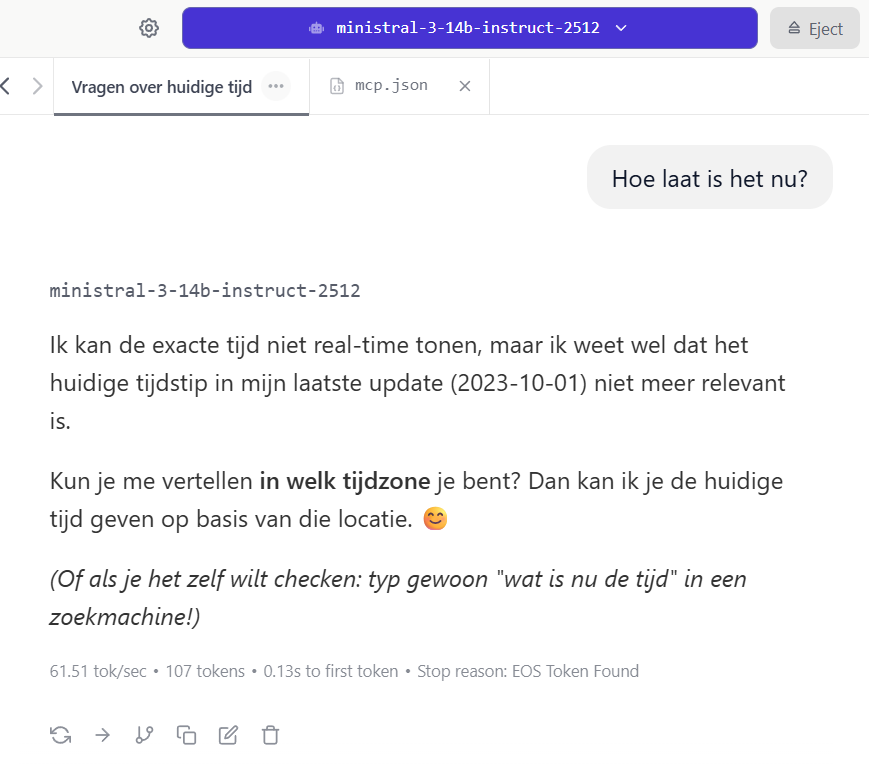
Nu gaan we een datum en tijd tool aanmaken in python zodat indien de LLM het nodig vind, deze kan aanroepen en de huidige datum en tijd als context meekrijgt om dan je vraag te beantwoorden.
Maak een map aan (bv c:\lmstudio-tools\date-time) en plaats de inhoud hieronder in een bestand genaamd date-time.py.
import sys
import json
from datetime import datetime
from zoneinfo import ZoneInfo
def send(msg: dict) -> None:
# Eén JSON per regel naar stdout
sys.stdout.write(json.dumps(msg, ensure_ascii=False) + "\n")
sys.stdout.flush()
# ========== HOOFDLOOP ==========
for line in sys.stdin:
line = line.strip()
if not line:
continue
try:
req = json.loads(line)
except Exception:
# Ongeldige JSON negeren
continue
method = req.get("method")
req_id = req.get("id")
params = req.get("params") or {}
# ===== Handshake: initialize =====
if method == "initialize":
send({
"jsonrpc": "2.0",
"id": req_id,
"result": {
"protocolVersion": "2024-11-05",
"serverInfo": {
"name": "date-time",
"version": "1.0.0"
},
"capabilities": {
"tools": {
# geen dynamische tool-lijst
"listChanged": False
}
}
}
})
# ===== tools/list =====
elif method == "tools/list":
send({
"jsonrpc": "2.0",
"id": req_id,
"result": {
"tools": [
{
"name": "date-time",
"title": "Get current date and time",
"description": (
"Geeft de huidige datum, tijd, weekdag, weeknummer en UNIX-tijd "
"voor een opgegeven IANA-tijdzone (bijv. Europe/Amsterdam). "
"Gebruik deze tool bij vragen over tijd, datum, kalenderinformatie, "
"vandaag, nu, weeknummer, of tijdzones."
),
"inputSchema": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "IANA timezone, bijv. Europe/Amsterdam",
"default": "Europe/Amsterdam"
}
},
"required": []
}
}
]
}
})
# ===== tools/call =====
elif method == "tools/call":
tool_name = params.get("name")
arguments = params.get("arguments") or {}
if tool_name == "date-time":
tzname = arguments.get("timezone", "Europe/Amsterdam")
try:
now = datetime.now(ZoneInfo(tzname))
# Nederlandse namen voor weekdagen
WEEKDAGEN_NL = [
"Maandag", "Dinsdag", "Woensdag",
"Donderdag", "Vrijdag", "Zaterdag", "Zondag"
]
# Structured return
structured = {
"timezone": tzname,
"datetime": now.strftime("%Y-%m-%d %H:%M:%S"),
"iso": now.isoformat(),
"unix": int(now.timestamp()),
"weeknummer": now.isocalendar().week, # ISO weeknummer
"weekdag": WEEKDAGEN_NL[now.weekday()] # 0 = maandag
}
# Dit is wat het MODEL echt te zien krijgt als tekst
text_answer = (
f"Het is nu {structured['datetime']} in tijdzone {structured['timezone']}.\n"
f"UNIX-tijd: {structured['unix']}\n"
f"Weeknummer: {structured['weeknummer']}\n"
f"Weekdag: {structured['weekdag']}"
)
send({
"jsonrpc": "2.0",
"id": req_id,
"result": {
# MCP verwacht 'content' als lijst met blokken
"content": [
{
"type": "text",
"text": text_answer
}
],
# Extra gestructureerde data waar slimme clients iets mee kunnen
"structuredContent": structured,
"isError": False
}
})
except Exception as e:
send({
"jsonrpc": "2.0",
"id": req_id,
"result": {
"content": [
{
"type": "text",
"text": f"Fout bij ophalen van de tijd: {e}"
}
],
"isError": True
}
})
else:
# Onbekende tool
send({
"jsonrpc": "2.0",
"id": req_id,
"error": {
"code": -32602,
"message": f"Unknown tool: {tool_name}"
}
})
# Andere methods (nog) niet ondersteund
else:
send({
"jsonrpc": "2.0",
"id": req_id,
"error": {
"code": -32601,
"message": f"Unknown method: {method}"
}
})
Wat heel belangrijk hier is is dit veld:
"description": (
"Geeft de huidige datum, tijd, weekdag, weeknummer en UNIX-tijd "
"voor een opgegeven IANA-tijdzone (bijv. Europe/Amsterdam). "
"Gebruik deze tool bij vragen over tijd, datum, kalenderinformatie, "
"vandaag, nu, weeknummer, of tijdzones."
