Knowledge Center
OCR met OnnxTR (Linux/WSL python)
Intro #
Met het onderstaande voorbeeld is het mogelijk een PDF/afbeelding naar tekst om te zetten, welllicht ken je al sommige tools die PDF naar TXT conversie doen, zoals
Website: https://www.xpdfreader.com/download.html
Maar… dit zijn PDF’s waarbij de tekst ingesloten (embedded) is, veelal kan je in deze documenten ook tekst selecteren en kopiëren als je deze PDF bestanden opent. Deze PDF bestanden zijn dan ook kleiner dan zelf gescande documenten.
Maar heb je PDF bestanden waarbij de pagina’s als afbeeldingen ingesloten zitten, dan kan je geen tekst selecteren, kopiëren of extraheren.
In dit voorbeeld hieronder gebruiken we Linux/WSL met python om met een OCR programma tekst de extraheren van een (image)PDF
Wat is OCR?
OCR, wat staat voor Optische Tekenherkenning (Engels: Optical Character Recognition), is een technologie die afbeeldingen van tekst (zoals gescande documenten, foto’s of PDF’s) omzet in machinaal leesbare en bewerkbare digitale tekst. Hierdoor kunnen computers de tekst begrijpen, verwerken en archiveren, wat handig is voor het digitaliseren van papierwerk, het zoeken in documenten en het automatiseren van administratieve processen
OnnxTR #
Introduction #
What you can expect from this repository:
- 8-Bit quantized models for faster inference on CPU
- efficient ways to parse textual information (localize and identify each word) from your documents
- a Onnx pipeline for docTR, a wrapper around the doctr library – no PyTorch or TensorFlow dependencies
- more lightweight package with faster inference latency and less required resources
Github: https://github.com/felixdittrich92/OnnxTR?tab=readme-ov-file
Huggingface: https://huggingface.co/Felix92/onnxtr-fast-base
DocTR #
Op de github van ONNXTR staat:
Please note that this is a wrapper around the doctr library to provide a Onnx pipeline for docTR. For feature requests, which are not directly related to the Onnx pipeline, please refer to the base project.
Github: https://github.com/mindee/doctr
Optical Character Recognition made seamless & accessible to anyone, powered by PyTorch
What you can expect from this repository:
- efficient ways to parse textual information (localize and identify each word) from your documents
Wat doet OnnxTR dan? #
OnnxTR = een wrapper die docTR-modellen als ONNX uitvoert.
Het doet niet hetzelfde werk als docTR.
Het doet:
Verteert ONNX-modellen van docTR #
Het bevat voor elk model:
- ONNX-file
- Preprocessing
- Postprocessing
- Tokenization / vocabs
Biedt een API die lijkt op docTR #
Bijv.:
from onnxtr.models import ocr_predictor
predictor = ocr_predictor(det_arch="fast_base", reco_arch="vitstr_base")Maar intern draait:
- geen PyTorch
- geen GPU logic
- alleen onnxruntime.
Voegt toe #
- Snellere CPU inference
- Minder dependencies
- Geen Torch nodig
- Geen CUDA nodig
- Offline modellen
- Kleine runtime footprint
Wat OnnxTR niet doet #
- Geen training
- Geen nieuwe modellen aanmaken
- Geen complexe layout-pipelines zoals docTR
- Geen GPU acceleration zoals docTR met PyTorch
Samengevat:
docTR = complete OCR suite, PyTorch-based.
OnnxTR = lichtgewicht ONNX-inference versie van docTR-modellen.
Conclusie #
| Eigenschap | docTR | OnnxTR |
|---|---|---|
| Framework | ✔ volledig | ✖ inferentie-only |
| Modellen | PyTorch | ONNX |
| Training | ✔ | ✖ |
| GPU support | ✔ (CUDA, Torch) | gedeeltelijk (onnxruntime GPU) |
| CPU performance | minder | sneller |
| Installatiegrootte | groot | klein |
| Offline | ✔ | ✔✔ (zeer geschikt) |
| Layout features | uitgebreider | basis OCR |
docTR is de bron. OnnxTR is de portable, snelle, ONNX-versie daarvan.