),Waarom is de omschrijving zo uitgebreid (dan alleen het woord tijd?) #
Dat komt omdat MCP-tools geen triggers hebben in de code zelf. Tools worden getriggerd door het LLM, gebaseerd op:
- de toolbeschrijving
- de naam van de tool
- de inputSchema
- het systeem-prompt dat jij gebruikt
- de context waarin woorden verschijnen (“tijd”, “datum”, “date”, “today”, etc.)
We kunnen de tool beter laten triggeren door het gebruik van “datum”, “date”, “today”, “weekdag”, “calendar”, etc. toe te voegen aan:
- de description
- de title
- optioneel de systemprompt in LM Studio
Dat helpt het model beter begrijpen dat de tool meer is dan alleen tijd.
Waarom lijkt het alsof er “meerdere scripts in één script” zitten? #
Omdat een MCP-server één proces is dat:
- stdin leest ← LM Studio stuurt MCP-berichten
- stdout terugstuurt ← jouw script reageert met JSON-RPC
- één of meerdere tools aanbiedt zoals
get_timepingget_weatherconvert_currency- etc.
Dus jouw script is niet één functie, maar een dispatcher:
het luistert naar:
initializetools/listtools/call
en afhankelijk van de aanvraag beslist het script wat te doen.
Dat is exact zoals het hoort binnen het MCP-protocol.
Het lijkt daardoor “groot” of “multi-script”, maar dit is normaal bij protocolservers.
Hoe MCP-servers zijn opgebouwd #
Een typische MCP-server bevat altijd
Initialize handler
Wordt 1× aangeroepen bij start
tools/list handler
Geeft alle tools terug die jouw server aanbiedt
tools/call handler
Wordt aangeroepen telkens wanneer een tool door het model gebruikt moet worden.
Al deze handlers zitten in hetzelfde script.
Dat is standaard.
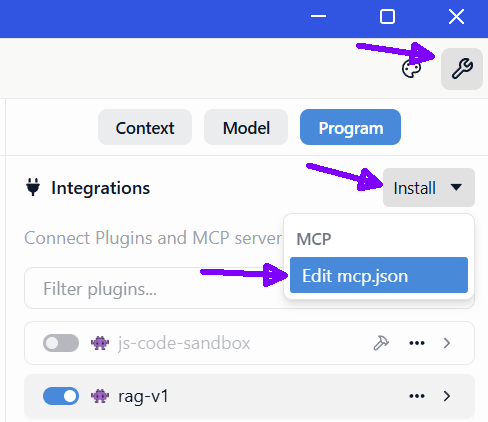
Nadat je dit bestand hebt aangemaakt moeten we in LM studio nog vertellen waar hij staat doormiddel mcp.json te bewerken.
Om naar een script te verwijzen (en dat het ingelezen wordt in LM studio) moet je het bestand mcp.json bewerken, je vind een optie bij de instellingen:
Dit is een minimale geldige MCP config:
{
"mcpServers": {}
}Zonder dit bestand:
– Geen tools
– Geen plugins
– Geen externe integraties
Laten we een functie aanroepen die de huidige tijd ophaalt en weergeeft als context aan de LLM, voeg deze code toe in mcp.json:
{
"mcpServers": {
"date-time": {
"command": "python",
"args": [
"c:/lmstudio-tools/date-time/date-time.py"
]
}
}
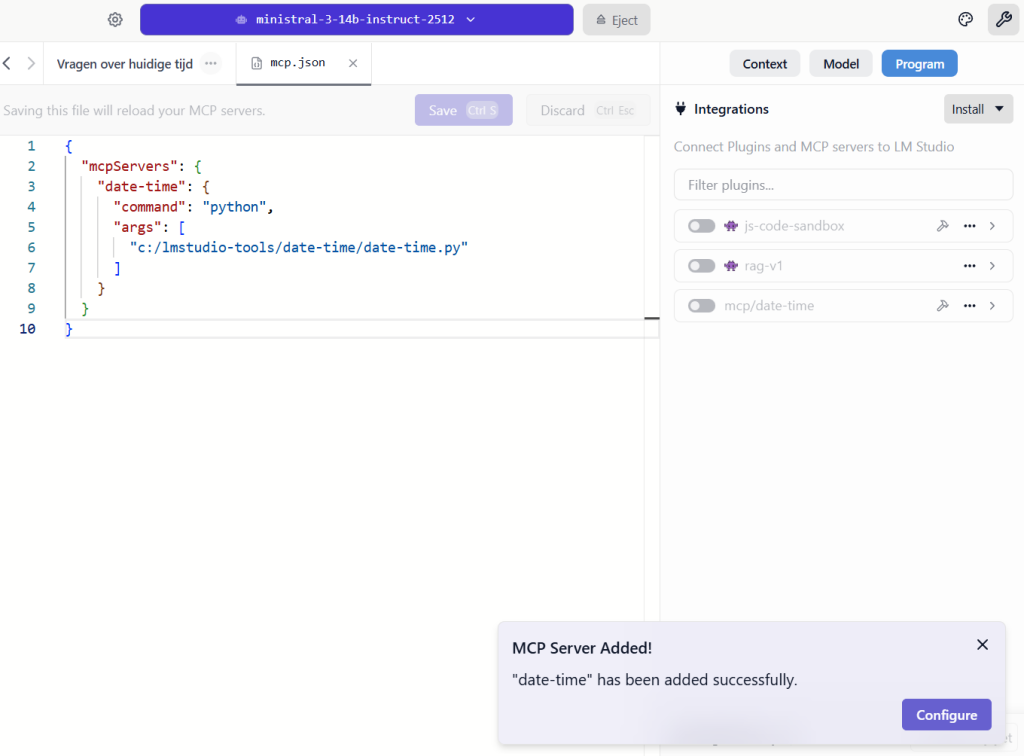
}Nadat je op “save” hebt gedrukt, wordt de tool gevalideerd door LM studio, indien alles goed is gegaan, zie je onderstaande melding:
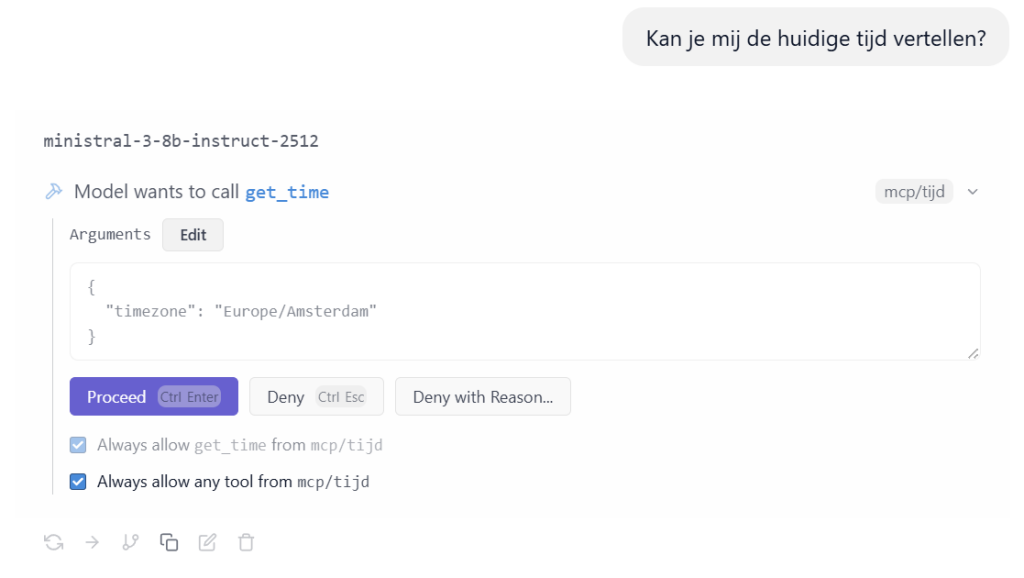
Als je nu om de tijd vraag zie je dat het LLM de tool aanroept, geef toestemming om het uit te voeren:
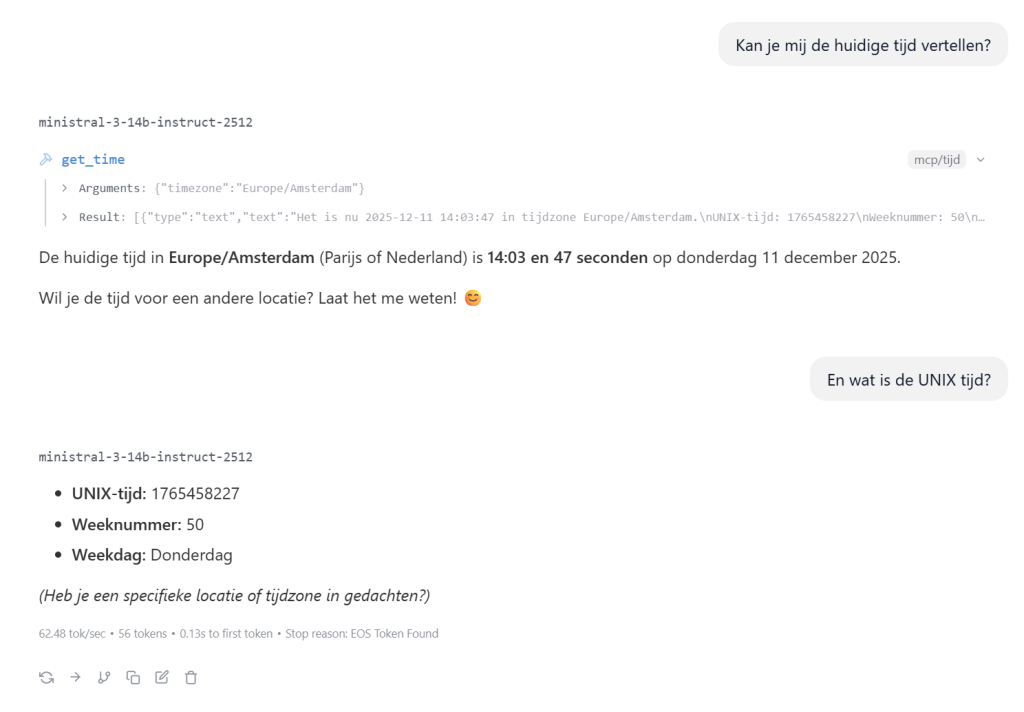
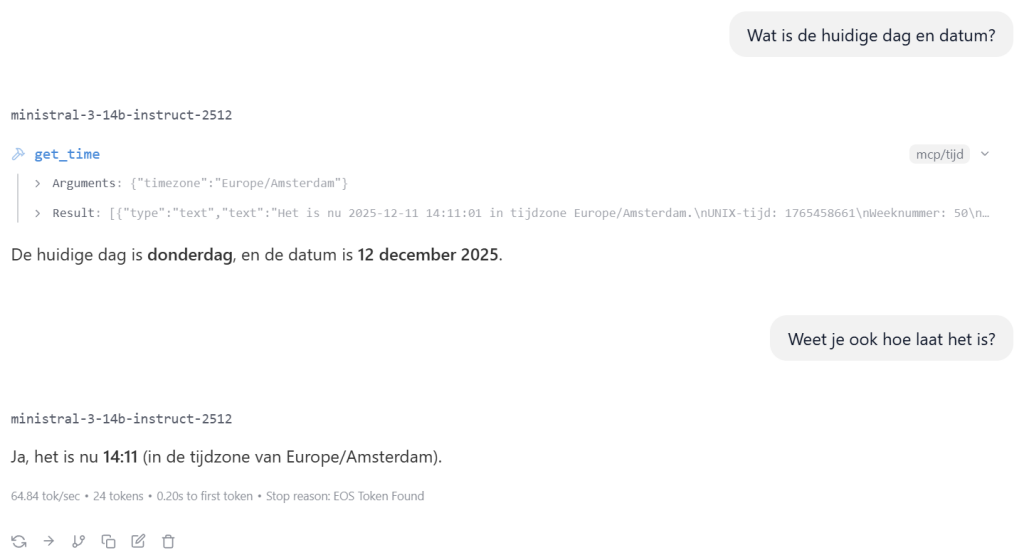
Indien nu alles goed staat kan je de LLM om de huidige datum en/of tijd vragen:
Extra versterking: systemprompt uitbreiden #
In LM Studio kun je in het system prompt dit toevoegen:
Als de gebruiker vraagt naar “tijd”, “datum”, “vandaag”, “nu”, “weekdag”, “weeknummer”, “kalender”, of vergelijkbare begrippen, gebruik dan altijd de tool
date-timeom de actuele datum en tijd op te halen.