Voorbereiding (Linux / WSL) #
WSL #
WSL is een (ubuntu) Linux omgeving in Windows, deze kan men installeren via de APP store.
Zit je in een (verse) WSL prompt dan moet men eerst nog PIP (python package manager) en VENV (python virtual environment) installeren:
sudo apt install -y python3-pip python3-venvVENV aanmaken #
Python werkt tegenwoordig met virtual environments om conflicten met bibliotheken tegen te gaan en uit te sluiten.
Maak een virtual environment aan met het commando:
python3 -m venv ~/venven activeer deze:
source ~/venv/bin/activatePython bibliotheken #
Eenmaal binnen je VENV installeer de volgende bibliotheken.
pip3 install onnxruntime onnxtr[cpu-headless] df2image pillowOf onnxtr met GPU mogelijkheden:
pip3 install onnxruntime onnxtr[gpu-headless] df2image pillowNodig voor pdf2image
sudo apt-get install -y poppler-utilsHet model downloaden #
Het model staat hier: https://huggingface.co/Felix92/onnxtr-fast-base/tree/main
Maar je kan niet de bestanden downloaden, in een folder zetten en aanroepen via een script, want er worden door Onnx runtime ook bepaalde configuraties geladen, deze zitten dat hardcoded ingebouwd en zijn NAAM afhankelijk (dus als je bijvoorbeeld ald model opgeeft “~/ocr-model/model.onnx” dan wordt de juiste configuratie niet geladen!
De beste oplossing is dat het het script met onnx runtime de modellen laat downloaden vanaf internet, bijvoorbeeld:
Downloading https://github.com/felixdittrich92/OnnxTR/releases/download/v0.0.1/rep_fast_base-1b89ebf9.onnx to /home/phoenix/.cache/onnxtr/models/rep_fast_base-1b89ebf9.onnx
42343424it [00:01, 23740132.93it/s]
Downloading https://github.com/felixdittrich92/OnnxTR/releases/download/v0.0.1/vitstr_base-ff62f5be.onnx to /home/phoenix/.cache/onnxtr/models/vitstr_base-ff62f5be.onnx
341380096it [00:17, 20054615.57it/s]De bestanden worden dan geplaats in de onnx .cache folder, deze kan je dus wel kopiëren en plakken in een volgende installatie, en zijn dus offline te houden, als ze maar in die onnx .cache map staan met dezelfde bestandsnaam (met hash), voorbeeld:
~\.cache\onnxtr\models\vitstr_base-ff62f5be.onnx
~\.cache\onnxtr\models\rep_fast_base-1b89ebf9.onnxps je kan gemakkelijk via de Windows explorer naar de WSL home folder:
\\wsl.localhost\Ubuntu\home\(en dan door naar de map van de gebruiker van het systeem)
Waarom werken losse ONNX-paden niet in OnnxTR? #
OnnxTR koppelt niet alleen het ONNX-model, maar een volledige architectuur
Wanneer je doet:
det_arch="fast_base"Laadt OnnxTR niet alleen een ONNX-model.
Hij laadt:
- de ONNX-file
- de juiste input-preprocessing
- de mean/std normalisatie
- de input-size (1024×1024)
- de output layout
- de modelcategorie (detector / recognizer)
- de postprocessing-code
- de polygon extractor settings
- thresholds (box_thresh, bin_thresh)
- batching info
- enz…
→ Dit staat allemaal in de arch-registry, die intern zoiets is:
{
"fast_base": {
"url": "...onnx",
"mean": [...],
"std": [...],
"input_shape": [3,1024,1024],
"task": "detection",
"postprocessor": FastBasePostProcessor(...),
...
},
...
}Let op: Dat dictionary zit hardcoded in de Python source, niet in JSON.
Daarom begrijpt OnnxTR niet wat dit is:
det_arch = "/path/model.onnx"Het denkt:
“Dit is een string → dit moet een arch-naam zijn → ik zoek in de registry → niet gevonden → fout.”
Het ONNX-bestand zelf bevat niet genoeg informatie
Een .onnx bestand bevat:
- alleen het model (gewichten + graph)
- geen vocab
- geen mean/std
- geen input resolution
- geen postprocessing parameters
- geen documentlayout logica
Dat zit nooit in ONNX zelf — altijd extern.