Dan is het vrijwel gegarandeerd dat de tool gebruikt wordt.
MCP Script – PDF vision read #
In LM studio kan je PDF bestanden laten analyseren die een tekst stream hebben, vaak zijn dit PDF bestanden waar je de tekst zelf kan selecteren en kopieren, zie onder voor het voorbeeld:
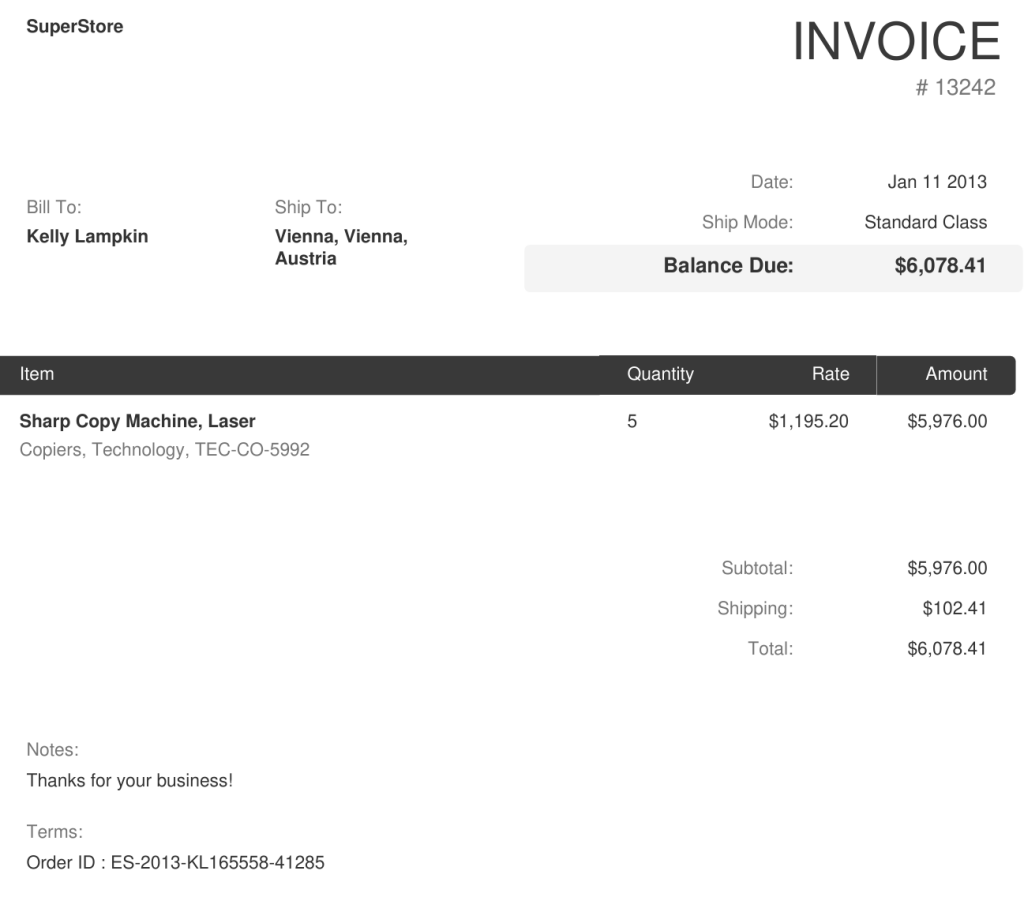
Ik heb even op internet rondgespeurd en zag hier wat voorbeeld facturen staan: https://github.com/femstac/Sample-Pdf-invoices
Ik heb daarvan een willekeurige PDF gepakt:
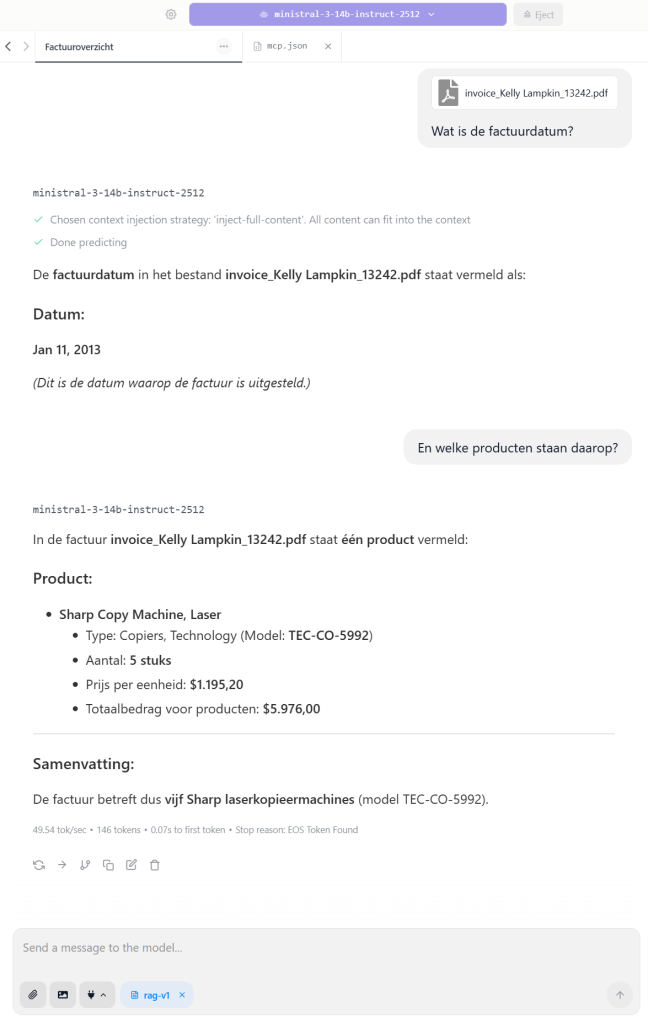
Dit type PDF kan je als bijlage in LM studio toevoegen en vragen over stellen:
Een LLM met “vision” ondersteuning kan afbeeldingen (PNG/JPG) analyseren, maar geen gescande PDF bestanden, je krijgt dan veelal dezelfde reactie terug:
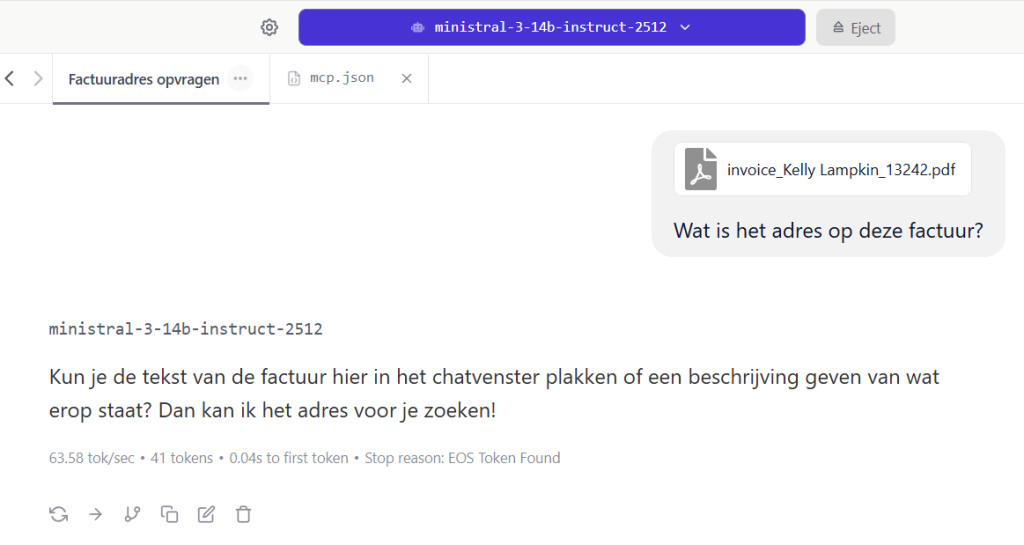
of:
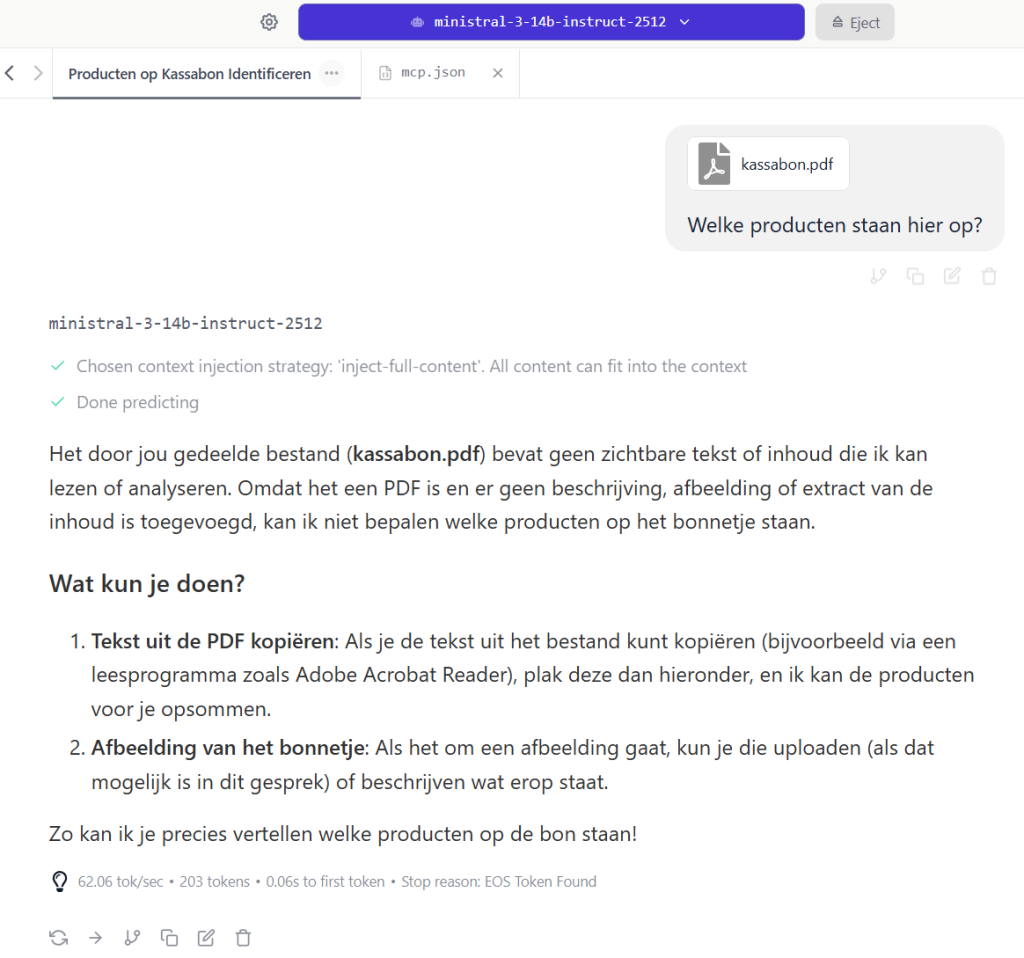
Het idee wat ik heb is om PDF bestanden om te zetten in PNG/JPG bestanden en dan door te zetten naar de LLM, zodat je via LM studio PDF bestanden kan laten analyseren.
Ik heb samen met ChatGPT dit LM Studion MCP script in elkaar gezet en gefinetuned.
Maak een map aan (bv c:\lmstudio-tools\pdf-read) en plaats de inhoud hieronder in een bestand genaamd pdf-read.py.