OnnxTR wil niet dat jij zelf gaat gokken, dus ze eisen:
- óf een arch-naam die bekend is in hun registry
- óf een helper zoals
parseq()waar jij handmatig vocab en input_size meegeeft
Maar voor VITSTR-modellen bestaat zo’n helper (nog) niet.
Veel OnnxTR-modellen hebben specifieke postprocessing
Bijvoorbeeld:
- DBNet/RepDB (fast_base) vereist contour-tracing
- VITSTR moet CTC/Seq2Seq decoding doen
- PARSeq gebruikt een Transformer-output met speciale maskers
- CRNN gebruikt CTC decoding
Dit moet exact passen bij de architectuur.
Een ONNX-file koppelen zonder de juiste “arch type” leidt vrijwel altijd tot crashes of verkeerde resultaten.
Detector en Recognizer #
OCR (Optical Character Recognition) bestaat standaard uit:
- Text Detection → waar staat tekst in het beeld?
- Text Recognition → wat staat er? (letters, woorden, zinnen)
onnxtr-fast-base is alleen het detectie-model.
Je hebt altijd óók een recognition model nodig bv:
vitstr_base.onnxvitstr_small.onnxparseq_base.onnxparseq_multilingual_v1.onnx
(vitstr is een Vision Transformer Sequence Recognizer)
Detector “Waar zit tekst in de afbeelding?”
Het detectiemodel zoekt rechthoeken, tekstlijnen, blokken, paragrafen, bijvoorbeeld:
____________________________
| _____ ________ |
| |HELLO| |WORLD | |
| |_____| |_______| |
|____________________________|De detector produceert zoiets als:
Box1: [x1, y1, x2, y2]
Box2: [x1, y1, x2, y2]
...Met andere woorden: De locaties waar tekst staat.
Voorbeelden van detectie-modellen:
onnxtr-fast-baserep_fast_basecraftdbnet
Een detector leest geen tekst. Het vindt alleen gebieden met tekst.
Recognizer “Welke letters / woorden staan in dat vakje?”
De recognizer neemt een uitgesneden stuk van de afbeelding uit de detector en doet:
[ afbeelding van "HELLO" ] → "HELLO"
[ afbeelding van "WORLD" ] → "WORLD"Het is een sequence-model dat karakters herkent en tekst teruggeeft.
Voorbeelden van recognizers:
vitstr_baseparseq_baseparseq_multilingualcrnn
Een recognizer kan geen tekst vinden , hij moet een stuk tekst krijgen van de detector.
Hoe werkt OCR in OnnxTR? #
- Detector vindt tekstblokken →
[(box1), (box2), ...] - Elk blok wordt uitgesneden
- Recognizer leest het uitgesneden stuk
- Alles wordt samengevoegd tot zinnen / paragrafen
Zonder detector → recognizer krijgt geen regio → werkt niet
Zonder recognizer → detector weet niet wat er staat → werkt niet
Daarom kun je niet slechts één ONNX-bestand gebruiken voor volledige OCR.