import sys
import json
import base64
import shutil
import subprocess
import tempfile
import hashlib
import urllib.request
from pathlib import Path
from typing import Optional, List, Dict, Any
# ============================================================
# MCP TOOL: PDF -> images -> LM Studio Vision -> RAW tekst
#
# Doel:
# - Gebruiker vraagt “wat staat er in PDF?”
# - Tool rendert (pdftoppm.exe) PDF pagina’s naar PNG/JPG
# - Tool stuurt de image(s) via LM Studio lokale API (/v1/chat/completions)
# - Tool retourneert 1-op-1 de backend output (verbatim) + SHA256 hash
#
# Waarom hash?
# - De host-LLM (AnythingLLM/n8n/etc.) kan tool output alsnog parafraseren.
# - Met SHA256 kun je verifiëren dat de tekst NIET is aangepast.
# ============================================================
TOOL_NAME = "pdf_vision_read"
# --- Local binary support (no PATH needed) ---
SCRIPT_DIR = Path(__file__).resolve().parent
LOCAL_PDFTOPPM = SCRIPT_DIR / "bin/pdftoppm.exe" # zet pdftoppm.exe naast dit script
# --- LM Studio defaults (bovenin instelbaar) ---
LMSTUDIO_API_URL = "http://localhost:1234" # pas aan als je server elders draait (bijv. http://192.168.2.28:1234)
LLM_VISION = "ministral-3-14b-instruct2512" # default model-id (LET OP: moet vision-capable zijn voor images)
def send(msg: dict) -> None:
# ensure_ascii=True voorkomt Windows cp1252 Unicode crashes
sys.stdout.write(json.dumps(msg, ensure_ascii=True) + "\n")
sys.stdout.flush()
def is_notification(req: dict) -> bool:
return "id" not in req or req.get("id") is None
def normalize_path(p: str) -> str:
# Maakt Windows paden ook bruikbaar in sommige hosts; laat drive letters intact.
return p.replace("\\", "/")
def b64_data_url(mime: str, p: Path) -> str:
data = p.read_bytes()
return f"data:{mime};base64," + base64.b64encode(data).decode("utf-8")
def sha256_text(s: str) -> str:
return hashlib.sha256(s.encode("utf-8")).hexdigest()
def infer_mime(img_format: str) -> str:
return "image/png" if img_format == "png" else "image/jpeg"
def find_pdftoppm() -> Path:
"""
Zoek pdftoppm.exe eerst naast het script, daarna in PATH.
"""
if LOCAL_PDFTOPPM.exists():
return LOCAL_PDFTOPPM
p = shutil.which("pdftoppm") or shutil.which("pdftoppm.exe")
if p:
return Path(p)
raise FileNotFoundError(
"pdftoppm.exe niet gevonden. Zet 'pdftoppm.exe' naast dit script "
"of installeer Poppler/Xpdf en zet het in PATH."
)
def run_pdftoppm(
pdftoppm_exe: Path,
pdf_path: Path,
out_prefix: Path,
dpi: int,
img_format: str,
first_page: Optional[int] = None,
last_page: Optional[int] = None,
) -> None:
# pdftoppm -png|-jpeg -r dpi [-f N] [-l N] input.pdf outprefix
args: List[str] = []
if img_format == "png":
args += ["-png"]
elif img_format == "jpg":
args += ["-jpeg"]
else:
raise ValueError("img_format must be 'png' or 'jpg'")
args += ["-r", str(dpi)]
if first_page is not None:
args += ["-f", str(first_page)]
if last_page is not None:
args += ["-l", str(last_page)]
args += [str(pdf_path), str(out_prefix)]
subprocess.run(
[str(pdftoppm_exe), *args],
check=True,
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL,
)
def collect_outputs(tmpdir: Path, base: str, img_format: str) -> List[Path]:
ext = ".png" if img_format == "png" else ".jpg"
files = sorted(tmpdir.glob(f"{base}-*{ext}"))
def page_num(p: Path) -> int:
# base-12.png -> 12
try:
return int(p.stem.split("-")[-1])
except Exception:
return 10**9
return sorted(files, key=page_num)
def lmstudio_vision_call(
base_url: str,
model: str,
prompt: str,
image_data_urls: List[str],
temperature: float = 0.0,
timeout_s: int = 180,
) -> Dict[str, Any]:
"""
Roept LM Studio OpenAI-compatible endpoint aan:
POST {base_url}/v1/chat/completions
Retourneert de volledige JSON response (zodat je ook later metadata kunt loggen).
"""
base_url = base_url.rstrip("/")
content: List[Dict[str, Any]] = [{"type": "text", "text": prompt}]
for url in image_data_urls:
content.append({"type": "image_url", "image_url": {"url": url}})
payload = {
"model": model,
"messages": [{"role": "user", "content": content}],
"temperature": float(temperature),
}
req = urllib.request.Request(
base_url + "/v1/chat/completions",
data=json.dumps(payload).encode("utf-8"),
headers={"Content-Type": "application/json"},
method="POST",
)
with urllib.request.urlopen(req, timeout=timeout_s) as r:
raw = r.read().decode("utf-8")
return json.loads(raw)
def safe_int(x: Any, default: int) -> int:
try:
return int(x)
except Exception:
return default
def sanitize_pages(pages: Any) -> Optional[List[int]]:
"""
Accepteert bijv [1,3,4]; filtert <1 eruit; maakt unique + sorted.
"""
if pages is None:
return None
try:
out = sorted(set(int(p) for p in pages if int(p) >= 1))
return out or None
except Exception:
return None
# ========== HOOFDLOOP ==========
for line in sys.stdin:
line = line.strip()
if not line:
continue
try:
req = json.loads(line)
except Exception:
continue
method = req.get("method")
req_id = req.get("id")
params = req.get("params") or {}
# ===== Handshake: initialize =====
if method == "initialize":
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"protocolVersion": "2024-11-05",
"serverInfo": {"name": "pdf-vision-read", "version": "3.0.1"},
"capabilities": {"tools": {"listChanged": False}},
},
}
)
# ===== Notification: initialized =====
elif method == "initialized":
continue
# ===== tools/list =====
elif method == "tools/list":
if is_notification(req):
continue
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"tools": [
{
"name": TOOL_NAME,
"title": "PDF → images → LM Studio Vision (verbatim output)",
"description": (
"Zet een PDF om naar afbeeldingen (PNG/JPG) en laat een lokaal vision-model "
"in LM Studio de inhoud lezen via de API. Retourneert de RAW model-output "
"(verbatim) + SHA256 hash om 1-op-1 doorgeven te kunnen verifiëren."
),
"inputSchema": {
"type": "object",
"properties": {
"pdf_path": {
"type": "string",
"description": "Pad naar PDF op schijf (Windows of Linux pad).",
},
"dpi": {
"type": "integer",
"description": "Render resolutie (200-300 meestal goed).",
"default": 250,
},
"format": {
"type": "string",
"description": "Afbeeldingsformaat: 'png' of 'jpg'.",
"default": "png",
"enum": ["png", "jpg"],
},
"pages": {
"type": "array",
"description": "Optioneel: specifieke pagina's (1-based), bijv. [1,3,4].",
"items": {"type": "integer"},
},
"max_pages": {
"type": "integer",
"description": "Als 'pages' niet is opgegeven: verwerk de eerste N pagina's.",
"default": 2,
},
# Optioneel: je kunt dit nog steeds per-call overriden, maar hoeft niet.
# Laat je dit weg, dan gebruiken we LMSTUDIO_API_URL bovenin.
"lmstudio_base_url": {
"type": "string",
"description": "LM Studio server base URL (OpenAI-compatible).",
"default": LMSTUDIO_API_URL,
},
# Optioneel: je kunt dit nog steeds per-call overriden, maar hoeft niet.
# Laat je dit weg, dan gebruiken we LLM_VISION bovenin.
"vision_model": {
"type": "string",
"description": (
"Vision model-id zoals LM Studio het kent. "
"Laat leeg om de default (LLM_VISION) bovenin te gebruiken."