Onnx gebruiken en testen #
Hier staat een PDF bestand om het OCR script mee te testen, hernoem het naar document.pdf
https://bytescout-com.s3-us-west-2.amazonaws.com/files/demo-files/cloud-api/pdf-make-searchable/sample.pdf
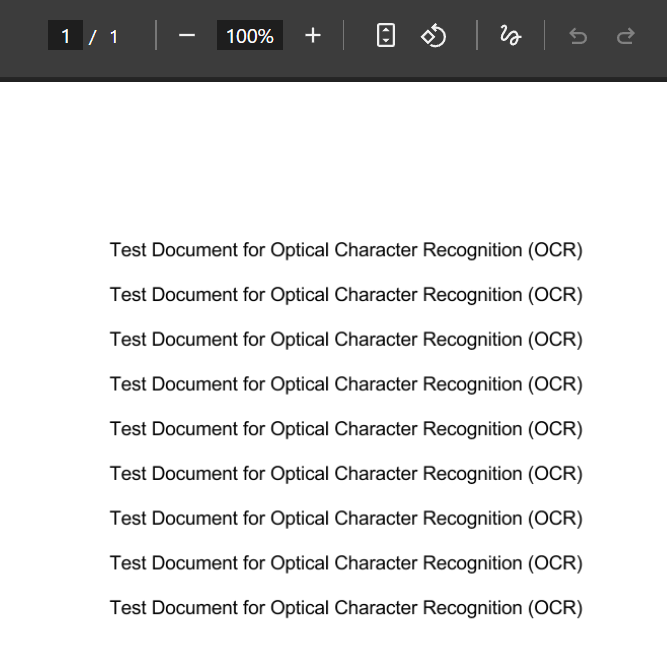
Hier volgt het minimale basisvoorbeeld in python, het print de tekst die staat in “document.pdf” in de console:
from onnxtr.io import DocumentFile
from onnxtr.models import ocr_predictor
# 1) Laad je PDF
doc = DocumentFile.from_pdf("document.pdf")
# 2) Maak een OCR-predictor
# 'fast_base' = detectie
# 'vitstr_base' = herkenning
predictor = ocr_predictor(
det_arch="fast_base",
reco_arch="vitstr_base",
)
# 3) Run OCR
result = predictor(doc)
# 4) Gewoon alle tekst als string
text = result.render() # human readable tekst :contentReference[oaicite:3]{index=3}
print(text)
Output:
Test Document for Optical Character Recognition (OCR)
Test Jocument for Optical Character Recognition (OCR)
Test Document for Optical Character Recognition (OCR)
Test Document for Optical Character Recognition (OCR)
Test Document for Optical Character Recognition (OCR)
Test Document for Optical Character Recognition (OCR)
Test Document for Optical Character Recognition (OCR)
Test Document for Optical Character Recognition (OCR)
Test Document for Optical Character Recognition (OCR)Script 2 – Pagina voor pagina #
Om alles in één keer te OCR’en heeft voor en nadelen:
Voordelen
- Simpel
- Snelste manier
Nadelen
- Houdt alle pagina’s tegelijk in RAM
- Grotere PDFs = snel 1–2 GB RAM nodig
- Slecht voor Jetson / low-memory machines
Voor kleinere (IOT) devices kan je er voor kiezen om elke pagina apart te OCR’en:
- PDF pagina’s één voor één renderen (niet alles in één DocumentFile houden)
- Elke pagina apart OCR’en
- Resultaat direct wegschrijven / opslaan
- Pagina weer uit het geheugen laten verdwijnen
Script om pagina voor pagina re behandelen:
from onnxtr.io import DocumentFile
from onnxtr.models import ocr_predictor
# 1) Laad de hele PDF
doc = DocumentFile.from_pdf("document.pdf")
# 2) Maak de OCR-predictor
predictor = ocr_predictor(
det_arch="fast_base",
reco_arch="vitstr_base",
)
# 3) OCR draaien op alle pagina's
result = predictor(doc)
# 4) Exporteren naar een dictionary
ocr = result.export()
pages_text = []
for i, page in enumerate(ocr["pages"]):
lines_out = []
for block in page["blocks"]:
for line in block["lines"]:
words = [w["value"] for w in line["words"]]
if words:
lines_out.append(" ".join(words))
page_text = "\n".join(lines_out)
print(f"=== Pagina {i + 1} ===")
print(page_text)
print()
pages_text.append(page_text)
# Als je alles als één grote string wilt:
fulltext = "\n\n".join(pages_text)Kiezen voor een kleiner model #
Ps. Je kan ook voor een kleiner model kiezen: vitstr_small (ca. 80MB) , deze werkt ook aardig goed en is prima te gebruiken op kleinere (IOT) apparaten.
Script 3 – bestand en OCR engine #
Hieronder staat een script waarbij je zowel het document als OCR engine kan kiezen, gebruik als voorbeeld:
python3 ocr_test.py document.pdf vitstr_small#!/usr/bin/env python3
import sys
import os
from typing import List, Tuple
from onnxtr.io import DocumentFile
from onnxtr.models import ocr_predictor
def ocr_pdf_sorted(pdf_path: str,
det_arch: str = "fast_base",
reco_arch: str = "vitstr_base") -> str:
"""
OCR een PDF met OnnxTR en sorteer tekstblokken op positie.