),
"default": LLM_VISION,
},
"prompt": {
"type": "string",
"description": (
"Prompt voor het vision-model. Tip: zet 'Alleen wat zichtbaar is; "
"als iets onleesbaar is: zeg onleesbaar; verzin niets.'"
),
"default": (
"Lees de afbeelding(en) en beschrijf ALGEMEEN wat er in de PDF staat. "
"Noem alleen wat zichtbaar is. Als tekst onleesbaar is, zeg 'onleesbaar'. "
"Verzin niets."
),
},
"temperature": {
"type": "number",
"description": "Temperatuur voor de vision-call (0 = zo deterministisch mogelijk).",
"default": 0,
},
},
# vision_model is nu NIET meer required, want we hebben LLM_VISION bovenin
"required": ["pdf_path"],
},
}
]
},
}
)
# ===== tools/call =====
elif method == "tools/call":
if is_notification(req):
continue
tool_name = params.get("name")
arguments = params.get("arguments") or {}
if tool_name != TOOL_NAME:
send(
{
"jsonrpc": "2.0",
"id": req_id,
"error": {"code": -32602, "message": f"Unknown tool: {tool_name}"},
}
)
continue
pdf_path_raw = str(arguments.get("pdf_path", "")).strip()
dpi = safe_int(arguments.get("dpi", 250), 250)
img_format = str(arguments.get("format", "png")).lower().strip()
max_pages = safe_int(arguments.get("max_pages", 2), 2)
pages = sanitize_pages(arguments.get("pages", None))
# Als host niets meegeeft, pakken we defaults bovenin.
lmstudio_base_url = str(arguments.get("lmstudio_base_url", LMSTUDIO_API_URL)).strip() or LMSTUDIO_API_URL
vision_model = str(arguments.get("vision_model", LLM_VISION)).strip() or LLM_VISION
# Prompt: als leeg, terugvallen op dezelfde default als in tools/list.
default_prompt = (
"Lees de afbeelding(en) en beschrijf ALGEMEEN wat er in de PDF staat. "
"Noem alleen wat zichtbaar is. Als tekst onleesbaar is, zeg 'onleesbaar'. "
"Verzin niets."
)
prompt = str(arguments.get("prompt", default_prompt)).strip() or default_prompt
temperature = float(arguments.get("temperature", 0.0))
if not pdf_path_raw:
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"content": [{"type": "text", "text": "Fout: pdf_path ontbreekt."}],
"isError": True,
},
}
)
continue
pdf_path = Path(normalize_path(pdf_path_raw))
if not pdf_path.exists():
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"content": [{"type": "text", "text": f"Fout: PDF niet gevonden: {pdf_path_raw}"}],
"structuredContent": {"pdf_path": pdf_path_raw},
"isError": True,
},
}
)
continue
if img_format not in ("png", "jpg"):
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"content": [{"type": "text", "text": "Fout: format moet 'png' of 'jpg' zijn."}],
"isError": True,
},
}
)
continue
if dpi < 72:
dpi = 72
if dpi > 600:
dpi = 600
if max_pages < 1:
max_pages = 1
if max_pages > 20:
# harde cap om gigantische PDFs niet per ongeluk te slopen
max_pages = 20
# Resolve pdftoppm executable (local first, then PATH)
try:
pdftoppm_exe = find_pdftoppm()
except Exception as e:
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"content": [{"type": "text", "text": f"Fout: {e}"}],
"structuredContent": {"pdf_path": pdf_path_raw},
"isError": True,
},
}
)
continue
# Render + vision
try:
with tempfile.TemporaryDirectory(prefix="pdf2vision-") as td:
tmpdir = Path(td)
base = "page"
out_prefix = tmpdir / base
mime = infer_mime(img_format)
# 1) PDF -> images
if pages is None:
# Eerste N pagina's in één run (sneller)
run_pdftoppm(
pdftoppm_exe,
pdf_path,
out_prefix,
dpi,
img_format,
first_page=1,
last_page=max_pages,
)
outputs = collect_outputs(tmpdir, base, img_format)
else:
# Specifieke pagina's: render per pagina (simpel + voorspelbaar)
outputs = []
for pno in pages:
run_pdftoppm(pdftoppm_exe, pdf_path, out_prefix, dpi, img_format, pno, pno)
ext = ".png" if img_format == "png" else ".jpg"
f = tmpdir / f"{base}-{pno}{ext}"
if f.exists():
outputs.append(f)
if not outputs:
raise RuntimeError("Geen pagina's gerenderd (output leeg).")
# 2) images -> data URLs (base64) voor LM Studio
image_data_urls: List[str] = []
rendered_pages: List[int] = []
for f in outputs:
pno = int(f.stem.split("-")[-1])
rendered_pages.append(pno)
image_data_urls.append(b64_data_url(mime, f))
# 3) LM Studio vision call
lm_resp = lmstudio_vision_call(
base_url=lmstudio_base_url,
model=vision_model,
prompt=prompt,
image_data_urls=image_data_urls,
temperature=temperature,
timeout_s=180,
)
# 4) RAW tekst eruit trekken (verbatim)
lm_text = (
lm_resp.get("choices", [{}])[0]
.get("message", {})
.get("content", "")
)
if not isinstance(lm_text, str):
lm_text = str(lm_text)
lm_hash = sha256_text(lm_text)