- Geen layout-AI, dus geen kwaliteitsverlies door extra raster/PNG.
- Blokken worden gesorteerd op (y, x) zodat de volgorde logischer is.
"""
if not os.path.isfile(pdf_path):
raise FileNotFoundError(f"PDF niet gevonden: {pdf_path}")
# 1) PDF → OnnxTR-document
doc = DocumentFile.from_pdf(pdf_path)
# 2) OCR-model
predictor = ocr_predictor(
det_arch=det_arch,
reco_arch=reco_arch,
)
result = predictor(doc)
pages_out: List[str] = []
for page_idx, page in enumerate(result.pages, start=1):
blocks: List[Tuple[float, float, str]] = []
for block in page.blocks:
# geometry: ((x_min, y_min), (x_max, y_max)) in genormaliseerde 0–1 coords
(x1, y1), (x2, y2) = block.geometry
# Tekst in dit blok opbouwen uit regels/woorden
lines_text: List[str] = []
for line in block.lines:
words = [w.value for w in line.words]
line_text = " ".join(words).strip()
if line_text:
lines_text.append(line_text)
text = "\n".join(lines_text).strip()
if text:
# sorteer straks eerst op y (verticaal), dan op x (horizontaal)
blocks.append((float(y1), float(x1), text))
# Blokken sorteren → boven-naar-beneden, links-naar-rechts
blocks.sort(key=lambda t: (t[0], t[1]))
page_text = "\n\n".join(b[2] for b in blocks)
pages_out.append(f"=== PAGINA {page_idx} ===\n{page_text}")
return "\n\n".join(pages_out)
def main():
if len(sys.argv) < 2:
print(f"Gebruik: {sys.argv[0]} <pdf-bestand> [reco_arch]", file=sys.stderr)
print(f"Voorbeeld: {sys.argv[0]} document.pdf vitstr_small", file=sys.stderr)
sys.exit(1)
pdf_path = sys.argv[1]
reco_arch = sys.argv[2] if len(sys.argv) >= 3 else "vitstr_base"
text = ocr_pdf_sorted(pdf_path, det_arch="fast_base", reco_arch=reco_arch)
print(text)
if __name__ == "__main__":
main()Detector output #
Ben je nieuwschierig hoe de output van de detector eruit ziet?, gebruik dan onderstaand script en verwijs het pad naar het juiste onnx bestand:
Download dit PNG plaatje:

Source: https://cran.r-project.org/web/packages/tesseract/vignettes/intro.html
Sla het op in de home folder als “testocr.png”, en start onderstaand script (ocr_test_detect.py):
import onnxruntime as ort
import numpy as np
from PIL import Image
# ---- jouw model ----
session = ort.InferenceSession(".cache/onnxtr/models/rep_fast_base-1b89ebf9.onnx")
# ---- afbeelding inladen ----
img = Image.open("testocr.png").convert("RGB")
# ---- preprocessing zoals OCR frameworks doen ----
# OnnxTR-detectiemodellen verwachten (1,3,H,W) normalized
img = img.resize((1024, 1024)) # maat hangt af van jouw model
arr = np.array(img).astype("float32") / 255.0
arr = np.transpose(arr, (2, 0, 1)) # HWC → CHW
arr = arr[np.newaxis, :, :, :] # batchdim toevoegen
# ---- inference ----
output = session.run(None, {"input": arr})
# Output bevat bounding boxes in raw model format
boxes = output[0]
print(boxes)Voorbeeld van de output:
[[[[-240.71274 -240.71274 -296.97015 ... -330.1418 -317.7854
-317.7854 ]
[-240.71274 -240.71274 -296.97015 ... -330.1418 -317.7854
-317.7854 ]
[-265.80328 -265.80328 -321.29807 ... -332.61163 -320.24966
-320.24966]
...
[-260.2138 -260.2138 -276.7591 ... -213.55493 -210.20093
-210.20093]
[-236.64815 -236.64815 -247.74678 ... -200.73361 -199.9515
-199.9515 ]
[-236.64815 -236.64815 -247.74678 ... -200.73361 -199.9515
-199.9515 ]]]]