# Let op: structuredContent bevat de raw text ook (handig voor host tooling),
# maar sommige hosts tonen liever de "content" in UI.
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
# In content zetten we expliciet verbatim output (zodat het zichtbaar is),
# plus hash voor verificatie.
"content": [
{
"type": "text",
"text": (
"=== LM STUDIO RAW OUTPUT (verbatim) ===\n"
f"{lm_text}\n\n"
"=== SHA256 ===\n"
f"{lm_hash}"
),
}
],
"structuredContent": {
"pdf_path": pdf_path_raw,
"dpi": dpi,
"format": img_format,
"rendered_pages": rendered_pages,
"lmstudio": {
"base_url": lmstudio_base_url,
"vision_model": vision_model,
"temperature": temperature,
},
"lm_raw_text": lm_text,
"lm_raw_sha256": lm_hash,
"debug": {
"pdftoppm_exe": str(pdftoppm_exe),
"local_pdftoppm_exists": LOCAL_PDFTOPPM.exists(),
},
},
"isError": False,
},
}
)
except urllib.error.HTTPError as e:
# LM Studio endpoint gaf HTTP error; lees body (als die er is) voor debug.
try:
body = e.read().decode("utf-8", errors="replace")
except Exception:
body = ""
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"content": [
{
"type": "text",
"text": f"Fout bij LM Studio API call: HTTP {e.code} {e.reason}\n{body}",
}
],
"structuredContent": {
"pdf_path": pdf_path_raw,
"lmstudio_base_url": lmstudio_base_url,
"vision_model": vision_model,
},
"isError": True,
},
}
)
except Exception as e:
send(
{
"jsonrpc": "2.0",
"id": req_id,
"result": {
"content": [{"type": "text", "text": f"Fout: {e}"}],
"structuredContent": {
"pdf_path": pdf_path_raw,
"dpi": dpi,
"format": img_format,
"pages": pages,
"max_pages": max_pages,
"lmstudio_base_url": lmstudio_base_url,
"vision_model": vision_model,
"debug": {"pdftoppm_exe": str(pdftoppm_exe)},
},
"isError": True,
},
}
)
else:
if is_notification(req):
continue
send(
{
"jsonrpc": "2.0",
"id": req_id,
"error": {"code": -32601, "message": f"Unknown method: {method}"},
}
)Instellingen van het script #
Vergeet niet boven in het blok eventuele variabelen naar eigen omgeving aan te passen:
# --- Local binary support (no PATH needed) ---
SCRIPT_DIR = Path(__file__).resolve().parent
LOCAL_PDFTOPPM = SCRIPT_DIR / "bin/pdftoppm.exe" # zet pdftoppm.exe naast dit script
# --- LM Studio defaults (bovenin instelbaar) ---
LMSTUDIO_API_URL = "http://localhost:1234" # pas aan als je server elders draait (bijv. http://192.168.2.28:1234)
LLM_VISION = "ministral-3-14b-instruct2512" # default model-id (LET OP: moet vision-capable zijn voor images)Overige niet instelbare UI instellingen #
Je ziet instellingen staan in het script, echter zie je deze instellingen NIET als “klikbare instellingen” in LM Studio.
Waar “bestaan” deze instellingen dan?
Dit stuk:
"dpi": {
"type": "integer",
"default": 300
},
"format": {
"type": "string",
"default": "png",
"enum": ["png", "jpg"]
}zit in de inputSchema van je MCP tool.
Dat schema wordt:
- niet als UI-formulier getoond
- wél gelezen door het model
- gebruikt door de tool-calling logica
Dus:
- LM Studio UI → ziet het niet
- LLM → ziet het wél (impliciet)
Hoe gebruikt het model deze defaults? #
Als het model besluit de tool aan te roepen, gebeurt dit:
Zonder expliciete parameters
Gebruiker:
“Lees deze PDF”
Model → tool call (intern):
{
"name": "pdf_to_images",
"arguments": {
"pdf_path": "c:/docs/test.pdf"
}
}Omdat dpi en format defaults hebben:
dpi = 300format = "png"
De tool vult dat zelf in.
Hoe kan jij ze beïnvloeden als gebruiker? #
Optie A — via je prompt (meest gebruikt)
Je zegt het in tekst, het model vertaalt dat naar tool-arguments:
“Lees de PDF in hoge resolutie (300 DPI) en gebruik PNG.”
Model → tool call:
{
"pdf_path": "c:/docs/test.pdf",
"dpi": 300,
"format": "png"
}
Dit is de bedoelde workflow.
Optie B — via system prompt (aanrader)
In je system prompt (of tool instructions):
“Gebruik standaard 300 DPI voor PDF-afbeeldingen. Verlaag naar 200 DPI als snelheid belangrijker is.”
Dan zal het model:
- automatisch
dpi=300kiezen - tenzij de gebruiker iets anders vraagt
Waarom LM Studio geen UI toont (bewust ontwerp) #
LM Studio:
- is model-centric
- niet “tool-form-centric”
Tools zijn bedoeld als:
“extensies van het model, niet van de UI”
Daarom:
- geen sliders
- geen dropdowns
- geen formulier
Het model is de UI.
Hoe zie je wél wat het model heeft gekozen? #
In LM Studio:
- zet verbose / tool logging aan
- dan zie je de tool call JSON
Je ziet dan letterlijk:
"arguments": {
"pdf_path": "...",
"dpi": 300,
"format": "png"
}Samenvatting
- Geen UI-instellingen in LM Studio
inputSchemais voor het model- defaults worden automatisch gebruikt
- gebruiker beïnvloedt het via tekst
- jij stuurt gedrag via system prompt
Nadat je dit bestand hebt aangemaakt moeten we in LM studio nog vertellen waar hij staat doormiddel mcp.json te bewerken.
Voeg dit script toe aan bv je bestaande configuratie met “date-time”:
{
"mcpServers": {
"date-time": {
"command": "python",
"args": [
"c:/lmstudio-tools/date-time/date-time.py"
]
},
"pdf-read": {
"command": "python",
"args": [
"c:/lmstudio-tools/pdf-read/pdf-read.py"
]
}
}
}Nadat je het script hebt opgeslagen moeten we nog de tool pdftoppm.exe installeren, dat een onderdeel van de poppler tools.
Je vind deze tools hier: https://github.com/oschwartz10612/poppler-windows
Download: https://github.com/oschwartz10612/poppler-windows/releases
pak de bin folder uit het ZIP bestand (..\poppler-25.12.0\Library\bin\) en plaats de bin folder met de gehele inhoud in “c:\lmstudio-tools\pdf-read\bin“,
zodat het bestand pdftoppm.exe nu staat in “c:\lmstudio-tools\pdf-read\bin\pdftoppm.exe“
PDF read testen #
Let op: LM Studio ondersteunt nog geen MCP tools die bijlages vanuit de UI kunnen lezen:

je zal dus moeten verwijzen naar het pad en bestand van de PDF, voorbeeld:
Ps. vergeet niet de MCP PDF tool aan te zetten met toestemmingen voor het uitvoeren!
Zoals je ziet werkt het aardig, het is niet perfect, maar het komt ene heel eind!